
Maison >Java >javaDidacticiel >Comment résoudre la haute concurrence en Java ? Solution Java à haute concurrence
Comment résoudre la haute concurrence en Java ? Solution Java à haute concurrence

- 不言avant
- 2018-10-10 11:16:573113parcourir
Le contenu de cet article explique comment résoudre la concurrence élevée en Java ? La solution Java à haute concurrence a une certaine valeur de référence. Les amis dans le besoin peuvent s'y référer. J'espère qu'elle vous sera utile.
Pour le site Web que nous développons, si le site Web a un très grand nombre de visites, nous devons alors prendre en compte les problèmes d'accès simultanés associés. Les problèmes de concurrence sont un casse-tête pour la plupart des programmeurs.
Mais là encore, puisque nous ne pouvons pas y échapper, faisons-y face sereinement~ Étudions ensemble les problèmes courants aujourd'hui Concurrence et synchronisation.
Afin de mieux comprendre la simultanéité et la synchronisation, nous devons d'abord comprendre deux concepts importants : Synchronisation et asynchrone
1. et contactez
La soi-disant synchronisation peut être comprise comme l'attente que le système renvoie une valeur ou un message après l'exécution d'une fonction ou d'une méthode. À ce moment, le programme est bloqué et ne reçoit que
Exécutez d'autres commandes uniquement après avoir renvoyé la valeur ou le message. Asynchrone, après l'exécution de la fonction ou de la méthode, il n'est pas nécessaire d'attendre de manière bloquante la valeur de retour ou le message. Il vous suffit de déléguer un processus asynchrone au système. Ensuite, lorsque le système reçoit la valeur de retour ou. message, le système déclenchera automatiquement le processus asynchrone de délégation pour terminer un processus complet. La synchronisation peut être considérée dans une certaine mesure comme un thread unique. Une fois que ce thread aura demandé une méthode, il attendra que la méthode y réponde, sinon il ne poursuivra pas l'exécution (cœur mort). Asynchrone peut être considéré comme multi-threading dans une certaine mesure (absurdité, comment un thread peut-il être appelé asynchrone? Après avoir demandé une méthode, elle sera ignorée et continuera à exécuter d'autres méthodes). La synchronisation est une chose, effectuée une chose à la fois.Asynchrone signifie faire une chose sans provoquer d'autres choses.
La lecture non répétable fait référence à la lecture des mêmes données plusieurs fois au cours d'une transaction. Avant la fin de cette transaction, une autre transaction accède également aux mêmes données. Ensuite, entre les deux données lues lors de la première transaction, du fait de la modification de la deuxième transaction, les données lues deux fois par la première transaction peuvent être différentes. De cette façon, les données lues deux fois au sein d'une transaction sont différentes, elles sont donc appelées lecture non répétable
2. Comment gérer la concurrence et la synchronisationAujourd'hui, nous allons parler de comment La résolution des problèmes de concurrence et de synchronisation passe principalement par le mécanisme de verrouillage. Nous devons comprendre que le mécanisme de verrouillage a deux niveaux. L'un est au niveau du code, comme le verrou de synchronisation en Java. Le mot-clé de synchronisation typique est synchronisé. Je n'expliquerai pas trop ici L'autre est au niveau de la base de données. Les plus typiques sont le verrouillage pessimiste et le verrouillage optimiste. Nous nous concentrons ici sur le verrouillage pessimiste (verrouillage physique traditionnel) et le verrouillage optimiste.verrouillage pessimiste :
verrouillage pessimiste, comme son nom, il fait référence aux données des données (y compris d'autres transactions actuellement dans ce système, et au traitement des transactions à partir de systèmes externes. ) modification, donc , les données sont verrouillées pendant tout le processus de traitement des données.
La mise en œuvre du verrouillage pessimiste repose souvent sur le mécanisme de verrouillage fourni par la base de données (seul le mécanisme de verrouillage fourni par la couche base de données peut véritablement garantir l'exclusivité de l'accès aux données. Sinon, même si le mécanisme de verrouillage est implémenté dans ce système, il ne peut pas garantir que les systèmes externes ne modifieront pas les données).
Un appel de verrouillage pessimiste typique qui s'appuie sur la base de données :
Cette instruction SQL verrouille tous les enregistrements de la table des comptes qui répondent aux conditions de récupération (name="Erica").select * from account where name=”Erica” for update
本次事务提交之前(事务提交时会释放事务过程中的锁),外界无法修改这些记录。
Hibernate 的悲观锁,也是基于数据库的锁机制实现。
下面的代码实现了对查询记录的加锁:
String hqlStr ="from TUser as user where user.name='Erica'";
Query query = session.createQuery(hqlStr);
query.setLockMode("user",LockMode.UPGRADE); // 加锁
List userList = query.list();// 执行查询,获取数据query.setLockMode 对查询语句中,特定别名所对应的记录进行加锁(我们为 TUser 类指定了一个别名 “user” ),这里也就是对返回的所有 user 记录进行加锁。
观察运行期 Hibernate 生成的 SQL 语句:
select tuser0_.id as id, tuser0_.name as name, tuser0_.group_id as group_id, tuser0_.user_type as user_type, tuser0_.sex as sex from t_user tuser0_ where (tuser0_.name='Erica' ) for update
这里 Hibernate 通过使用数据库的 for update 子句实现了悲观锁机制。
Hibernate 的加锁模式有:
? LockMode.NONE : 无锁机制。
? LockMode.WRITE : Hibernate 在 Insert 和 Update 记录的时候会自动获取
? LockMode.READ : Hibernate 在读取记录的时候会自动获取。
以上这三种锁机制一般由 Hibernate 内部使用,如 Hibernate 为了保证 Update
过程中对象不会被外界修改,会在 save 方法实现中自动为目标对象加上 WRITE 锁。
? LockMode.UPGRADE :利用数据库的 for update 子句加锁。
? LockMode. UPGRADE_NOWAIT : Oracle 的特定实现,利用 Oracle 的 for
update nowait 子句实现加锁。
上面这两种锁机制是我们在应用层较为常用的,加锁一般通过以下方法实现:
Criteria.setLockMode
Query.setLockMode
Session.lock
注意,只有在查询开始之前(也就是 Hiberate 生成 SQL 之前)设定加锁,才会 真正通过数据库的锁机制进行加锁处理,否则,数据已经通过不包含 for update子句的 Select SQL 加载进来,所谓数据库加锁也就无从谈起。
为了更好的理解select... for update的锁表的过程,本人将要以mysql为例,进行相应的讲解
1、要测试锁定的状况,可以利用MySQL的Command Mode ,开二个视窗来做测试。
表的基本结构如下:
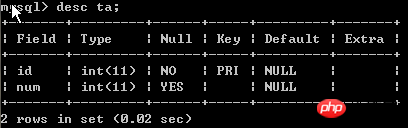
表中内容如下:
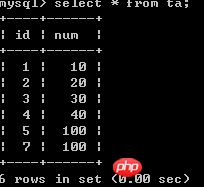
开启两个测试窗口,在其中一个窗口执行select * from ta for update0
然后在另外一个窗口执行update操作如下图:

等到一个窗口commit后的图片如下:

到这里,悲观锁机制你应该了解一些了吧~
需要注意的是for update要放到mysql的事务中,即begin和commit中,否者不起作用。
至于是锁住整个表还是锁住选中的行。
至于hibernate中的悲观锁使用起来比较简单,这里就不写demo了~感兴趣的自己查一下就ok了~
乐观锁(Optimistic Locking):
相对悲观锁而言,乐观锁机制采取了更加宽松的加锁机制。悲观锁大多数情况下依 靠数据库的锁机制实现,以保证操作最大程度的独占性。但随之而来的就是数据库 性能的大量开销,特别是对长事务而言,这样的开销往往无法承受。 如一个金融系统,当某个操作员读取用户的数据,并在读出的用户数据的基础上进 行修改时(如更改用户帐户余额),如果采用悲观锁机制,也就意味着整个操作过 程中(从操作员读出数据、开始修改直至提交修改结果的全过程,甚至还包括操作 员中途去煮咖啡的时间),数据库记录始终处于加锁状态,可以想见,如果面对几 百上千个并发,这样的情况将导致怎样的后果。 乐观锁机制在一定程度上解决了这个问题。
乐观锁,大多是基于数据版本 Version )记录机制实现。何谓数据版本?即为数据增加一个版本标识,在基于数据库表的版本解决方案中,一般是通过为数据库表增加一个 “version” 字段来 实现。 读取出数据时,将此版本号一同读出,之后更新时,对此版本号加一。此时,将提 交数据的版本数据与数据库表对应记录的当前版本信息进行比对,如果提交的数据 版本号大于数据库表当前版本号,则予以更新,否则认为是过期数据。对于上面修改用户帐户信息的例子而言,假设数据库中帐户信息表中有一个 version 字段,当前值为 1 ;而当前帐户余额字段( balance )为 $100 。操作员 A 此时将其读出( version=1 ),并从其帐户余额中扣除 $50( $100-$50 )。 2 在操作员 A 操作的过程中,操作员 B 也读入此用户信息( version=1 ),并 从其帐户余额中扣除 $20 ( $100-$20 )。 3 操作员 A 完成了修改工作,将数据版本号加一( version=2 ),连同帐户扣 除后余额( balance=$50 ),提交至数据库更新,此时由于提交数据版本大 于数据库记录当前版本,数据被更新,数据库记录 version 更新为 2 。 4 操作员 B 完成了操作,也将版本号加一( version=2 )试图向数据库提交数 据( balance=$80 ),但此时比对数据库记录版本时发现,操作员 B 提交的 数据版本号为 2 ,数据库记录当前版本也为 2 ,不满足 “ 提交版本必须大于记 录当前版本才能执行更新 “ 的乐观锁策略,因此,操作员 B 的提交被驳回。 这样,就避免了操作员 B 用基于version=1 的旧数据修改的结果覆盖操作 员 A 的操作结果的可能。 从上面的例子可以看出,乐观锁机制避免了长事务中的数据库加锁开销(操作员 A和操作员 B 操作过程中,都没有对数据库数据加锁),大大提升了大并发量下的系 统整体性能表现。 需要注意的是,乐观锁机制往往基于系统中的数据存储逻辑,因此也具备一定的局 限性,如在上例中,由于乐观锁机制是在我们的系统中实现,来自外部系统的用户 余额更新操作不受我们系统的控制,因此可能会造成脏数据被更新到数据库中。在 系统设计阶段,我们应该充分考虑到这些情况出现的可能性,并进行相应调整(如 将乐观锁策略在数据库存储过程中实现,对外只开放基于此存储过程的数据更新途 径,而不是将数据库表直接对外公开)。 Hibernate 在其数据访问引擎中内置了乐观锁实现。如果不用考虑外部系统对数 据库的更新操作,利用 Hibernate 提供的透明化乐观锁实现,将大大提升我们的 生产力。
User.hbm.xml
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="com.xiaohao.test">
<class name="User" table="user" optimistic-lock="version" >
<id name="id">
<generator class="native" />
</id>
<!--version标签必须跟在id标签后面-->
<version column="version" name="version" />
<property name="userName"/>
<property name="password"/>
</class>
</hibernate-mapping>注意 version 节点必须出现在 ID 节点之后。
这里我们声明了一个 version 属性,用于存放用户的版本信息,保存在 User 表的version中
optimistic-lock 属性有如下可选取值:
? none无乐观锁
? version通过版本机制实现乐观锁
? dirty通过检查发生变动过的属性实现乐观锁
? all通过检查所有属性实现乐观锁
其中通过 version 实现的乐观锁机制是 Hibernate 官方推荐的乐观锁实现,同时也 是 Hibernate 中,目前唯一在数据对象脱离 Session 发生修改的情况下依然有效的锁机 制。因此,一般情况下,我们都选择 version 方式作为 Hibernate 乐观锁实现机制。
2 、配置文件hibernate.cfg.xml和UserTest测试类
hibernate.cfg.xml
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory>
<!-- 指定数据库方言 如果使用jbpm的话,数据库方言只能是InnoDB-->
<property name="dialect">org.hibernate.dialect.MySQL5InnoDBDialect</property>
<!-- 根据需要自动创建数据表 -->
<property name="hbm2ddl.auto">update</property>
<!-- 显示Hibernate持久化操作所生成的SQL -->
<property name="show_sql">true</property>
<!-- 将SQL脚本进行格式化后再输出 -->
<property name="format_sql">false</property>
<property name="current_session_context_class">thread</property>
<!-- 导入映射配置 -->
<property name="connection.url">jdbc:mysql:///user</property>
<property name="connection.username">root</property>
<property name="connection.password">123456</property>
<property name="connection.driver_class">com.mysql.jdbc.Driver</property>
<mapping resource="com/xiaohao/test/User.hbm.xml" />
</session-factory>
</hibernate-configuration>UserTest.java
package com.xiaohao.test;
import org.hibernate.Session;
import org.hibernate.SessionFactory;
import org.hibernate.Transaction;
import org.hibernate.cfg.Configuration;
public class UserTest {
public static void main(String[] args) {
Configuration conf=new Configuration().configure();
SessionFactory sf=conf.buildSessionFactory();
Session session=sf.getCurrentSession();
Transaction tx=session.beginTransaction();
// User user=new User("小浩","英雄");
// session.save(user);
// session.createSQLQuery("insert into user(userName,password) value('张英雄16','123')")
// .executeUpdate();
User user=(User) session.get(User.class, 1);
user.setUserName("221");
// session.save(user);
System.out.println("恭喜您,用户的数据插入成功了哦~~");
tx.commit();
}
}每次对 TUser 进行更新的时候,我们可以发现,数据库中的 version 都在递增。
下面我们将要通过乐观锁来实现一下并发和同步的测试用例:
这里需要使用两个测试类,分别运行在不同的虚拟机上面,以此来模拟多个用户同时操作一张表,同时其中一个测试类需要模拟长事务
UserTest.java
package com.xiaohao.test;
import org.hibernate.Session;
import org.hibernate.SessionFactory;
import org.hibernate.Transaction;
import org.hibernate.cfg.Configuration;
public class UserTest {
public static void main(String[] args) {
Configuration conf=new Configuration().configure();
SessionFactory sf=conf.buildSessionFactory();
Session session=sf.openSession();
// Session session2=sf.openSession();
User user=(User) session.createQuery(" from User user where user=5").uniqueResult();
// User user2=(User) session.createQuery(" from User user where user=5").uniqueResult();
System.out.println(user.getVersion());
// System.out.println(user2.getVersion());
Transaction tx=session.beginTransaction();
user.setUserName("101");
tx.commit();
System.out.println(user.getVersion());
// System.out.println(user2.getVersion());
// System.out.println(user.getVersion()==user2.getVersion());
// Transaction tx2=session2.beginTransaction();
// user2.setUserName("4468");
// tx2.commit();
}
}UserTest2.java
package com.xiaohao.test;
import org.hibernate.Session;
import org.hibernate.SessionFactory;
import org.hibernate.Transaction;
import org.hibernate.cfg.Configuration;
public class UserTest2 {
public static void main(String[] args) throws InterruptedException {
Configuration conf=new Configuration().configure();
SessionFactory sf=conf.buildSessionFactory();
Session session=sf.openSession();
// Session session2=sf.openSession();
User user=(User) session.createQuery(" from User user where user=5").uniqueResult();
Thread.sleep(10000);
// User user2=(User) session.createQuery(" from User user where user=5").uniqueResult();
System.out.println(user.getVersion());
// System.out.println(user2.getVersion());
Transaction tx=session.beginTransaction();
user.setUserName("100");
tx.commit();
System.out.println(user.getVersion());
// System.out.println(user2.getVersion());
// System.out.println(user.getVersion()==user2.getVersion());
// Transaction tx2=session2.beginTransaction();
// user2.setUserName("4468");
// tx2.commit();
}
}操作流程及简单讲解: 首先启动UserTest2.java测试类,在执行到Thread.sleep(10000);这条语句的时候,当前线程会进入睡眠状态。在10秒钟之内启动UserTest这个类,在到达10秒的时候,我们将会在UserTest.java中抛出下面的异常:
Exception in thread "main" org.hibernate.StaleObjectStateException: Row was updated or deleted by another transaction (or unsaved-value mapping was incorrect): [com.xiaohao.test.User#5]
at org.hibernate.persister.entity.AbstractEntityPersister.check(AbstractEntityPersister.java:1932)
at org.hibernate.persister.entity.AbstractEntityPersister.update(AbstractEntityPersister.java:2576)
at org.hibernate.persister.entity.AbstractEntityPersister.updateOrInsert(AbstractEntityPersister.java:2476)
at org.hibernate.persister.entity.AbstractEntityPersister.update(AbstractEntityPersister.java:2803)
at org.hibernate.action.EntityUpdateAction.execute(EntityUpdateAction.java:113)
at org.hibernate.engine.ActionQueue.execute(ActionQueue.java:273)
at org.hibernate.engine.ActionQueue.executeActions(ActionQueue.java:265)
at org.hibernate.engine.ActionQueue.executeActions(ActionQueue.java:185)
at org.hibernate.event.def.AbstractFlushingEventListener.performExecutions(AbstractFlushingEventListener.java:321)
at org.hibernate.event.def.DefaultFlushEventListener.onFlush(DefaultFlushEventListener.java:51)
at org.hibernate.impl.SessionImpl.flush(SessionImpl.java:1216)
at org.hibernate.impl.SessionImpl.managedFlush(SessionImpl.java:383)
at org.hibernate.transaction.JDBCTransaction.commit(JDBCTransaction.java:133)
at com.xiaohao.test.UserTest2.main(UserTest2.java:21)UserTest2代码将在 tx.commit() 处抛出 StaleObjectStateException 异 常,并指出版本检查失败,当前事务正在试图提交一个过期数据。通过捕捉这个异常,我 们就可以在乐观锁校验失败时进行相应处理
3. Analyse des cas courants de synchronisation simultanée
Cas 1 : Cas du système de réservation Il n'y a qu'un seul billet pour un certain vol. Supposons que 10 000 personnes ouvrent votre site Web pour réserver des billets. .Demandez Comment résolvez-vous le problème de concurrence (peut être étendu à n'importe quel site Web à haute concurrence pour prendre en compte les problèmes de lecture et d'écriture simultanées)
problème, 10 000 personnes viennent visiter, avant que le ticket ne soit libéré, vous devez vous assurer que tout le monde puisse voir qu'il y a un ticket, c'est impossible. Lorsqu'une personne voit le ticket, les autres ne peuvent pas le voir. Qui peut l'acquérir dépend de la « chance » de la personne (vitesse du réseau, etc.). La deuxième considération est la concurrence. Si 10 000 personnes cliquent pour acheter en même temps, qui peut conclure l'affaire ? Il n'y a qu'un seul billet au total.
Tout d'abord, on peut facilement penser à plusieurs solutions liées à la concurrence :
Synchronisation des verrous La synchronisation fait davantage référence au niveau de l'application. Plusieurs threads entrent et ne sont accessibles qu'un par un, java Le majeur fait référence au mot-clé syncrinized. Les verrous ont également deux niveaux, l'un est le verrouillage d'objet mentionné en Java, qui est utilisé pour la synchronisation des threads ; l'autre niveau est le verrouillage de la base de données ; s'il s'agit d'un système distribué, il ne peut évidemment être obtenu qu'en utilisant le verrou sur la base de données ; côté.
En supposant que nous utilisions un mécanisme de synchronisation ou un mécanisme de verrouillage physique de base de données, comment garantir que 10 000 personnes peuvent toujours voir les tickets en même temps sacrifiera évidemment les performances, ce qui n'est pas conseillé dans les sites Web à forte concurrence. Après avoir utilisé la mise en veille prolongée, nous avons proposé un autre concept : le verrouillage optimiste et le verrouillage pessimiste (c'est-à-dire que l'utilisation du verrouillage physique traditionnel peut résoudre ce problème) ; Le verrouillage optimiste signifie utiliser le contrôle métier pour résoudre les problèmes de concurrence sans verrouiller la table. Cela garantit la lisibilité simultanée des données et l'exclusivité des données enregistrées. Il garantit les performances tout en résolvant le problème des données sales causées par la concurrence.
Comment implémenter le verrouillage optimiste en veille prolongée :
Prémisse : Ajouter un champ redondant à la table existante, numéro de version, type long
Principe :
1) Seul le numéro de version actuel = numéro de version de la table de base de données peut être soumis
2) Après une soumission réussie, le numéro de version version ++
est implémenté très simplement : ajoutez un attribut optimiste dans ormapping -lock="version" suffit, voici un exemple d'extrait
fcbe3e9142a5aba58f59285a7d211ac7
cb8fa3271e787dc97c7d5111201b534e
Cas 2, système boursier, système bancaire, comment considérez-vous la quantité de données volumineuses ?
Premier de tout, système de négociation d'actions Dans le tableau du marché, un enregistrement de marché est généré toutes les quelques secondes. En une journée, il y a (en supposant un marché toutes les 3 secondes) le nombre d'actions × 20 × 60 * 6 enregistrements. table avoir dans un mois ? Lorsque le nombre d'enregistrements dans une table dans Oracle dépasse 1 million, les performances des requêtes deviennent très mauvaises. Comment garantir les performances du système ?
Pour un autre exemple, China Mobile compte des centaines de millions d'utilisateurs. Comment concevoir le tableau ? Tout mettre dans un seul tableau ? Par conséquent, pour un grand nombre de systèmes, le fractionnement des tables doit être envisagé - (les noms des tables sont différents, mais les structures sont exactement les mêmes : (selon la situation)
1). ) Diviser par entreprise, comme pour la table des numéros de téléphone portable, on peut considérer celle commençant par 130 comme une table, l'autre table commençant par 131, et ainsi de suite
2) Utiliser le mécanisme de division de table d'Oracle pour créer des sous-tableaux
3 ) S'il s'agit d'un système de trading, on peut envisager de le diviser selon la chronologie, avec les données du jour en cours dans un tableau et les données historiques dans un autre tableau. Les rapports et requêtes de données historiques ici n’affecteront pas la négociation de la journée.
Bien sûr, après le partage de la table, notre candidature doit être adaptée en conséquence. Le simple ou le mappage devra peut-être être modifié. Par exemple, certaines entreprises doivent passer par des procédures stockées, etc.
De plus, nous devons envisager la mise en cache
Le cache ici ne fait pas seulement référence à la mise en veille prolongée, mais la mise en veille prolongée elle-même fournit en premier- et cache de deuxième niveau. Le cache ici est indépendant de l'application et reste une lecture de la mémoire. Si nous pouvons réduire les accès fréquents à la base de données, cela sera certainement très bénéfique pour le système. Par exemple, dans la recherche de produits dans un système de commerce électronique, si un produit avec un certain mot-clé est fréquemment recherché, vous pouvez alors envisager de stocker cette partie de la liste de produits dans le cache (en mémoire), afin de ne pas avoir à le faire. accédez à la base de données à chaque fois et les performances sont grandement améliorées.
Pour une mise en cache simple, vous pouvez comprendre que vous créez vous-même une hashmap et créez une clé pour les données fréquemment consultées. La valeur est la valeur recherchée dans la base de données pour la première fois. Vous pouvez la lire à partir de la carte. lors de la prochaine visite, au lieu de lire la base de données, les bases de données plus professionnelles disposent actuellement de cadres de mise en cache indépendants tels que memcached, qui peuvent être déployés indépendamment en tant que serveur de cache.
4. Méthodes courantes pour améliorer l'efficacité de l'accès en cas de concurrence élevée
Tout d'abord, nous devons comprendre où se trouve le goulot d'étranglement de la concurrence élevée ?
1. La bande passante du réseau du serveur peut ne pas être suffisante
2. Le nombre de connexions au fil Web peut ne pas être suffisant
3. monter.
Selon les différentes situations, les solutions sont différentes.
Comme dans le premier cas, vous pouvez augmenter la bande passante du réseau et distribuer la résolution de noms de domaine DNS sur plusieurs serveurs.
Équilibrage de charge, serveur proxy frontal nginx, apache, etc.
Optimisation des requêtes de base de données, séparation lecture-écriture, partitionnement de table, etc.
Enfin, copiez-en quelques-uns sont nécessaires dans un contenu à haute concurrence qui doit souvent être traité :
Essayez d'utiliser le cache, y compris le cache utilisateur, le cache d'informations, etc. Dépenser plus de mémoire pour la mise en cache peut réduire considérablement l'interaction avec la base de données et améliorer les performances.
Utilisez des outils tels que jprofiler pour détecter les goulots d'étranglement en matière de performances et réduire les frais supplémentaires.
Optimisez les instructions de requête de base de données et réduisez le nombre d'instructions directement générées à l'aide d'outils tels que la mise en veille prolongée (seules les requêtes à long terme sont optimisées).
Optimisez la structure de la base de données, créez plus d'index et améliorez l'efficacité des requêtes.
Essayez de mettre en cache les fonctions de statistiques autant que possible, ou comptez les rapports associés quotidiennement ou régulièrement pour éviter les statistiques en cas de besoin.
Utilisez des pages statiques autant que possible pour réduire l'analyse des conteneurs (essayez de générer du HTML statique pour le contenu dynamique à afficher).
Après avoir résolu les problèmes ci-dessus, utilisez un cluster de serveurs pour résoudre le problème de goulot d'étranglement d'un seul serveur.
Java a une concurrence élevée, comment le résoudre, quelle méthode pour le résoudre
Avant, je pensais à tort que la solution à une concurrence élevée pouvait être résolue par des threads ou des files d'attente , car une concurrence élevée Parfois, de nombreux utilisateurs y accèdent, ce qui entraîne des données système incorrectes et une perte de données, alors j'ai pensé Les files d'attente sont utilisées pour résoudre le problème. En fait, les files d'attente peuvent également être utilisées pour résoudre le problème. Par exemple, lorsque nous enchérions sur des produits, transmettons des commentaires sur Weibo ou vendons des produits flash, le nombre de visites est identique. le temps est particulièrement long. Les files d’attente jouent ici un rôle particulier. Toutes les demandes sont mises dans la file d'attente et traitées de manière ordonnée en unités de synchronisation en millisecondes, de sorte qu'il n'y ait pas de perte de données ni de données système incorrectes.
Après avoir vérifié les informations aujourd'hui, il existe deux solutions à une simultanéité élevée :
L'une consiste à utiliser la mise en cache, l'autre consiste à générer des pages statiques et l'autre consiste à partir de l'endroit le plus élémentaire ; Optimisez le code que nous écrivons pour réduire le gaspillage inutile de ressources : (
1. N'utilisez pas fréquemment de nouveaux objets. Utilisez le mode singleton pour les classes qui n'ont besoin que d'une seule instance dans l'ensemble de l'application. Pour les opérations de connexion String, utilisez StringBuffer ou StringBuilder. Pour les classes de type utilitaire, accédez-y via des méthodes statiques
2. Évitez d'utiliser de mauvaises méthodes. Par exemple, Exception peut contrôler le lancement de la méthode, mais Exception doit conserver stacktrace pour consommer les performances. Ne l'utilisez pas sauf si nécessaire. Par exemple, pour effectuer un jugement conditionnel, essayez d'utiliser la méthode de jugement conditionnel du ratio. Utilisez des classes efficaces en JAVA, telles que ArrayList, qui a de meilleures performances que Vector. )
Tout d'abord, je n'ai jamais utilisé la technologie de mise en cache. Je pense qu'elle devrait enregistrer les données dans le cache lorsque l'utilisateur le demande. La requête suivante détectera s'il y a des données dans le cache pour éviter plusieurs requêtes. au serveur. Cela entraînera une diminution des performances du serveur et provoquera sérieusement un crash du serveur. Ce n'est que ma propre compréhension. Des informations détaillées doivent encore être collectées en ligne. Je pense que vous ne devriez pas utiliser la méthode pour générer des pages statiques. J'ai vu de nombreux sites Web lorsque la page est demandée. La plupart ont changé, comme "http://developer.51cto.com/art/201207/348766.htm". Cette page est en fait une adresse de demande de serveur après avoir été convertie en HTM. , la vitesse d'accès augmentera car les pages statiques n'ont pas de composants serveur ; je vais les présenter plus ici :
1 Qu'est-ce que la statique de page :
Simple. En termes simples, si nous visitons un lien ,Le module correspondant du serveur traitera cette requête, accédera à l'interface jsp correspondante et générera enfin les données que nous voulons voir. L'inconvénient est évident : parce que chaque requête adressée au serveur sera traitée, comme par exemple S'il y a trop de requêtes simultanées, cela augmentera la pression sur le serveur d'applications et pourrait même le faire tomber en panne. Alors comment l’éviter ? Si on met la paire test.do Le résultat de la requête est enregistré dans un fichier HTML, puis l'utilisateur y accède à chaque fois. La pression sur le serveur d'applications ne serait-elle pas réduite ?
Alors, d'où viennent les pages statiques ? Nous ne pouvons pas nous laisser traiter chaque page manuellement, n'est-ce pas ? Cela implique ce que nous allons expliquer, la solution de génération de page statique... Ce dont nous avons besoin est de générer automatiquement une page statique lors de la visite, test.html sera automatiquement généré puis affiché à l'utilisateur.
2. Présentons brièvement les points de connaissances que vous devez maîtriser pour maîtriser le schéma de statique de page :
1. Bases - Réécriture d'URL
Qu'est-ce que la réécriture d'URL ? ? Réécriture d'URL. Utilisons un exemple simple pour illustrer le problème : entrez l'URL, mais accédez en fait à abc.com/test.action, nous pouvons alors dire que l'URL a été réécrite. Cette technologie est largement utilisée et il existe de nombreux outils open source permettant de réaliser cette fonction.
2. Bases - Servlet web.xml
Si vous ne savez toujours pas comment une requête et un servlet sont mis en correspondance dans web.xml, veuillez rechercher dans la documentation du servlet. Cela n’a pas de sens, beaucoup de gens pensent que la méthode de correspondance /xyz/*.do peut être efficace.
Si vous ne savez toujours pas comment écrire une servlet, veuillez rechercher comment écrire une servlet. Ce n'est pas une blague. Aujourd'hui, avec divers outils d'intégration qui circulent, beaucoup de gens n'en écriront pas une à partir de zéro. .
3. Introduction à la solution de base

Parmi eux, pour la partie URL Rewriter, vous pouvez utiliser des outils payants ou open source pour implémentez-le, si l'URL n'est pas particulièrement complexe, vous pouvez envisager de l'implémenter dans un servlet, alors cela ressemblera à ceci :

总 结:其实我们在开发中都很少考虑这种问题,直接都是先将功能实现,当一个程序员在干到1到2年,就会感觉光实现功能不是最主要的,安全性能、质量等等才是 一个开发人员最该关心的。今天我所说的是高并发。
我的解决思路是:
1、采用分布式应用设计
2、分布式缓存数据库
3、代码优化
Java高并发的例子:
具体情况是这样: 通过java和数据库,自己实现序列自动增长。
实现代码大致如下:
id_table表结构, 主要字段:
id_name varchar2(16); id_val number(16,0); id_prefix varchar2(4);
//操作DB
public synchronized String nextStringValue(String id){
SqlSession sqlSess = SqlSessionUtil.getSqlSession();
sqlSess.update("update id_table set id_val = id_val + 1 where id_name="+id);
Map map = sqlSess.getOne("select id_name, id_prefix, id_val from id_table where id_name="+ id);
BigDecimal val = (BigDecimal) map.get("id_val");
//id_val是具体数字,rePack主要是统一返回固定长度的字符串;如:Y0000001, F0000001, T0000001等
String idValue = rePack(val, map);
return idValue;
}
//公共方法
public class IdHelpTool{
public static String getNextStringValue(String idName){
return getXX().nextStringValue(idName);
}
}具体使用者,都是通过类似这种方式:IdHelpTool.getNextStringValue("PAY_LOG");来调用。
问题:
(1) 当出现并发时, 有时会获取重复的ID;
(2) 由于服务器做了相关一些设置,有时调用这个方法,好像还会导致超时。
为了解决问题(1), 考虑过在方法getNextStringValue上,也加上synchronized , 同步关键字过多,会不会更导致超时?
跪求大侠提供个解决问题的大概思路!!!
解决思路一:
1、推荐 https://github.com/adyliu/idcenter
2、可以通过第三方redis来实现。
解决思路一:
1、出现重复ID,是因为脏读了,并发的时候不加 synchronized 比如会出现问题
2、但是加了 synchronized ,性能急剧下降了,本身 java 就是多线程的,你把它单线程使用,不是明智的选择,同时,如果分布式部署的时候,加了 synchronized 也无法控制并发
3、调用这个方法,出现超时的情况,说明你的并发已经超过了数据库所能处理的极限,数据库无限等待导致超时
基于上面的分析,建议采用线程池的方案,支付宝的单号就是用的线程池的方案进行的。
数据库 update 不是一次加1,而是一次加几百甚至上千,然后取到的这 1000个序号,放在线程池里慢慢分配即可,能应付任意大的并发,同时保证数据库没任何压力。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!