
Maison >base de données >tutoriel mysql >Explication détaillée des raisons et des méthodes d'optimisation d'un décalage excessif affectant les performances lors d'une requête MySQL
Explication détaillée des raisons et des méthodes d'optimisation d'un décalage excessif affectant les performances lors d'une requête MySQL
- jackloveoriginal
- 2018-06-08 17:17:012270parcourir
la requête mysql utilise la commande select, combinée avec les paramètres limit et offset, pour lire les enregistrements dans la plage spécifiée. Cet article présentera les raisons et les méthodes d'optimisation d'un décalage excessif affectant les performances lors des requêtes MySQL.
Préparer le tableau des données de test et les données
1 Créer un tableau
CREATE TABLE `member` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `name` varchar(10) NOT NULL COMMENT '姓名', `gender` tinyint(3) unsigned NOT NULL COMMENT '性别', PRIMARY KEY (`id`), KEY `gender` (`gender`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
2. .Insérer 1 000 000 d'enregistrements
<?php
$pdo = new PDO("mysql:host=localhost;dbname=user","root",'');for($i=0; $i<1000000; $i++){ $name = substr(md5(time().mt_rand(000,999)),0,10); $gender = mt_rand(1,2); $sqlstr = "insert into member(name,gender) values('".$name."','".$gender."')"; $stmt = $pdo->prepare($sqlstr); $stmt->execute();}
?>mysql> select count(*) from member;
+----------+| count(*) |
+----------+| 1000000 |
+----------+1 row in set (0.23 sec)
3. Version actuelle de la base de données
mysql> select version(); +-----------+| version() | +-----------+| 5.6.24 | +-----------+1 row in set (0.01 sec)
Analyser les raisons pour lesquelles un décalage excessif affecte les performances
1 Le cas d'un petit décalage
mysql> select * from member where gender=1 limit 10,1; +----+------------+--------+| id | name | gender | +----+------------+--------+| 26 | 509e279687 | 1 | +----+------------+--------+1 row in set (0.00 sec)mysql> select * from member where gender=1 limit 100,1; +-----+------------+--------+| id | name | gender | +-----+------------+--------+| 211 | 07c4cbca3a | 1 | +-----+------------+--------+1 row in set (0.00 sec)mysql> select * from member where gender=1 limit 1000,1; +------+------------+--------+| id | name | gender | +------+------------+--------+| 1975 | e95b8b6ca1 | 1 | +------+------------+--------+1 row in set (0.00 sec)
Quand. le décalage est faible, la vitesse de requête est rapide et l'efficacité est élevée.
2. Lorsque le décalage est important
mysql> select * from member where gender=1 limit 100000,1; +--------+------------+--------+| id | name | gender | +--------+------------+--------+| 199798 | 540db8c5bc | 1 | +--------+------------+--------+1 row in set (0.12 sec)mysql> select * from member where gender=1 limit 200000,1; +--------+------------+--------+| id | name | gender | +--------+------------+--------+| 399649 | 0b21fec4c6 | 1 | +--------+------------+--------+1 row in set (0.23 sec)mysql> select * from member where gender=1 limit 300000,1; +--------+------------+--------+| id | name | gender | +--------+------------+--------+| 599465 | f48375bdb8 | 1 | +--------+------------+--------+1 row in set (0.31 sec)
Lorsque le décalage est important, des problèmes d'efficacité se produiront à mesure que le décalage augmente. , l’efficacité d’exécution diminue.
Analyser les raisons qui affectent les performances
select * from member where gender=1 limit 300000,1;
Parce que la table de données est InnoDB, basée sur la structure de l'index InnoDB, le processus de requête est le suivant :
Trouver la valeur de la clé primaire via l'index secondaire (trouver tous les identifiants avec le sexe = 1).
Recherchez ensuite le bloc de données correspondant via l'index de clé primaire en fonction de la valeur de clé primaire trouvée (recherchez le contenu du bloc de données correspondant en fonction de l'identifiant).
Selon la valeur de décalage, interrogez les données de l'index de clé primaire 300 001 fois, et enfin supprimez les 300 000 entrées précédentes et supprimez la dernière.
Mais puisque l'index secondaire a trouvé la valeur de clé primaire, pourquoi devons-nous utiliser l'index de clé primaire pour trouver d'abord le bloc de données, puis effectuer un traitement de décalage basé sur sur la valeur de décalage ?
Si après avoir trouvé l'index de clé primaire, effectuez d'abord un traitement de décalage, sautez 300 000 enregistrements, puis lisez le bloc de données via l'index de clé primaire du 300 001ème enregistrement, cela peut améliorer l'efficacité.
Si nous interrogeons uniquement la clé primaire, voyez quelle est la différence
mysql> select id from member where gender=1 limit 300000,1; +--------+| id | +--------+| 599465 | +--------+1 row in set (0.09 sec)
Évidemment, si nous interrogeons uniquement la clé primaire, l'efficacité d'exécution est grandement améliorée par rapport à l'interrogation tous les champs.
Spéculation
Interroger uniquement la clé primaire
Parce que l'index secondaire a déjà trouvé la valeur de clé primaire, et la requête n'a besoin que de lire la clé primaire, donc mysql effectuera d'abord l'opération de décalage, puis lira le bloc de données en fonction de l'index de clé primaire suivant.
Lorsque tous les champs doivent être interrogés
Parce que l'index secondaire ne trouve que la valeur de la clé primaire, mais les valeurs des autres champs doivent être lues dans le bloc de données pour obtenir. Par conséquent, MySQL lira d'abord le contenu du bloc de données, puis effectuera l'opération de décalage, et enfin supprimera les données précédentes qui doivent être ignorées et renverra les données suivantes.
Confirmé
Il existe un pool de tampons dans InnoDB, qui stocke les pages de données récemment visitées, y compris pages de données et pages d'index.
Pour les tests, redémarrez d'abord MySQL, puis vérifiez le contenu du pool de tampons.
mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('primary','gender') and TABLE_NAME like '%member%' group by index_name; Empty set (0.04 sec)
Vous pouvez voir qu'après le redémarrage, aucune page de données n'a été consultée.
Interrogez tous les champs, puis vérifiez le contenu du pool de tampons
mysql> select * from member where gender=1 limit 300000,1; +--------+------------+--------+| id | name | gender | +--------+------------+--------+| 599465 | f48375bdb8 | 1 | +--------+------------+--------+1 row in set (0.38 sec)mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('primary','gender') and TABLE_NAME like '%member%' group by index_name; +------------+----------+| index_name | count(*) | +------------+----------+| gender | 261 || PRIMARY | 1385 | +------------+----------+2 rows in set (0.06 sec)
On peut voir qu'à ce moment, il concernent la table membre dans le pool de mémoire tampon 1385 pages de données, 261 pages d'index.
Redémarrez MySQL pour vider le pool de tampons et continuez les tests pour interroger uniquement la clé primaire
mysql> select id from member where gender=1 limit 300000,1; +--------+| id | +--------+| 599465 | +--------+1 row in set (0.08 sec)mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('primary','gender') and TABLE_NAME like '%member%' group by index_name; +------------+----------+| index_name | count(*) | +------------+----------+| gender | 263 || PRIMARY | 13 | +------------+----------+2 rows in set (0.04 sec)
On peut voir qu'à ce stade temps, la table membre dans le pool de mémoire tampon. Il n'y a que 13 pages de données et 263 pages d'index. Par conséquent, de multiples opérations d'E/S pour accéder à des blocs de données via l'index de clé primaire sont réduites et l'efficacité d'exécution est améliorée.
Par conséquent, il peut être confirmé que La raison pour laquelle un décalage excessif affecte les performances lors de la requête MySQL est due à plusieurs opérations d'E/S pour accéder au bloc de données via l'index de clé primaire. (Notez que seul InnoDB a ce problème et que la structure d'index MYISAM est différente d'InnoDB. Les index secondaires pointent directement vers des blocs de données, il n'y a donc pas de problème de ce type).
Tableau comparatif des structures d'index entre les moteurs InnoDB et MyISAM
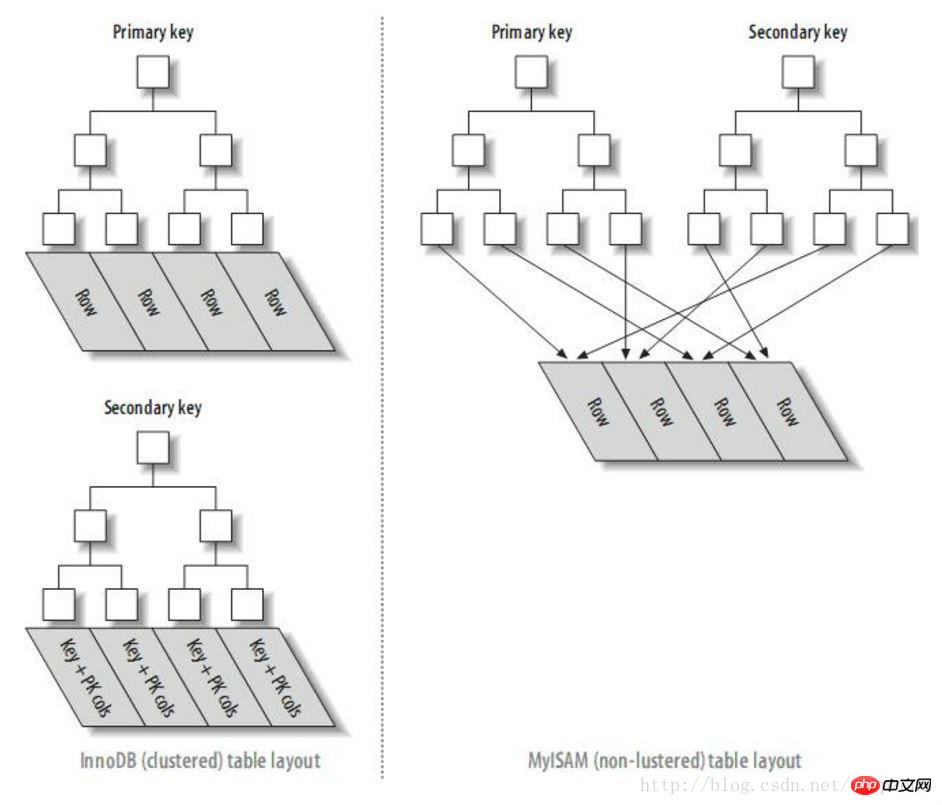
Méthode d'optimisation
Sur la base de l'analyse ci-dessus, nous savons que l'interrogation de tous les champs entraînera des opérations d'E/S provoquées par l'index de clé primaire accédant plusieurs fois au bloc de données.
Par conséquent, nous trouvons d'abord la clé primaire de décalage, puis interrogeons tout le contenu du bloc de données en fonction de l'index de clé primaire à optimiser.
mysql> select a.* from member as a inner join (select id from member where gender=1 limit 300000,1) as b on a.id=b.id; +--------+------------+--------+| id | name | gender | +--------+------------+--------+| 599465 | f48375bdb8 | 1 | +--------+------------+--------+1 row in set (0.08 sec)
Cet article explique les raisons et les méthodes d'optimisation d'un décalage excessif affectant les performances lors des requêtes MySQL. Veuillez faire attention au site Web chinois PHP pour plus de contenu connexe.
Recommandations associées :
Explication détaillée de la déduplication et du tri du contenu des fichiers
Interprétation des problèmes de configuration mysql sensibles à la casse
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!