
Maison >interface Web >js tutoriel >Comment implémenter l'affichage d'un terminal Web multi-utilisateurs à l'aide de node.js
Comment implémenter l'affichage d'un terminal Web multi-utilisateurs à l'aide de node.js
- 亚连original
- 2018-06-23 16:11:471409parcourir
Cet article présente principalement le support de node.js pour la mise en œuvre de terminaux Web multi-utilisateurs et la solution pour assurer la sécurité des terminaux Web. Apprenons et référons-nous-y ensemble.
Le terminal (ligne de commande), en tant que fonction courante des IDE locaux, dispose d'un support très puissant pour les opérations git et les opérations sur les fichiers des projets. Pour WebIDE, en l'absence de pseudo-terminal web, fournir uniquement une interface de ligne de commande encapsulée est totalement incapable de satisfaire les développeurs. Ainsi, afin d'offrir une meilleure expérience utilisateur, le développement de pseudo-terminaux web a été mis sur le devant de la scène. ordre du jour.
Recherche
Le terminal, à notre connaissance, est similaire à un outil de ligne de commande. En termes simples, il s'agit d'un processus qui. peut exécuter un shell. Chaque fois que vous entrez une série de commandes sur la ligne de commande et appuyez sur Entrée, le processus terminal créera un processus enfant pour exécuter la commande saisie. Le processus terminal surveille la sortie du processus enfant via l'appel système wait4() et génère des sorties. via la sortie standard exposée.
Si vous implémentez une fonction de terminal similaire à la localisation côté Web, vous devrez peut-être faire plus : garantie de délai et de fiabilité du réseau, expérience utilisateur shell aussi proche que possible de la localisation, largeur et hauteur de l'interface utilisateur du terminal Web et Adaptation des informations de sortie, contrôle d'accès de sécurité et gestion des autorités, etc. Avant d'implémenter spécifiquement le terminal Web, il est nécessaire d'évaluer lesquelles de ces fonctions sont les plus essentielles : l'implémentation fonctionnelle du shell, l'expérience utilisateur et la sécurité (le terminal Web est une fonction fournie dans le serveur en ligne). , la sécurité doit donc être garantie). Ce n'est que sous réserve d'assurer ces deux fonctions que le pseudo-terminal Web pourra être officiellement lancé.
Ce qui suit considère d'abord l'implémentation technique de ces deux fonctions (la technologie côté serveur utilise nodejs) :
Le module natif du nœud fournit le module repl, qui peut être utilisé pour implémenter une saisie interactive et effectue la sortie et fournit également une fonction de complétion des onglets, un style de sortie personnalisé et d'autres fonctions. Cependant, il ne peut exécuter que des commandes liées au nœud, il ne peut donc pas atteindre l'objectif d'exécuter le shell système. Le module natif du nœud child_porcess fournit spawn, qui encapsule. la libuv sous-jacente. La fonction uv_spawn utilise les appels système sous-jacents fork et execvp pour exécuter les commandes shell. Cependant, il ne fournit pas d'autres fonctionnalités du pseudo-terminal, comme la complétion automatique des tabulations, les touches fléchées pour afficher les commandes historiques, etc.
Il est donc impossible d'implémenter un pseudo-terminal en utilisant le module natif du nœud côté serveur, et nous devons continuer à explorer les pseudo-terminaux Le principe du terminal et la direction de mise en œuvre du côté nœud.
Pseudo terminal
Le pseudo terminal n'est pas un vrai terminal, mais un "service" fourni par le noyau. Les services de terminal comprennent généralement trois couches :
L'interface d'entrée et de sortie de niveau supérieur fournie pour les périphériques de caractères, la discipline de ligne de niveau intermédiaire et le pilote matériel de niveau inférieur
Parmi eux, le l'interface de niveau supérieur passe souvent par l'implémentation de fonctions d'appel système, telles que (lecture, écriture) ; le pilote matériel sous-jacent est responsable de la communication entre les périphériques maître et esclave du pseudo-terminal, qui est fournie par la discipline de ligne ; relativement abstrait, mais en fait il est responsable de la fonction "Traitement" des informations d'entrée et de sortie, comme le traitement des caractères d'interruption (ctrl + c) et certains caractères de restauration (retour arrière et suppression) pendant le processus d'entrée, tout en convertissant la nouvelle ligne de sortie caractère n à rn, etc.
Un pseudo terminal est divisé en deux parties : le périphérique maître et le périphérique esclave. Ils sont connectés en bas via un tuyau bidirectionnel (pilote matériel) qui implémente la discipline de ligne par défaut. Toute entrée du pseudo-terminal maître est répercutée sur l'esclave et vice versa. Les informations de sortie du périphérique esclave sont également envoyées au périphérique maître via un tube, de sorte que le shell puisse être exécuté dans le périphérique esclave du pseudo-terminal pour terminer la fonction du terminal.
Le périphérique esclave du pseudo-terminal peut véritablement simuler la complétion des onglets du terminal et d'autres commandes spéciales du shell. Par conséquent, en partant du principe que le module natif du nœud ne peut pas répondre aux besoins, nous devons nous concentrer sur la couche inférieure et. voir Voir quelles fonctions le système d'exploitation fournit. Actuellement, la bibliothèque glibc fournit l'interface posix_openpt, mais le processus est un peu lourd :
Utilisez posix_openpt pour ouvrir un périphérique maître pseudo-terminal accorder définir les autorisations du périphérique esclave unlockpt déverrouiller le périphérique esclave correspondant obtenir le nom du périphérique esclave (similaire à /dev/pts /123) Le périphérique maître (esclave) lit et écrit, effectue des opérations
Par conséquent, une bibliothèque pty avec une meilleure encapsulation a émergé, et toutes les fonctions ci-dessus peuvent être réalisées via juste une fonction forkpty. En écrivant un module d'extension node C++ et en utilisant la bibliothèque pty pour implémenter un terminal qui exécute la ligne de commande depuis le périphérique dans un pseudo-terminal.
Concernant la question de la sécurité des pseudo-terminaux, nous en parlerons en fin d'article.
Idées d'implémentation du pseudo terminal
Selon les caractéristiques des dispositifs maître et esclave du pseudo terminal, nous gérons le pseudo terminal dans le processus parent où se trouve le périphérique maître Le cycle de vie et ses ressources sont exécutés dans le sous-processus du périphérique esclave. Les informations et les résultats lors de l'exécution sont transmis au périphérique maître via un canal bidirectionnel, et le processus de. le périphérique maître fournit une sortie standard vers l'extérieur.
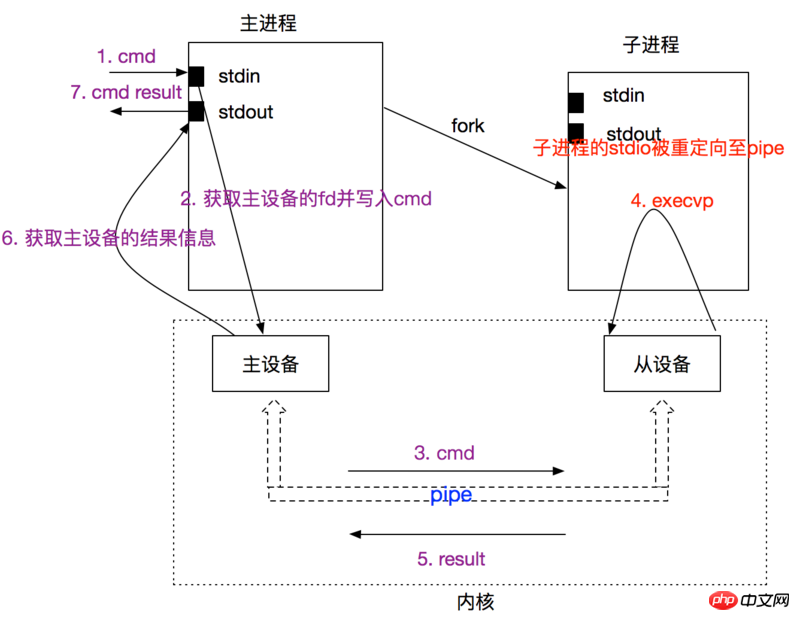
Découvrez les idées d'implémentation de pty.js ici :
pid_t pid = pty_forkpty(&master, name, NULL, &winp);
switch (pid) {
case -1:
return Nan::ThrowError("forkpty(3) failed.");
case 0:
if (strlen(cwd)) chdir(cwd);
if (uid != -1 && gid != -1) {
if (setgid(gid) == -1) {
perror("setgid(2) failed.");
_exit(1);
}
if (setuid(uid) == -1) {
perror("setuid(2) failed.");
_exit(1);
}
}
pty_execvpe(argv[0], argv, env);
perror("execvp(3) failed.");
_exit(1);
default:
if (pty_nonblock(master) == -1) {
return Nan::ThrowError("Could not set master fd to nonblocking.");
}
Local<Object> obj = Nan::New<Object>();
Nan::Set(obj,
Nan::New<String>("fd").ToLocalChecked(),
Nan::New<Number>(master));
Nan::Set(obj,
Nan::New<String>("pid").ToLocalChecked(),
Nan::New<Number>(pid));
Nan::Set(obj,
Nan::New<String>("pty").ToLocalChecked(),
Nan::New<String>(name).ToLocalChecked());
pty_baton *baton = new pty_baton();
baton->exit_code = 0;
baton->signal_code = 0;
baton->cb.Reset(Local<Function>::Cast(info[8]));
baton->pid = pid;
baton->async.data = baton;
uv_async_init(uv_default_loop(), &baton->async, pty_after_waitpid);
uv_thread_create(&baton->tid, pty_waitpid, static_cast<void*>(baton));
return info.GetReturnValue().Set(obj);
}Créez d'abord le périphérique maître-esclave via pty_forkpty (l'implémentation posix de forkpty, compatible avec des systèmes tels que sunOS et unix), puis après avoir défini les autorisations (setuid, setgid) dans le processus enfant, exécutez le appel système pty_execvpe (encapsulation de execvpe) , alors les informations d'entrée du périphérique principal seront exécutées ici (le fichier exécuté par le processus enfant est sh et écoutera stdin
Le processus parent expose les objets associés) ; à la couche nœud, telle que le fd du périphérique principal (via Le fd peut créer un objet net.Socket pour la transmission de données bidirectionnelle) et enregistrer la file d'attente de messages de libuv &baton->async Lorsque le processus enfant se termine, il se termine. déclenche le message &baton->async et exécute la fonction pty_after_waitpid ;
Enfin, le processus parent crée un processus enfant en appelant uv_thread_create pour écouter le message de sortie du processus enfant précédent (en exécutant l'appel système wait4, bloquant le processus à l'écoute d'un pid spécifique, et les informations de sortie sont stockées dans le troisième paramètre), encapsulées par la fonction pty_waitpid. La fonction wait4 est ajoutée et uv_async_send(&baton->async) est exécuté à la fin de la fonction pour déclencher le message.
Après avoir implémenté le modèle pty au niveau de la couche inférieure, certaines opérations stdio doivent être effectuées au niveau de la couche nœud. Étant donné que le périphérique principal du pseudo-terminal est créé en exécutant un appel système dans le processus parent et que le descripteur de fichier du périphérique principal est exposé à la couche nœud via fd, alors l'entrée et la sortie du pseudo-terminal sont également lu et écrit selon le fd pour créer le type de fichier correspondant, tel que PIPE, FILE à compléter. En fait, au niveau du système d'exploitation, le dispositif maître du pseudo-terminal est considéré comme un PIPE, avec une communication bidirectionnelle. Créez un socket au niveau de la couche nœud via net.Socket(fd) pour réaliser des E/S bidirectionnelles du flux de données. Le périphérique esclave du pseudo-terminal a également la même entrée que le périphérique maître, de sorte que la commande correspondante soit exécutée dans le sous-terminal. processus, et la sortie du sous-processus est également reflétée dans le périphérique principal via PIPE, puis déclenchera l'événement de données de l'objet Socket de la couche nœud.
La description de l'entrée et de la sortie du processus parent, du périphérique maître, du processus enfant et du périphérique esclave ici est un peu déroutante, je vais donc l'expliquer ici. La relation entre le processus parent et le périphérique principal est la suivante : le processus parent crée le périphérique principal via un appel système (peut être considéré comme un PIPE) et obtient le fd du périphérique principal. Le processus parent réalise les entrées et les sorties vers le processus enfant (périphérique esclave) en créant le socket de connexion du fd. Une fois le processus enfant créé via forkpty, l'opération login_tty est effectuée et les fichiers stdin, stderr et stderr du processus enfant sont réinitialisés et tous sont copiés sur le fd du périphérique esclave (l'autre extrémité du PIPE). Par conséquent, l'entrée et la sortie du processus enfant sont associées au fd du périphérique esclave. Les données de sortie du processus enfant passent par PIPE et les commandes du processus parent sont lues à partir de PIPE. Pour plus de détails, veuillez consulter l'implémentation de forkpty dans la littérature de référence
De plus, la bibliothèque pty fournit des paramètres de taille de pseudo-terminal, afin que nous puissions ajuster les informations de disposition des informations de sortie du pseudo-terminal via des paramètres, donc ceci fournit également des commandes de réglage côté Web. Pour la fonction de largeur et de hauteur de ligne, il vous suffit de définir la taille de la fenêtre du pseudo-terminal sur la couche pty.
Garantie de sécurité du terminal Web
Il n'y a aucune garantie de sécurité lors de l'implémentation de l'arrière-plan du pseudo-terminal basé sur la bibliothèque pty fournie par la glibc. Nous souhaitons exploiter directement un répertoire sur le serveur via le terminal Web, mais nous pouvons obtenir directement les autorisations root via le fond du pseudo-terminal. Ceci est intolérable pour le service car cela affecte directement la sécurité du serveur. est : un "système" dans lequel les utilisateurs sont en ligne en même temps, les droits d'accès de chaque utilisateur peuvent être configurés, des répertoires spécifiques sont accessibles, les commandes bash peuvent être configurées en option, les utilisateurs sont isolés les uns des autres, les utilisateurs ignorent le courant environnement, et l’environnement est simple et facile à déployer.
Le choix technologique le plus approprié est Docker. En tant qu'isolation au niveau du noyau, il peut utiliser pleinement les ressources matérielles et est très pratique pour mapper les fichiers liés à l'hôte. Mais Docker n'est pas tout-puissant. Si le programme s'exécute dans un conteneur Docker, alors l'attribution d'un conteneur à chaque utilisateur deviendra beaucoup plus compliquée, et il n'est pas sous le contrôle du personnel d'exploitation et de maintenance. C'est ce qu'on appelle DooD (. docker hors de docker). )--Utilisez des fichiers binaires tels que le volume "/usr/local/bin/docker" et utilisez la commande docker de l'hôte pour ouvrir l'image sœur afin d'exécuter le service de build. Il existe de nombreuses lacunes dans l'utilisation du mode docker-in-docker qui sont souvent évoquées dans l'industrie, notamment au niveau du système de fichiers, que l'on retrouve dans les références. Par conséquent, la technologie Docker n’est pas adaptée pour résoudre les problèmes de sécurité d’accès des utilisateurs aux services déjà exécutés dans des conteneurs.
Ensuite, nous devons envisager une solution mono-machine. À l'heure actuelle, l'auteur ne pense qu'à deux solutions :
Commander l'ACL, implémenter un chroot bash restreint via une liste blanche de commandes, créer un utilisateur système pour chaque utilisateur et emprisonner la portée d'accès de l'utilisateur
Tout d'abord, command La méthode de liste blanche est celle qui devrait être éliminée. Premièrement, elle ne peut pas garantir que le bash des différentes versions de Linux est la même ; deuxièmement, elle ne peut pas finalement épuiser efficacement toutes les commandes, en raison de la fonction de complétion des commandes d'onglets fournie ; par le pseudo-terminal et l'existence de caractères spéciaux tels que delete , ne peuvent pas correspondre efficacement à la commande actuellement saisie. Par conséquent, la méthode de la liste blanche présente trop de failles et devrait être abandonnée.
bash restreint, déclenché par /bin/bash -r, peut restreindre les utilisateurs explicitement au "répertoire cd", mais il présente de nombreux inconvénients :
Insuffisant pour permettre l’exécution de logiciels totalement non fiables. Lorsqu'une commande qui s'avère être un script shell est exécutée, rbash désactive toutes les restrictions créées dans le shell pour exécuter le script. Lorsque les utilisateurs exécutent bash ou dash depuis rbash, ils obtiennent un shell illimité. Il existe de nombreuses façons de sortir d'un shell bash restreint, qui ne sont pas facilement prévisibles.
Finalement, il semble n'y avoir qu'une seule solution, qui est le chroot. chroot modifie le répertoire racine de l'utilisateur et exécute la commande dans le répertoire racine spécifié. Vous ne pouvez pas sortir du répertoire racine spécifié, vous ne pouvez donc pas accéder à tous les répertoires du système d'origine en même temps, chroot créera une structure de répertoires système isolée du système d'origine, de sorte que diverses commandes du système d'origine ne pourront pas être utilisées dans le « nouveau système » car il est nouveau et vide enfin, il est isolé et transparent lorsqu'il est utilisé par plusieurs utilisateurs, ce qui répond pleinement à nos besoins.
Nous avons donc finalement choisi chroot comme solution de sécurité pour les terminaux web. Cependant, l'utilisation de chroot nécessite beaucoup de traitements supplémentaires, notamment la création de nouveaux utilisateurs, mais également l'initialisation des commandes. Il est également mentionné ci-dessus que le « nouveau système » est vide et qu'il n'y a pas de fichiers binaires exécutables, tels que « ls, pmd », etc., donc l'initialisation du « nouveau système » est nécessaire. Cependant, de nombreux fichiers binaires sont non seulement liés statiquement à de nombreuses bibliothèques, mais s'appuient également sur des bibliothèques de liens dynamiques (dll) lors de l'exécution. Pour cette raison, il est également nécessaire de trouver de nombreuses dll dont dépend chaque commande, ce qui est extrêmement fastidieux. Afin d'aider les utilisateurs à se débarrasser de ce processus ennuyeux, le jailkit a vu le jour.
jailkit, vraiment simple à utiliser
jailkit, comme son nom l'indique, est utilisé pour emprisonner les utilisateurs. Le jailkit utilise chroot en interne pour créer le répertoire racine de l'utilisateur et fournit une série d'instructions pour initialiser et copier les fichiers binaires et toutes leurs dll. Ces fonctions peuvent être exploitées via des fichiers de configuration. Par conséquent, dans le développement réel, jailkit est utilisé avec des scripts shell d'initialisation pour réaliser l'isolation du système de fichiers.
Le shell d'initialisation fait ici référence au script de prétraitement. Puisque chroot doit définir le répertoire racine pour chaque utilisateur, un utilisateur correspondant est créé dans le shell pour chaque utilisateur avec des autorisations de ligne de commande et transmis le fichier de configuration du jailkit. copie les fichiers binaires de base et leurs DLL, tels que les commandes shell de base, git, vim, ruby, etc. ; enfin, il effectue un traitement supplémentaire pour certaines commandes et réinitialise les autorisations.
Certaines compétences sont encore nécessaires dans le processus de traitement du mappage de fichiers entre le « nouveau système » et le système d'origine. L'auteur a déjà mappé des répertoires autres que le répertoire racine de l'utilisateur défini par chroot sous forme de liens symboliques. Cependant, lors de l'accès aux liens symboliques dans la prison, une erreur était toujours signalée et le fichier était introuvable. caractéristiques de chroot. , n'a pas l'autorisation d'accéder au système de fichiers en dehors du répertoire racine ; si le mappage est établi via des liens physiques, il est possible de modifier les fichiers de liens physiques dans le répertoire racine de l'utilisateur défini par chroot, mais les opérations impliquant la suppression, la création, etc. ne peut pas être effectuée correctement. Il est mappé au répertoire du système d'origine et le lien physique ne peut pas se connecter au répertoire, donc le lien physique ne répond pas aux exigences et est finalement implémenté via mount --bind, tel que mount --bind /home/ttt/abc /usr/local/abc, qui est protégé par les informations de répertoire (bloc) du répertoire monté (/usr/local/abc) et maintient la relation de mappage entre le répertoire monté et le répertoire monté en mémoire. L'accès à /usr/local/abc passera par la mémoire. La table de mappage interroge le bloc de /home/ttt/abc, puis effectue des opérations pour réaliser le mappage de répertoire.
Enfin, après avoir initialisé le "nouveau système", vous devez exécuter les commandes liées à la prison via le pseudo-terminal :
sudo jk_chrootlaunch -j /usr/local/jailuser/${creater} -u $ {creater} -x /bin/bashr
Après avoir ouvert le programme bash, communiquez avec l'entrée du terminal Web (via websocket) reçue par l'appareil principal via PIPE.
Ce qui précède est ce que j'ai compilé pour vous. J'espère que cela vous sera utile à l'avenir.
Articles associés :
À quoi devez-vous faire attention lorsque vous utilisez React.setState ?
Comment utiliser l'en-tête commun du page dans vue Componentisation (tutoriel détaillé)
Comment utiliser three.js Implémentation du cinéma 3D
Comment implémenter le composant de menu coulissant latéral dans Vue
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Une analyse approfondie du composant de groupe de liste Bootstrap
- Explication détaillée du currying de la fonction JavaScript
- Exemple complet de génération de mot de passe JS et de détection de force (avec téléchargement du code source de démonstration)
- Angularjs intègre l'interface utilisateur WeChat (weui)
- Comment basculer rapidement entre le chinois traditionnel et le chinois simplifié avec JavaScript et l'astuce permettant aux sites Web de prendre en charge le basculement entre les compétences en chinois simplifié et traditionnel_javascript