
Maison >développement back-end >Tutoriel Python >Tutoriel de reconnaissance du code de vérification Python : traitement des niveaux de gris, binarisation, réduction du bruit et reconnaissance du tessérocr
Tutoriel de reconnaissance du code de vérification Python : traitement des niveaux de gris, binarisation, réduction du bruit et reconnaissance du tessérocr

- 不言original
- 2018-06-04 11:30:016479parcourir
Cet article présente principalement le tutoriel sur le traitement des niveaux de gris, la binarisation, la réduction du bruit et la reconnaissance tesserocr sur la reconnaissance du code de vérification python. Il a une certaine valeur de référence. Maintenant, je le partage avec vous. Les amis dans le besoin peuvent s'y référer. 🎜>
Avant-proposUn problème inévitable lors de l'écriture des robots est le code de vérification. Il existe désormais environ 4 types de codes de vérification :
- Classe de glissement
- Classe de clic
- Voix type
- Aujourd'hui, jetons un coup d'œil au type d'image. La plupart de ces codes de vérification sont une combinaison de chiffres et de lettres, et les caractères chinois sont également utilisés en Chine. Sur cette base, du bruit, des lignes d'interférence, des déformations, des chevauchements, des couleurs de police différentes et d'autres méthodes sont ajoutés pour augmenter la difficulté de reconnaissance.
En conséquence, la reconnaissance du code de vérification peut être grossièrement divisée en les étapes suivantes :
- Augmenter le contraste (facultatif)
- Binarisation
- Réduction du bruit
- Caractères de segmentation de correction d'inclinaison
- Établir une bibliothèque de formation
- Reconnaissance
- En raison de leur nature expérimentale, les codes de vérification utilisés dans cet article sont tous générés par des programmes plutôt que de télécharger de vrais codes de vérification de sites Web par lots. L'avantage est qu'il peut y avoir un grand nombre d'ensembles de données avec des résultats clairs.
Lorsque vous avez besoin d'obtenir des données dans un environnement réel, vous pouvez utiliser diverses plates-formes à code volumineux pour créer un ensemble de données pour la formation.
Pour générer le code de vérification, j'utilise la bibliothèque Claptcha (téléchargement local). Bien sûr, la bibliothèque Captcha (téléchargement local) est également un bon choix.
Afin de générer le code de vérification purement numérique et sans interférence le plus simple, vous devez d'abord apporter quelques modifications à _drawLine sur la ligne 285 de claptcha.py. Je laisse directement cette fonction renvoyer None, puis. commencez à générer le code de vérification. Code :
from claptcha import Claptcha
c = Claptcha("8069","/usr/share/fonts/truetype/freefont/FreeMono.ttf")
t,_ = c.write('1.png')Vous devez faire attention au chemin de la police d'Ubuntu ici, vous pouvez également télécharger d'autres polices en ligne pour utiliser. Le code de vérification est généré comme suit :
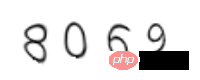 On constate que le code de vérification est déformé. Pour ce type de code de vérification le plus simple, vous pouvez directement utiliser le tesserocr open source de Google pour l'identifier.
On constate que le code de vérification est déformé. Pour ce type de code de vérification le plus simple, vous pouvez directement utiliser le tesserocr open source de Google pour l'identifier.
apt-get install tesseract-ocr libtesseract-dev libleptonica-dev pip install tesserocrPuis lancez la reconnaissance :
from PIL import Image import tesserocr p1 = Image.open('1.png') tesserocr.image_to_text(p1) '8069\n\n'On voit que pour ce simple code de vérification, fondamentalement rien n'est reconnu. est déjà très élevé. Les amis intéressés peuvent utiliser plus de données pour tester, mais je n'entrerai pas dans les détails ici.
Ensuite, ajoutez du bruit à l'arrière-plan du code de vérification pour voir :
c = Claptcha("8069","/usr/share/fonts/truetype/freefont/FreeMono.ttf",noise=0.4)
t,_ = c.write('2.png')Générez le code de vérification comme suit :
 Reconnaissance :
Reconnaissance :
p2 = Image.open('2.png') tesserocr.image_to_text(p2) '8069\n\n'L'effet est correct. Ensuite, générez une combinaison alphanumérique :
c2 = Claptcha("A4oO0zZ2","/usr/share/fonts/truetype/freefont/FreeMono.ttf")
t,_ = c2.write('3.png')Générez le code de vérification comme suit :
Le troisième est la lettre minuscule o, le quatrième est la lettre majuscule O, le cinquième est le chiffre 0, le sixième est la lettre minuscule z, le septième est la lettre majuscule Z et le dernier l'un est le numéro 2. Est-il vrai que les yeux humains se sont déjà agenouillés ! Mais maintenant, le code de vérification général ne fait pas strictement la distinction entre les majuscules et les minuscules. Voyons à quoi ressemble la reconnaissance automatique : 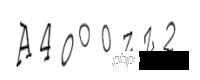
p3 = Image.open('3.png') tesserocr.image_to_text(p3) 'AMOOZW\n\n'Bien sûr, un ordinateur. cela fait s'agenouiller l'œil humain. C'est également inutile. Cependant, pour certains cas où l'interférence est faible et la déformation n'est pas grave, il est très simple et pratique d'utiliser le tesserocr. Restaurez ensuite la ligne 285 du claptcha.py _drawLine modifié pour voir si des lignes d'interférence sont ajoutées.

p4 = Image.open('4.png') tesserocr.image_to_text(p4) ''Il ne peut pas être reconnu du tout après l'ajout d'une ligne d'interférence. Existe-t-il donc un moyen de supprimer le. ligne d'interférence? Tissu de laine?
Bien que l'image semble en noir et blanc, elle doit encore être traitée en niveaux de gris. Sinon, en utilisant la fonction load(), vous obtiendrez un tuple RVB d'un certain pixel au lieu d'une valeur unique. Le traitement est le suivant :
def binarizing(img,threshold):
"""传入image对象进行灰度、二值处理"""
img = img.convert("L") # 转灰度
pixdata = img.load()
w, h = img.size
# 遍历所有像素,大于阈值的为黑色
for y in range(h):
for x in range(w):
if pixdata[x, y] < threshold:
pixdata[x, y] = 0
else:
pixdata[x, y] = 255
return imgL'image traitée est la suivante :
Vous pouvez le voir Après le traitement, l'image est beaucoup plus nette. Ensuite, essayez de supprimer les lignes d'interférence en utilisant les algorithmes courants à 4 et 8 quartiers. L'algorithme dit de voisinage X peut faire référence à la méthode de saisie de la grille à neuf carrés sur les téléphones mobiles. Le bouton 5 est le pixel à juger. Le voisin 4 doit juger vers le haut, le bas, la gauche et la droite, et le quartier 8 doit juger. les 8 pixels environnants. Si le nombre de 255 parmi ces 4 ou 8 points est supérieur à un certain seuil, ce point est considéré comme du bruit. Le seuil peut être modifié en fonction de la situation réelle. 
def depoint(img):
"""传入二值化后的图片进行降噪"""
pixdata = img.load()
w,h = img.size
for y in range(1,h-1):
for x in range(1,w-1):
count = 0
if pixdata[x,y-1] > 245:#上
count = count + 1
if pixdata[x,y+1] > 245:#下
count = count + 1
if pixdata[x-1,y] > 245:#左
count = count + 1
if pixdata[x+1,y] > 245:#右
count = count + 1
if pixdata[x-1,y-1] > 245:#左上
count = count + 1
if pixdata[x-1,y+1] > 245:#左下
count = count + 1
if pixdata[x+1,y-1] > 245:#右上
count = count + 1
if pixdata[x+1,y+1] > 245:#右下
count = count + 1
if count > 4:
pixdata[x,y] = 255
return imgL'image traitée est la suivante :

好像……根本没卵用啊?!确实是这样的,因为示例中的图片干扰线的宽度和数字是一样的。对于干扰线和数据像素不同的,比如Captcha生成的验证码:

从左到右依次是原图、二值化、去除干扰线的情况,总体降噪的效果还是比较明显的。另外降噪可以多次执行,比如我对上面的降噪后结果再进行依次降噪,可以得到下面的效果:

再进行识别得到了结果:
p7 = Image.open('7.png') tesserocr.image_to_text(p7) '8069 ,,\n\n'
另外,从图片来看,实际数据颜色明显和噪点干扰线不同,根据这一点可以直接把噪点全部去除,这里就不展开说了。
第一篇文章,先记录如何将图片进行灰度处理、二值化、降噪,并结合tesserocr来识别简单的验证码,剩下的部分在下一篇文章中和大家一起分享。
相关推荐:
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!