
Maison >base de données >tutoriel mysql >Comparaison SQL du décalage horaire entre deux enregistrements adjacents
Comparaison SQL du décalage horaire entre deux enregistrements adjacents
- jackloveoriginal
- 2018-06-14 16:14:064768parcourir
Dans l'après-midi, j'ai vu qu'un rapport statistique avait été généré pour le projet. La différence de temps statistique entre deux enregistrements adjacents enregistrés dans le tableau XX est
Les données du tableau sont les suivantes :
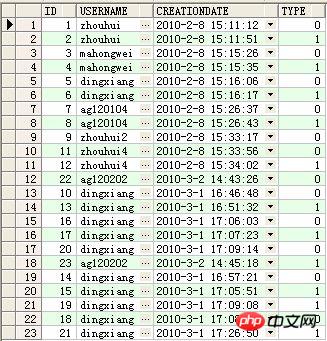
Il est obligatoire que la différence de temps de création entre deux enregistrements adjacents, comme le 1er et le 2ème enregistrement, soit calculée
c'est-à-dire
zhouhui 5 secondes
dingxiang 24 secondes
La demande est sortie et devait être résolue, puis j'ai trouvé un solution
Méthode 1 :
Code SQL 
sélectionnez t.username,(max( t.CREATIONDATE)-min( t.CREATIONDATE))*24*60*60,count(t.username)/2
de ofloginlog t
--où USERNAME = 'zhouhui '
groupe par t.username
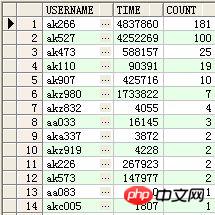
Les statistiques de temps de connexion des utilisateurs sont calculées par regroupement (c'est-à-dire la différence entre les deux enregistrements avant et après)
Rendu :

Explication que le dernier champ est utilisé pour compter le nombre de connexions utilisateurs.
oracle La valeur par défaut pour soustraire deux fois est le nombre de jours
oracle La valeur par défaut pour soustraire deux fois est jours*24, qui est le nombre d'heures de différence
oracle Le nombre de jours pour soustraire deux fois La valeur par défaut pour la soustraction est jours*24*60, qui est le nombre de minutes de différence
La valeur par défaut pour la soustraction oracle entre deux fois est le nombre de jours* 24*60*60, qui est le nombre de secondes de différence
Méthode 2 :
Code SQL
sélectionnez nom d'utilisateur, somme(b), compte (nom d'utilisateur) / 2
* 24 *60*60 commeb
-
décalage (type) sur (partition par nom d'utilisateur commander par
CREATIONDATE) lgtype, -
lag(CREATIONDATE) over(partition par nom d'utilisateur ordre par
CREATIONDATE) lgtime de ofloginlog t))
-
-- où USERNAME = 'zhouhui')
-
groupe par nom d'utilisateur
L'effet est le même et je ne le publierai pas ici Revu le SQL de base haha20100520 Certains changements dans les exigences exigent que le nombre de statistiques ne soit pas le même somme et moyenne des enregistrements TYPE 1 et 0, mais seulement la valeur de TYPE=0, Le regroupement SQL ne peut pas être comme ça J'y ai réfléchi et j'ai amélioré le code SQL
Sql <.>
sélectionnez
g.nom d'utilisateur, g.heure
, h.compte
de ( sélectionnez t.username,
-
étage((max(t.CREATIONDATE) - min(t.CREATIONDATE)) * 24 * 60 * 60) comme
heure de ofloginlog t, ofuser b
🎜>-
et t.username = b.username
groupe par t.username) g,
(sélectionnez t.username, count(t.username) as count
-
de du journal de connexion t
où g.username = h.username
- commander
par count
desc Résultats de la requête La différence de temps d'analyse est la différence entre les deux ensembles, et le nombre de statistiques ultérieures n'est que le nombre d'enregistrements avec une restriction distincte de TYPE=0. Le nombre de données statistiques est incohérent, il est donc difficile de le faire. implémentez-le dans un groupe. L'idée est d'implémenter USERNAME et TIME en premier. Les enregistrements comptent USERNAME et le nombre d'enregistrements qui satisfont TYPE = 0. Fusionnez les deux résultats via la relation en ligne de SELECT XX FROM A B 2 tables temporaires. ensemble de résultats fusionnés Cet article explique sql adjacent 2 Comparez le décalage horaire des enregistrements Pour plus de contenu connexe, veuillez faire attention au site Web PHP chinois.
Recommandations associées :
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!