
Maison >développement back-end >Tutoriel Python >Explication détaillée des protocoles http et https dans le robot d'exploration Python (image et texte)
Explication détaillée des protocoles http et https dans le robot d'exploration Python (image et texte)

- 不言original
- 2018-09-15 15:02:442991parcourir
Le contenu de cet article est une explication détaillée (images et textes) des protocoles http et https dans les robots python. Il a une certaine valeur de référence. Les amis dans le besoin peuvent s'y référer.
1. Protocole HTTP
1. Concept officiel :
Le protocole HTTP est l'abréviation de Hyper Text Transfer Protocol, qui est utilisé pour transférer des données depuis le transport. protocole utilisé par les serveurs du World Wide Web (WWW : World Wide Web) pour transmettre de l'hypertexte aux navigateurs locaux. (Bien que les chaussures pour enfants soient aveugles à ce concept, elles ne peuvent rien y faire. Après tout, il s'agit de l'explication conceptuelle faisant autorité et officielle du HTTP. Si vous voulez le comprendre pleinement, veuillez déplacer vos yeux vers le bas. ..)
2. Concept vernaculaire :
Le protocole HTTP est une forme d'interaction de données (transmission mutuelle de données) entre le serveur (Serveur) et le client (Client). Nous pouvons personnifier Serveur et Client, alors ce protocole est une méthode de communication interactive désignée entre les deux frères Serveur et Client.
3. Principe de fonctionnement du HTTP :
Le protocole HTTP fonctionne sur une architecture client-serveur. En tant que client HTTP, le navigateur envoie toutes les requêtes au serveur HTTP, c'est-à-dire au serveur WEB, via l'URL. Le serveur Web envoie des informations de réponse au client sur la base de la demande reçue.
> 4. Quatre points à noter concernant HTTP : 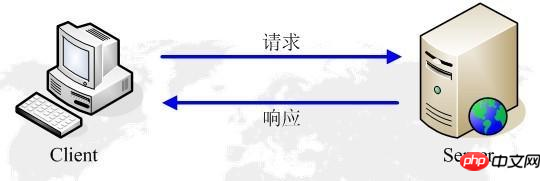 - HTTP permet la transmission de tout type d'objet de données. Le type en cours de transfert est marqué par Content-Type. - HTTP est sans connexion : sans connexion signifie que chaque connexion est limitée au traitement d'une seule requête. Une fois que le serveur a traité la demande du client et reçu la réponse du client, il se déconnecte. Cette méthode permet de gagner du temps de transmission. - HTTP est indépendant du média : cela signifie que tout type de données peut être envoyé via HTTP tant que le client et le serveur savent comment gérer le contenu des données. Les clients et les serveurs spécifient le type de contenu MIME approprié à utiliser. - HTTP est sans état : Le protocole HTTP est un protocole sans état. Sans état signifie que le protocole n'a aucune capacité de mémoire pour le traitement des transactions. L'absence de statut signifie que si un traitement ultérieur nécessite les informations précédentes, celles-ci doivent être retransmises, ce qui peut entraîner une augmentation de la quantité de données transférées par connexion. En revanche, le serveur répond plus rapidement lorsqu’il n’a pas besoin d’informations préalables.
- HTTP permet la transmission de tout type d'objet de données. Le type en cours de transfert est marqué par Content-Type. - HTTP est sans connexion : sans connexion signifie que chaque connexion est limitée au traitement d'une seule requête. Une fois que le serveur a traité la demande du client et reçu la réponse du client, il se déconnecte. Cette méthode permet de gagner du temps de transmission. - HTTP est indépendant du média : cela signifie que tout type de données peut être envoyé via HTTP tant que le client et le serveur savent comment gérer le contenu des données. Les clients et les serveurs spécifient le type de contenu MIME approprié à utiliser. - HTTP est sans état : Le protocole HTTP est un protocole sans état. Sans état signifie que le protocole n'a aucune capacité de mémoire pour le traitement des transactions. L'absence de statut signifie que si un traitement ultérieur nécessite les informations précédentes, celles-ci doivent être retransmises, ce qui peut entraîner une augmentation de la quantité de données transférées par connexion. En revanche, le serveur répond plus rapidement lorsqu’il n’a pas besoin d’informations préalables.
5.URL HTTP :
HTTP utilise des identifiants de ressources uniformes (URI) pour transmettre des données et établir des connexions. L'URL est un type spécial d'URI qui contient suffisamment d'informations pour trouver une ressource
URL, le nom complet est UniformResourceLocator, qui est appelé Uniform Resource Locator en chinois, et est utilisé pour identifier une certaine ressource sur Internet. adresse. Prenons l'URL suivante comme exemple pour présenter les composants d'une URL normale : http://www.aspxfans.com:8080/news/index.asp?boardID=5&ID=24618&page=1#name Comme le montre ce qui précède URL , une URL complète comprend les parties suivantes :
-Partie protocole : La partie protocole de l'URL est « http : », ce qui signifie que la page Web utilise le protocole HTTP. Différents protocoles peuvent être utilisés sur Internet, tels que HTTP, FTP, etc. Dans cet exemple, le protocole HTTP est utilisé. Le "//" après "HTTP" est le délimiteur
- Partie nom de domaine : La partie nom de domaine de l'URL est "www.aspxfans.com". Dans une URL, vous pouvez également utiliser l'adresse IP comme nom de domaine
-Partie port : Après le nom de domaine se trouve le port, et ":" est utilisé comme séparateur entre le nom de domaine et le port. Le port n'est pas une partie nécessaire d'une URL. Si la partie port est omise, le port par défaut sera utilisé
- Partie répertoire virtuel : En commençant par le premier "/" après le nom de domaine jusqu'au dernier ". /", c'est la partie répertoire virtuel. Le répertoire virtuel n'est pas non plus une partie obligatoire d'une URL. Le répertoire virtuel dans cet exemple est "/news/"
- La partie nom de fichier : en commençant par le dernier "/" après le nom de domaine et se terminant par "?", c'est la partie nom de fichier Si. il n'y a pas de "?", il commence par le dernier "/" après le nom de domaine et se termine par "#", qui est la partie du fichier. S'il n'y a pas de "?" et de "#", alors il commence par le dernier. "/" après le nom de domaine et se termine par celui-ci, qui correspond à la partie nom du fichier. Le nom du fichier dans cet exemple est « index.asp ». La partie nom de fichier n'est pas une partie nécessaire d'une URL. Si cette partie est omise, le nom de fichier par défaut
sera utilisé. Partie ancre : en commençant par "#" jusqu'à la fin, c'est la partie ancre. . La partie d'ancrage dans ce cas est "nom". La partie ancre n'est pas non plus une partie nécessaire d'une URL
- Partie paramètre : La partie commençant de "?" à "#" est la partie paramètre, également appelée partie recherche et partie requête. La partie paramètre dans cet exemple est "boardID=5&ID=24618&page=1". Les paramètres peuvent autoriser plusieurs paramètres et "&" est utilisé comme séparateur entre les paramètres.
6. Requête HTTP :
Le message de requête dans lequel le client envoie une requête HTTP au serveur comprend les composants suivants :
En-tête de message : souvent appelé en-tête de requête, l'en-tête de requête stocke certaines descriptions principales de la requête (auto-introduction). Le serveur obtient les informations du client en conséquence.
En-têtes de requête courants :
accepter : le navigateur indique au serveur via cet en-tête les types de données qu'il prend en charge
Accept-Charset : le navigateur indique au serveur via cet en-tête, quel jeu de caractères il prend en charge
Accept-Encoding : le navigateur indique au serveur via cet en-tête, le format de compression pris en charge
Accept-Language : le navigateur indique au serveur via cet en-tête, ses paramètres régionaux
Host : le navigateur indique au serveur via cet en-tête à quel hôte il souhaite accéder
If-Modified-Since : Le navigateur indique au serveur via cet en-tête l'heure de mise en cache des données
Referer : Le navigateur indique au serveur via cet en-tête que le client est De quelle page provient ? Anti-sangsue
Connexion : Le navigateur indique au serveur via cet en-tête s'il doit déconnecter ou maintenir le lien une fois la demande terminée
X-Requested-With : XMLHttpRequest représente l'accès via ajax
User-Agent : L'identité du porteur de la requête
Corps du message : souvent appelé corps de la requête, le corps de la requête stocke les données informations à transmettre/ envoyé au serveur.
7. Réponse HTTP :
Le message de réponse renvoyé par le serveur au client comprend les composants suivants :

Code de statut : Indiquez au client le résultat du traitement de cette demande dans un langage "clair et sans ambiguïté".
Le code d'état de la réponse HTTP se compose de 5 segments :
Message 1xx, indiquant généralement au client que la demande a été reçue et est en cours de traitement, ne vous inquiétez pas...
2xx est traité avec succès, ce qui signifie généralement : la demande est reçue, je comprends ce que vous voulez, la demande a été acceptée et le traitement est terminé
3xx redirige vers d'autres endroits. Il permet au client de faire une autre demande pour terminer l'ensemble du processus.
4xx Lorsqu'une erreur survient dans le traitement, la responsabilité incombe au client. Par exemple, le client demande une ressource qui n'existe pas, le client n'est pas autorisé, l'accès est interdit, etc.
5xx Lorsqu'une erreur se produit lors du traitement, la responsabilité incombe au serveur. Par exemple, si le serveur lève une exception, l'erreur de routage se produit, la version HTTP n'est pas prise en charge, etc.
En-tête de réponse : affichage des détails de la réponse
Informations d'en-tête correspondantes communes :
Emplacement : Le serveur utilise cet en-tête pour indiquer au navigateur où sauter
Serveur : Le serveur utilise cet en-tête pour indiquer au navigateur le modèle du serveur
Content-Encoding : le serveur utilise cet en-tête pour indiquer au navigateur le format de compression des données
Content-Length : le serveur utilise cet en-tête pour indiquer au navigateur la longueur des données renvoyées
Content-Language : Le serveur utilise cet en-tête pour indiquer au navigateur l'environnement linguistique
Content-Type : Le serveur utilise cet en-tête pour indiquer au navigateur le type de données renvoyées
Actualiser : Le serveur utilise cet en-tête pour indiquer au navigateur le timing Refresh
Content-Disposition : Le serveur utilise cet en-tête pour indiquer au navigateur de télécharger les données
Transfer-Encoding : Le serveur utilise cet en-tête pour indiquer au navigateur que les données sont renvoyées par morceaux
Expire : - 1 Contrôler le navigateur pour ne pas mettre en cache
Cache-Control : no-cache
Pragma : no-cache
Réponse : Selon la requête informations spécifiées par le client, les données spécifiées sont envoyées au client
2. Protocole HTTPS
1 Concept officiel :
HTTPS (Secure Hypertext Transfer Protocol HTTPS). établit une couche de cryptage SSL sur HTTP et Les données sont cryptées et constituent une version sécurisée du protocole HTTP.
2. Concept vernaculaire :
Une version cryptée et sécurisée du protocole HTTP.
3. Technologie de cryptage utilisée par HTTPS
3.1 Technologie de cryptage SSL
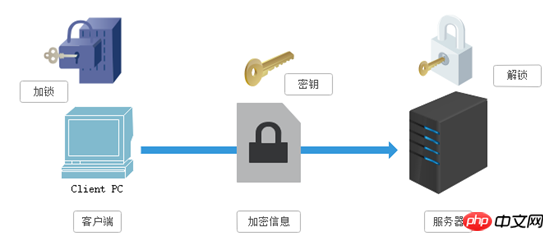
La technologie de cryptage utilisée par SSL est appelée « cryptage à clé partagée » " , également appelé « chiffrement à clé symétrique », cette méthode de chiffrement est la suivante. Par exemple, le client envoie un message au serveur. Tout d'abord, le client chiffrera le message à l'aide d'un algorithme connu, tel que le chiffrement MD5 ou Base64. A La clé est requise lors du déchiffrement des informations cryptées, et la clé est transmise au milieu (la clé de cryptage et de déchiffrement est la même) et la clé est cryptée pendant la transmission. Cette méthode semble sûre, mais elle reste potentiellement dangereuse. Une fois écoutée ou détournée, il est possible de déchiffrer la clé et de déchiffrer les informations. Par conséquent, il existe des risques de sécurité dans la méthode de « cryptage à clé partagée » :
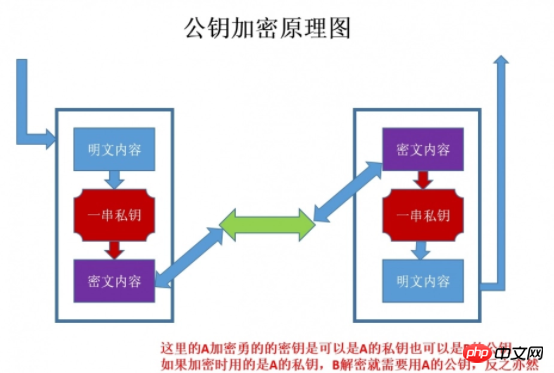
3.2 Technologie de cryptage à clé asymétrique
Il y a deux verrous lors de l'utilisation du « cryptage asymétrique », l'un est appelé « clé privée » et l'autre est la « clé publique ». Lors de l'utilisation de la méthode de cryptage sans objet, le serveur en informe d'abord le client selon The. La clé publique que vous avez fournie est cryptée. Une fois que le client a crypté selon la clé publique, le serveur reçoit les informations puis les déchiffre via sa propre clé privée. L'avantage est que la clé déchiffrée ne sera pas transmise du tout. Cela évite également le risque d’être pris en otage. Même si la clé publique est obtenue par une écoute indiscrète, elle sera difficile à déchiffrer car le processus de décryptage implique l'évaluation de logarithmes discrets, ce qui n'est pas quelque chose qui peut être fait facilement. Voici le diagramme schématique du cryptage asymétrique :

Mais la technologie de cryptage asymétrique à clé présente également les inconvénients suivants :
Le premier est : comment garantir que l'extrémité réceptrice Lors de l'envoi de la clé publique à l'expéditeur, celui-ci s'assure que ce qui est reçu est ce qui a été envoyé à l'avance et ne sera pas détourné. Tant que la clé est envoyée, il existe un risque de détournement.
Le deuxième est : l'efficacité du cryptage asymétrique est relativement faible, il est plus complexe à traiter et il existe certains problèmes d'efficacité pendant le processus de communication qui affectent la vitesse de communication
4. Mécanisme de certificat https
Nous avons évoqué ci-dessus les inconvénients du cryptage asymétrique. Le premier est que la clé publique est susceptible d'être détournée. Il n'y a aucune garantie que la clé publique reçue par le client soit la clé publique émise. par la clé du serveur. A cette époque, le mécanisme de certificat de clé publique a été introduit. L'autorité de certification des certificats numériques est une organisation tierce à laquelle le client et le serveur font confiance. Le processus spécifique de diffusion du certificat est le suivant :
1 : Le développeur du serveur porte la clé publique et demande la clé publique à l'autorité de certification du certificat numérique. L'autorité de certification du certificat numérique reconnaîtra l'identité. du demandeur et réussir l'examen. À l'avenir, la clé publique appliquée par le développeur sera signée numériquement, puis la clé publique signée sera distribuée, et la clé sera placée dans le certificat et liée ensemble
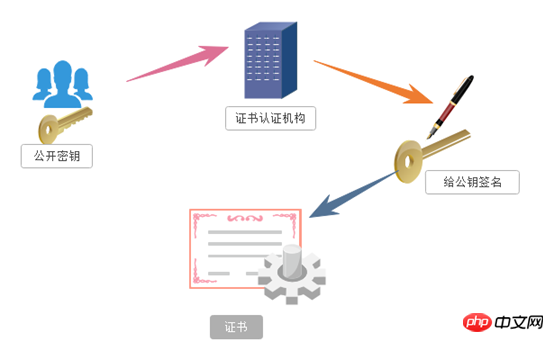
2 : Le serveur envoie ce certificat numérique au client. Parce que le client reconnaît également l'autorité de certification, le client peut vérifier l'authenticité de la clé publique via la signature numérique dans. le certificat numérique pour garantir que le serveur le transmet. La clé publique est réelle. En général, la signature numérique d'un certificat est difficile à falsifier, selon la crédibilité de l'autorité de certification. Une fois les informations confirmées, le client cryptera le message et l'enverra à l'aide de la clé publique, et le serveur le déchiffrera avec sa propre clé privée après l'avoir reçu.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!