
Maison >base de données >tutoriel mysql >[Base de données MySQL] Interprétation du Chapitre 4 : Optimisation des schémas et des types de données (Partie 1)
[Base de données MySQL] Interprétation du Chapitre 4 : Optimisation des schémas et des types de données (Partie 1)
- php是最好的语言original
- 2018-08-07 13:53:421806parcourir
Avant-propos :
La pierre angulaire de la haute performance : bonne conception logique et physique, conception du schéma en fonction des instructions de requête à exécuter par le système
Ce chapitre se concentre sur la conception de bases de données MySQL et présente la différence entre la conception de bases de données MySQL et d'autres systèmes de gestion de bases de données relationnelles
schéma : [Source]
Le schéma est Une collection d'objets de base de données Cette collection contient divers objets tels que des tables, des vues, des procédures stockées, des index, etc. Afin de distinguer les différentes collections, vous devez donner des noms différents aux différentes collections. Par défaut un utilisateur correspond à une collection Le nom du schéma de l'utilisateur est égal au nom de l'utilisateur et est utilisé comme schéma par défaut pour. l'utilisateur. La collection de schémas ressemble donc à des noms d'utilisateur.
Si vous considérez la base de données comme un entrepôt, l'entrepôt a plusieurs pièces (schéma), un schéma représente une pièce, la table peut être vue comme un casier dans chaque pièce et l'utilisateur est le propriétaire de chaque schéma. A le droit d'exploiter chaque pièce de la base de données, ce qui signifie que chaque utilisateur mappé dans la base de données possède la clé de chaque schéma (pièce). Il existe des différences entre SQL Server et Oracle MySQL
4.1 Sélectionnez les types de données optimisés
Principes :
1 Les passes plus petites sont meilleures, essayez d'utiliser. eux Le plus petit type de données capable de stocker correctement les données (occupe moins de mémoire disque et de cache CPU, nécessite moins de cycles CPU pour le traitement : plus rapide), mais peut couvrir les données, et ce sera embarrassant si elles ne peuvent pas être stockées
2, Simple c'est bien : type simple (moins de cycles CPU), utilisez le temps de stockage du type intégré MySQL, IP de stockage de type entier, le type entier est moins cher que les caractères (le jeu de caractères et les règles de classement rendent les caractères plus complexes)
3. Essayez d'éviter null : il est préférable de spécifier non null
*) Les colonnes nulles utilisent plus d'espace de stockage et nécessitent un traitement spécial dans MySQL
*) Null crée des statistiques d'indexation et d'indexation. et La comparaison des valeurs est plus complexe ; lorsque les colonnes nullables sont indexées, chaque enregistrement d'index nécessite des octets supplémentaires
Exception : InnoDB utilise un seul bit pour stocker les valeurs nulles, donc pour les données clairsemées (de nombreuses valeurs sont nulles) il existe une très bonne efficacité spatiale, ne convient pas à MyISAM
4.1.1 type entier [Référence]
nombre entier entier
tinyint (espace de stockage 8 bits) smallint( 16) mediumint (24) int(32) bigint(64)
1. Plage de valeurs stockées : 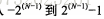 , N est le nombre de chiffres dans l'espace de stockage
, N est le nombre de chiffres dans l'espace de stockage
2. facultatif, non autorisé Les valeurs négatives peuvent doubler la limite supérieure des nombres positifs : tinyint unsigned 0~255, tinyint-128~127
3. Utilisez le même espace de stockage et les mêmes performances avec ou sans signes
. 🎜>
La largeur peut être spécifiée pour un entier, tel que INT(11), ce qui n'a aucun sens pour la plupart des applications. Elle ne limite pas la plage légale de valeurs, elle spécifie uniquement le nombre de caractères affichés par les outils interactifs. Pour le stockage et le calcul, int(1) et int (20) sont identiques nombre réel : avec des décimales float et double, mysql utilise duble comme type de calculs à virgule flottante internes ; decimal : stocke le nombre décimal précis, implémenté par le serveur mysql lui-même, decimal(18,9)18 chiffres, 9 chiffres décimaux, 9 octets (les 4 premiers et les 4 derniers points 1) Essayez pour l'utiliser uniquement lors du calcul précis des décimales (espace supplémentaire et surcharge de calcul), comme les données financières Lorsque la quantité de données est importante, envisagez plutôt d'utiliser bigint, multipliez le nombre de décimales dans les données de l'unité monétaire qui doit être stocké par les multiples points flottants correspondants : Suggestion : spécifiez uniquement le type et la précision indéfinie (mysql, ces précisions ne sont pas standard). MySQL sélectionnera silencieusement le type. ou arrondissez la valeur lors du stockage. Lors du stockage de valeurs dans la même plage, moins d'espace que décimal, float4 octets stocke double8 octets (plage de précision supérieure) 4.1.3 Type de chaîne. varchar et char : Prérequis : Moteurs Innodb et myisam, le type de chaîne le plus important Stockage sur disque : La méthode de stockage du moteur de stockage doit être différente de celle dans mémoire et disque, le serveur mysql doit donc convertir le format pour obtenir la valeur du moteurvarchar :
1. Le stockage des chaînes variables permet d'économiser de l'espace par rapport à. longueur fixe (n'utilise que l'espace nécessaire), mais si la table utilise row_format=fixed, les lignes seront stockées dans une longueur fixe 2 1/2 octet supplémentaire est nécessaire pour enregistrer la longueur de la chaîne 1) colonne ; longueur maximale 3. Économisez de l'espace de stockage et bénéficiez de performances ; mais la ligne peut changer lors de la mise à jour. Elle est plus longue que l'original et nécessite un travail supplémentaireSituations appropriées :
1) La longueur maximale de la colonne de chaîne est bien supérieure à la longueur moyenne ; 2) Mise à jour de la colonne Moins (pas de soucis de fragmentation) 3) Utilisez des chaînes UTF-8, chaque caractère est stocké en utilisant un nombre d'octets différentcaractère :
1. Longueur fixe, allouez l'espace en fonction de la longueur, supprimez les espaces à la fin de tout si la longueur n'est pas suffisante, remplissez les espaces
2 Plus efficace en espace de stockage, char. (1) est utilisé pour stocker seulement 1 valeur de Y N Bytes, varchar2 bytes et une longueur d'enregistrement
Situations appropriées :
1) Convient pour stocker des chaînes très courtes ; 2) Ou la valeur all est proche de La même longueur ; 3) Les données fréquemment modifiées ne sont pas facilement fragmentées lorsqu'elles sont stockées
correspond aux espaces et au stockage :
. Lorsque le type char est stocké, les espaces de fin sont supprimés ; la façon dont les données sont stockées dépend de Concernant le moteur de stockage, le moteur de mémoire ne prend en charge que les lignes de longueur fixe (longueur maximale de l'espace alloué)
binaire, varbinary : stocke les chaînes binaires , bytecode , longueur insuffisante,
4.1.5 bits
bit : mysql5.0
Anciennement synonyme de tinyint, nouvelles fonctionnalités
bit (1) champ mono-bit, bit (2) 2 bits, longueur maximale 64 bits
Le comportement varie en fonction du moteur de stockage MyISAM regroupe et stocke toutes les colonnes BIT (17 colonnes de bits distinctes ne nécessitent que 17 bits pour être stockées, myisam3 octets ok), autres les moteurs Memory et innoDB utilisent le plus petit type entier suffisant pour stocker chaque colonne de bits, ce qui n'économise pas d'espace de stockage
MySQL traite les bits comme un type de chaîne , récupération Le bit(1) La valeur et le résultat sont des chaînes contenant 0/1 binaire. La récupération du contexte numérique convertit les chaînes en nombres. Dans la plupart des applications, il est préférable d'éviter d'utiliser
![[Base de données MySQL] Interprétation du Chapitre 4 : Optimisation des schémas et des types de données (Partie 1)](https://img.php.cn//upload/image/636/907/440/1533621119495187.png "1533621119495187.png")
set
. Lors de la création d'une table, précisez la plage de valeurs du type SET : nom d'attribut SET ('value 1', 'value 2', 'value 3'..., 'value n') , le paramètre "value n" représente la nième valeur de la liste. Les espaces à la fin de ces valeurs seront directement supprimés par le système. Le système affichera automatiquement la séquence des éléments du champ dans l'ordre dans lequel elle est répétée et ne la sauvegardera qu'une seule fois.
Sa forme de base est la même que celle du type ENUM. La valeur de type SET peut être un élément ou une combinaison de plusieurs éléments dans la liste. Lors de la récupération de plusieurs éléments, séparez-les par des virgules. La valeur du type SET ne peut être qu'une combinaison de 64 éléments maximum. Selon les membres, le stockage est également différent : [Référence, identique à enum]
1~8成员的集合,占1个字节。 9~16成员的集合,占2个字节。 17~24成员的集合,占3个字节。 25~32成员的集合,占4个字节。 33~64成员的集合,占8个字节。
Il est nécessaire d'en conserver plusieurs. valeurs vraies et fausses. Vous pouvez envisager de fusionner ces colonnes en types d'ensembles, qui sont représentés en interne par une série de bits compressés ( utilise efficacement l'espace de stockage ) et mysql a des fonctions find_in_set et field. , qui sont pratiques Utilisés dans les requêtes ;
Inconvénients : Changer la définition d'une colonne est coûteux, nécessite une modification de la table et ne peut pas être configuré pour effectuer une recherche dans l'index
Opération au niveau du bit sur les colonnes entières :
Une alternative à set : utilisez des entiers pour envelopper une série de bits : 8 bits peuvent être regroupés dans tinyint et utilisés dans des opérations au niveau du bit pour définir des constantes de nom pour les bits afin de simplifier ce travail, mais cela rend l'instruction de requête. plus difficile à écrire et à comprendre.
4.1.6 Sélectionner l'identifiant
Colonne d'identification : colonne à croissance automatique [Source]
1) Il n'est pas nécessaire d'insérer manuellement des valeurs. , le système fournit des valeurs de séquence par défaut ; 2) Il n'est pas nécessaire qu'il corresponde à la clé primaire ; 3) Il doit s'agir d'une clé unique
4) Au plus une par table ; être uniquement numérique ; 5) Il peut être transmis set auto_increment_increment=3;
Lors de la sélection du type de colonne d'identité
Tenez compte du type de stockage et de la manière dont MySQL effectue les calculs et les comparaisons. sur ce type. Après avoir déterminé, assurez-vous d'utiliser le même type dans toutes les tables associées, et les types doivent correspondre exactement 🎜>
Conseils :
1. L'entier est généralement le meilleur choix, il est rapide et peut utiliser auto_increment2. Enum et définir des types, stockage d'informations fixes 3. Chaînes : évitez, la consommation d'espace est plus lente que les nombres, soyez particulièrement prudent avec les tables myisam (compression de chaîne par défaut, requête lente) 1) Caractères complètement "aléatoires" Les nouvelles valeurs générées par la fonction chaîne MD5/SHA1/UUID seront arbitrairement distribuées dans un grand espace, provoquant le ralentissement de l'insertion et de certaines sélections :La valeur insérée est écrite de manière aléatoire à différentes positions dans l'index, et l'insertion deviendra plus lente (la fragmentation de l'index cluster à accès aléatoire sur le disque divisé en pages devient plus lente) ; , les lignes logiquement adjacentes sont réparties à différents endroits sur le disque et la mémoire ; les valeurs aléatoires provoquent une modification de l'effet cache sur toutes les instructions de requête de type (invalide le principe de localité d'accès sur lequel le cache fonctionne)
index clusterisé , la structure séquentielle réellement stockée et la structure physique du stockage des données Cohérent, de manière générale, il n'y a qu'une seule structure de séquence physique, et il ne peut y avoir qu'un seul index clusterisé pour une table. Généralement, la clé par défaut est la clé primaire. Si vous définissez la clé primaire, le système ajoutera un index clusterisé pour vous par défaut ; >Index non clusteriséL'ordre physique des enregistrements n'est pas nécessairement lié à l'ordre logique, et n'a rien à voir avec la structure physique du stockage des données ; il peut y avoir de nombreux index non clusterisés correspondant à une table ; des contraintes de différentes colonnes, des index non clusterisés avec des exigences différentes peuvent être établis
2) Stockez l'uuid, supprimez le symbole - ou utilisez unhex pour convertir la valeur de l'uuid en un nombre de 16 octets et stockez dans la colonne binaire (16), formatez-le au format hexadécimal via la fonction hex lors de la récupération Dans l'ordre, il est préférable d'incrémenter l'entier Méfiez-vous du schéma généré automatiquement :
Performances sérieuses ; problèmes, grands varchar, colonnes associées de différents types
orm stockera tout type de données dans n'importe quel type de stockage de données back-end. Il n'est pas conçu pour utiliser un meilleur type de stockage. Parfois, il utilise une ligne distincte pour chaque attribut de chaque objet. . Définir à l'aide du contrôle de version basé sur l'horodatage entraîne plusieurs versions d'un seul attribut ; des compromis
4.1.7 Type spécial de données : vide
Articles associés :
[Base de données MySQL] Chapitre 3 Interprétation : Analyse des performances du serveur (Partie 1)
[Base de données MySQL] Chapitre 3 Interprétation : Analyse des performances du serveur (Partie 2)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!