
Maison >Java >javaDidacticiel >Un article pour vous aider à comprendre l'analyse et l'utilisation du pool de threads JDK
Un article pour vous aider à comprendre l'analyse et l'utilisation du pool de threads JDK

- 无忌哥哥original
- 2018-07-20 10:24:121574parcourir
1. Pourquoi utiliser le pool de threads
Une fonction très importante dans la programmation multithread est d'exécuter des tâches, et il existe de nombreuses façons d'exécuter des tâches. , pourquoi devons-nous utiliser un pool de threads ? Ci-dessous, nous utilisons la fonction de programmation Socket pour traiter les demandes et analyser chaque méthode d'exécution des tâches.
1.1 Exécution en série des tâches
Lorsque le Socket détecte une connexion du client, il traite chaque connexion client séquentiellement via la méthode handleSocket. Lorsque le traitement est terminé, il continue d'écouter. Le code est le suivant :
ServerSocket serverSocket = new ServerSocket();
SocketAddress endpoint = new InetSocketAddress(host, port);
serverSocket.bind(endpoint,1023);
while (!isStop) {
Socket socket = serverSocket.accept();
handleSocket(socket);
}Les défauts de cette méthode sont très évidents : Lorsque j'ai plusieurs requêtes clients, pendant que le serveur traite une requête, les autres requêtes doivent attendre la précédente demande traitée . Ceci est presque indisponible dans les situations de forte concurrence.
1.2 Créer un fil de discussion pour chaque tâche
Optimiser le problème ci-dessus : créez un fil de discussion pour chaque demande client pour traiter la demande, le fil principal n'a qu'à créer le fil de discussion, et vous pouvez ensuite Continuer à prendre en charge les demandes des clients. L'organigramme est le suivant : 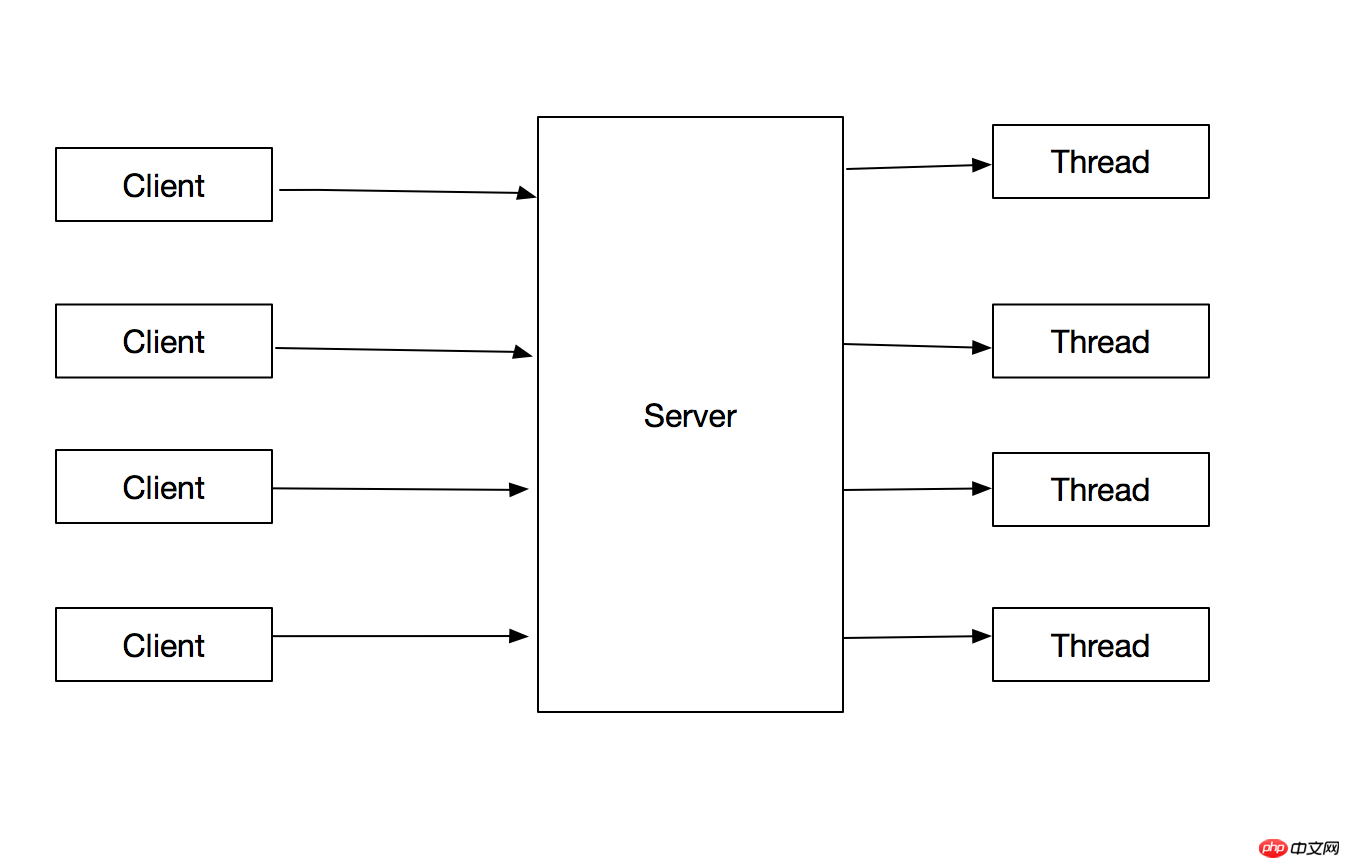
Le code est le suivant :
ServerSocket serverSocket = new ServerSocket();
SocketAddress endpoint = new InetSocketAddress(host, port);
serverSocket.bind(endpoint,1023);
while (!isStop) {
Socket socket = serverSocket.accept();
new SocketHandler(socket, THREAD_NAME_PREFIX + threadIndex++).start();
}Cette méthode présente les avantages suivants :
1.Séparez l'opération de traitement des connexions client du thread principal, afin que la boucle principale puisse répondre plus rapidement à la requête suivante.
2. Les opérations de traitement des connexions clients sont parallèles, ce qui améliore le débit du programme.
Cependant, cette méthode présente les inconvénients suivants :
1. Le thread qui traite la demande doit être thread-safe
2 La création et la destruction des threads nécessitent une surcharge, lorsqu'un grand nombre de threads sont créés, une grande quantité de ressources informatiques sera consommée
3. Lorsque le nombre de processeurs disponibles est inférieur au nombre de threads exécutables, les threads supplémentaires occuperont des ressources mémoire et apporteront problèmes de récupération de place, et il y aura une surcharge de performances importante lorsqu'un grand nombre de threads sont en concurrence pour les ressources CPU
4. JVM. Cette limite supérieure varie selon les plates-formes et est soumise à de nombreux facteurs, notamment les paramètres de démarrage de la JVM, la taille de la mémoire occupée par chaque thread, etc. Si ces limites sont dépassées, une exception MOO sera levée.
1.3 Utiliser un pool de threads pour gérer les requêtes des clients
Pour les problèmes qui surviennent dans la version 1.2, la meilleure solution est d'utiliser un pool de threads pour exécuter des tâches, ce qui peut limiter le nombre total de threads créé. Cela évite les problèmes de la version 1.2. L'organigramme est le suivant : 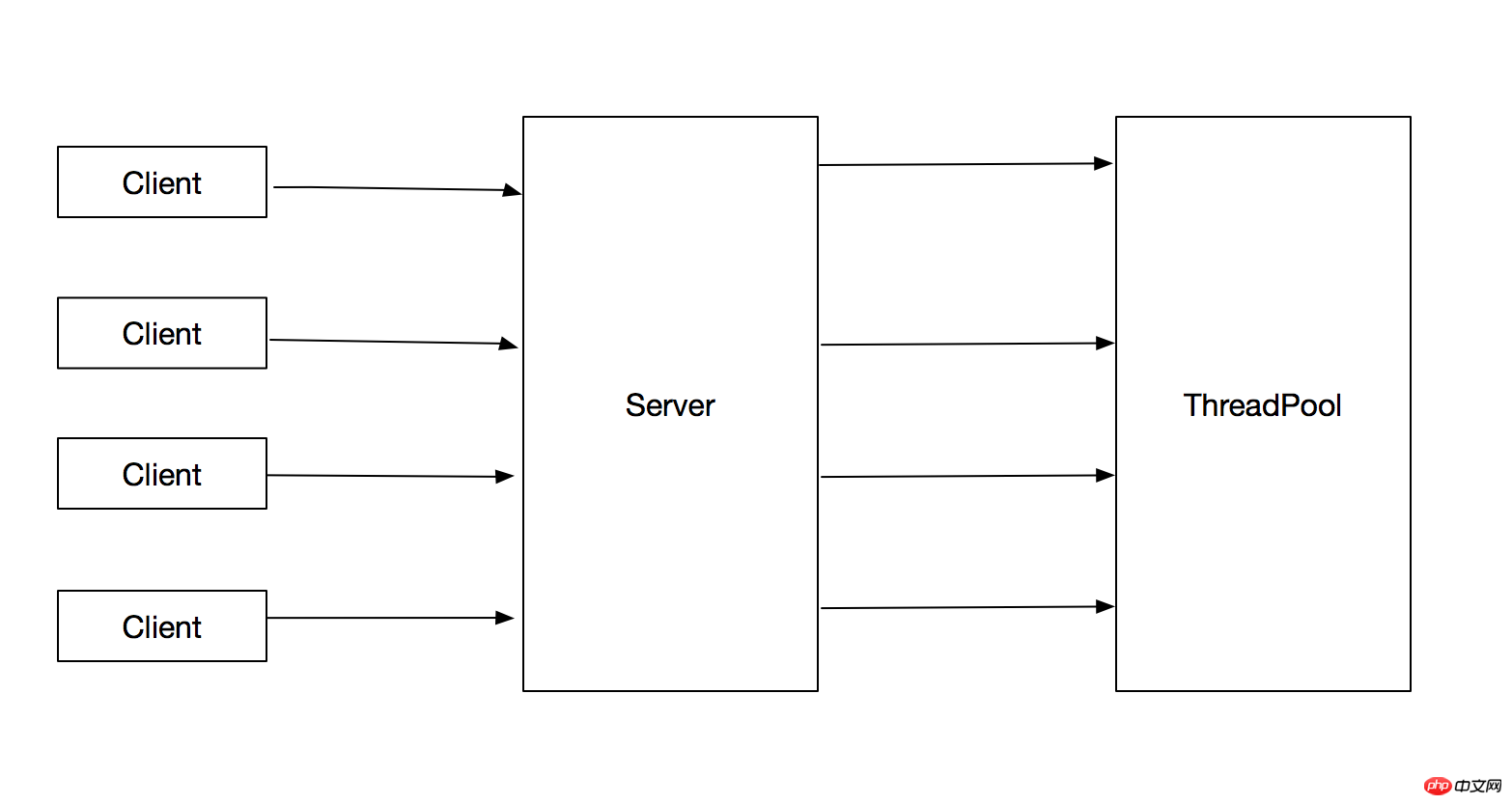
La méthode de traitement est la suivante :
ServerSocket serverSocket = new ServerSocket();
SocketAddress endpoint = new InetSocketAddress(host, port);
serverSocket.bind(endpoint,1023);
while (!isStop) {
Socket socket = serverSocket.accept();
executorService.execute(new SocketHandler(socket, THREAD_NAME_PREFIX + threadIndex++));
}Cette méthode présente les avantages suivants :
1. La soumission des tâches et l'exécution des tâches sont séparées
2. Le thread qui exécute la tâche peut être réutilisé, réduisant ainsi la surcharge de création et de destruction du thread. En même temps, lorsque la tâche arrive, le thread créé peut être directement. utilisé pour exécuter la tâche, ce qui améliore également la vitesse de réponse du programme.
2. Introduction au pool de threads en Java
L'implémentation du pool de threads en Java est basée sur le modèle producteur-consommateur La fonction du pool de threads combine la soumission de tâches et. l'achèvement des tâches. Séparation de l'exécution, le processus de soumission des tâches est le producteur et le processus d'exécution de la tâche est le processus consommateur . Pour une analyse spécifique, voir analyse du code source. L'interface de niveau supérieur du pool de threads Java est Executor, et le code source est le suivant :
public interface Executor {
void execute(Runnable command);
}Cette interface est l'interface de niveau supérieur implémentée par tous les pools de threads. Elle stipule que la tâche acceptable. type est la classe d'implémentation Runnable, mais la tâche d'exécution spécifique La logique est définie par la classe d'implémentation du pool de threads elle-même, par exemple :
peut utiliser le thread principal pour exécuter des tâches en série,
peut également créer un nouveau thread pour chaque tâche
ou créer un groupe à l'avance Les threads sont extraits d'un groupe de threads à chaque fois qu'une tâche est exécutée, etc.
La stratégie d'exécution du pool de threads a principalement les aspects suivants :
1. Dans quel thread Exécuter les tâches dans
2. Dans quel ordre les tâches doivent-elles être exécutées (FIFO, LIFO, priorité ?)
3. 🎜>4. Le nombre maximum de tâches peuvent être en attente d'exécution dans la file d'attente
5. Comment rejeter les tâches nouvellement soumises lorsque la file d'attente atteint la valeur maximale
6. après avoir exécuté une tâche ?
public static ExecutorService newFixedThreadPool(int nThreads) 将会创建一个固定大小的线程池,每当有新任务提交的时候,当线程总数没有达到核心线程数的时候,为每个任务创建一个新线程,当线程的个数到达最大值后,重用之前创建的线程,当线程因为未知异常而停止时候,将会重现创建一个线程作为补充。 public static ExecutorService newCachedThreadPool() 根据需求创建线程的个数,当线程数大于任务数的时候,将会注销多余的线程 public static ExecutorService newSingleThreadExecutor() 创建一个单线程的线程池 public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) 创建一个可执行定时任务的线程池Dans l'exemple ci-dessus, l'état d'exécution de toutes les tâches soumises est invisible après avoir été soumises au pool de threads, c'est-à-dire que le thread principal ne peut pas savoir si les tâches soumises sont exécutés. Fin ou résultat de l’exécution. Pour résoudre ce problème, Java fournit des interfaces de tâches Future et Callable qui peuvent renvoyer des données.
L'interface Callable fournit la fonction de renvoyer les données de la tâche et de lancer des exceptions, et est définie comme suit :
public interface Callable<V> {
V call() throws Exception;
}Toutes les méthodes de soumission dans ExecutorService renverront un objet Future et son interface est définie comme suit : public interface Future<V> {
取消任务执行,当mayInterruptIfRunning为true,interruptedthisthread
boolean cancel(boolean mayInterruptIfRunning);
返回此任务是否在执行完毕之前被取消执行
boolean isCancelled();
返回此任务是否已经完成,包括正常结束,异常结束以及被cancel
boolean isDone();
返回执行结果,当任务没有执行结束的时候,等待
V get() throws InterruptedException, ExecutionException;
}
3.使用线程池可能出现的问题
1.线程饥饿死锁
在单线程的Executor中,如果Executor中执行的一个任务中,再次提交任务到同一个Executor中,并且等待这个任务执行完毕,那么就会发生死锁问题。如下demo中所示:
public class ThreadDeadLock {
private static final ExecutorService EXECUTOR_SERVICE = Executors.newSingleThreadExecutor();
public static void main(String[] args) throws Exception {
System.out.println("Main Thread start.");
EXECUTOR_SERVICE.submit(new DeadLockThread());
System.out.println("Main Thread finished.");
}
private static class DeadLockThread extends Thread{
@Override
public void run() {
try {
System.out.println("DeadLockThread start.");
Future future = EXECUTOR_SERVICE.submit(new DeadLockThread2());
future.get();
System.out.println("DeadLockThread finished.");
} catch (Exception e) {
}
}
}
private static class DeadLockThread2 extends Thread {
@Override
public void run() {
try {
System.out.println("DeadLockThread2 start.");
Thread.sleep(1000 * 10);
System.out.println("DeadLockThread2 finished.");
} catch (Exception e) {
}
}
}
}输出结果为:
Main Thread start. Main Thread finished. DeadLockThread start.
对于多个线程的线程池,如果所有正在执行的线程都因为等待处于工作队列中的任务执行而阻塞,那么就会发生线程饥饿死锁。
当往线程池中提交有依赖的任务时,应清楚的知道可能会出现的线程饥饿死锁风险。==应考虑是否将依赖的task提交到不同的线程池中==
或者使用无界的线程池。
==只有当任务相对独立时,设置线程池大小和工作队列的大小才是合理的,否则有可能会出现线程饥饿死锁==
2.任务运行时间过长
任务执行时间过长会影响线程池的响应时间,当运行时间长的任务远大于线程池线程的个数时,会出现所有线程都在执行运行时间长的任务,从而影响对其他任务的响应。
解决办法:
1.通过限定任务等待的时长,而不要无限期等待下去,当等待超时的时候,可以将任务标记为失败,或者重新放到线程池中。
2.当线程池中阻塞任务过多的时,应该考虑扩大线程池的大小
4.线程池大小的设置
线程池的大小依赖于提交任务的类型以及服务器的可用资源,线程池的大小应该避免设置过大或者过小,当线程设置过打的时候可能会有资源耗尽的风险,线程池设置过小会有可用cpu空闲从而影响系统吞吐量。
影响线程池大小的资源有很多,比如CPU、内存、数据库链接池等,只需要计算资源可用总资源 / 每个任务需要的资源,取最小值,即可得出线程池的上限。
线程池的最小值应该大于可用的CPU数量。
4.java中常用线程池源码分析-ThreadPoolExecutor
ThreadPoolExecutor线程池是比较常用的一个线程池实现类,通过Executors工具类创建的线程池中,其具体实现类是ThreadPoolExecutor。首先我们可以看下ThreadPoolExecutor的构造函数如下:
public ThreadPoolExecutor(
int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)下面分别对构造函数中的各个参数对应的策略进行分析:
1.线程的创建与销毁
首先构造函数中corePoolSize、maximumPoolSize、keepAliveTime和unit参数影响线程的创建和销毁。其中corePoolSize为核心线程数,当第一次提交任务的时候如果正在执行的线程数小于corePoolSize,则新建一个线程执行task,如果已经超过corePoolSize,则将任务放到任务队列中等待执行。当任务队列的个数到达上限的时候,并且工作线程数量小于maximumPoolSize,则继续创建线程执行工作队列中的任务。当任务的个数小于maximumPoolSize的时候,将会把空闲的线程标记为可回收的垃圾线程。对于以下代码段测试此功能:
public class ThreadPoolTest {
private static ThreadPoolExecutor executorService = new ThreadPoolExecutor(3, 6,100, TimeUnit.SECONDS, new LinkedBlockingQueue<>(3));
public static void main(String[] args) throws Exception {
for (int i = 0; i< 9; i++) {
executorService.submit(new Task());
System.out.println("Active thread:" + executorService.getActiveCount() + ".Task count:" + executorService.getTaskCount() + ".TaskQueue size:" + executorService.getQueue().size());
}
}
private static class Task extends Thread {
@Override
public void run() {
try {
Thread.sleep(1000 * 100);
} catch (Exception e) {
}
}
}
}输出结果为:
Active thread:1.Task count:1.TaskQueue size:0 Active thread:2.Task count:2.TaskQueue size:0 Active thread:3.Task count:3.TaskQueue size:0 Active thread:3.Task count:4.TaskQueue size:1 Active thread:3.Task count:5.TaskQueue size:2 Active thread:3.Task count:6.TaskQueue size:3 Active thread:4.Task count:7.TaskQueue size:3 Active thread:5.Task count:8.TaskQueue size:3 Active thread:6.Task count:9.TaskQueue size:3
2.任务队列
在ThreadPoolExecutor的构造函数中可以传入保存任务的队列,当新提交的任务没有空闲线程执行时候,会将task保存到此队列中。保存的顺序是根据插入的顺序或者Comparator来排序的。
3.饱和策略
ThreadPoolExecutor.AbortPolicy 抛出RejectedExecutionException ThreadPoolExecutor.CallerRunsPolicy 将任务的执行交给调用者,即将本该异步执行的任务变成同步执行。
4.线程工厂
当线程池需要创建线程的时候,默认是使用线程工厂方法来创建线程的,通常情况下我们通过指定线程工厂的方式来为线程命名,便于出现线程安全问题时候来定位问题。
5.线程池最佳实现
1.项目中所有的线程应该都有线程池来提供,不允许自行创建线程
2.尽量不要用Executors来创建线程,而是使用ThreadPoolExecutor来创建
Executors有以下问题:
1)FixedThreadPool 和 SingleThreadPool: 允许的请求队列长度为 Integer.MAX_VALUE,可能会堆积大量的请求,从而导致 OOM。 2)CachedThreadPool 和 ScheduledThreadPool: 允许的创建线程数量为 Integer.MAX_VALUE,可能会创建大量的线程,从而导致 OOM。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment convertir facultatif en flux dans Java 8 ?
- Comment résoudre les problèmes de redirection de sortie à l'aide du runtime Java ?
- Comment valider l'entrée de cellule JTable pour les valeurs entières non positives ?
- Comment valider une entrée entière non positive dans les cellules JTable ?
- Conception de classe avancée à l'aide de classes scellées Java