
Maison >développement back-end >Tutoriel Python >Quelques conseils pour implémenter la conversion de type de données dans Pandas
Quelques conseils pour implémenter la conversion de type de données dans Pandas

- 不言original
- 2018-05-07 11:44:007767parcourir
Cet article présente principalement quelques techniques de conversion de types de données dans Pandas, qui ont une certaine valeur de référence. Maintenant, je le partage avec vous. Les amis dans le besoin peuvent s'y référer
Avant-propos <.>
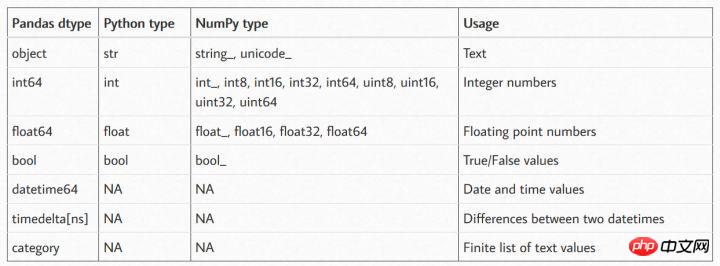
Pandas est un outil d'analyse de données important en Python. Lorsque vous utilisez Pandas pour l'analyse de données, il est très important de s'assurer que le type de données correct est utilisé, sinon des erreurs imprévisibles peuvent se produire. Types de données dans Pandas : les types de données sont essentiellement les structures internes que les langages de programmation utilisent pour comprendre comment stocker et manipuler les données. Par exemple, un programme doit comprendre que l’on peut additionner deux nombres, comme 5 + 10, pour obtenir 15. Ou, s'il s'agit de deux chaînes, telles que "cat" et "hat", vous pouvez les concaténer (ajouter) pour obtenir "cathat". Le professeur Chen, programmeur à Shangxuetang·Baizhan, a souligné qu'une chose potentiellement déroutante à propos des types de données Pandas est qu'il existe un certain chevauchement entre les types de données Pandas, Python et numpy.Les types de données font partie de ces choses dont vous ne vous souciez pas jusqu'à ce que vous rencontriez une erreur ou un résultat inattendu. Mais c'est aussi la première chose que vous devez vérifier lors du chargement de nouvelles données dans Pandas pour une analyse plus approfondie.
Types de données pris en charge respectivement par Pandas, Numpy et Python
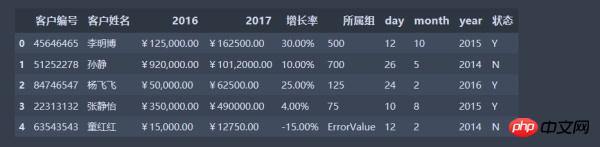
Présentation des données réelles pour l'analyse
Le type de données est quelque chose dont vous ne vous souciez peut-être pas beaucoup jusqu'à ce que vous obteniez un mauvais résultat, donc dans Un exemple de l'analyse des données réelles est introduite ici pour approfondir la compréhension.import numpy as np import pandas as pd data = pd.read_csv('data.csv', encoding='gbk') #因为数据中含有中文数据 data
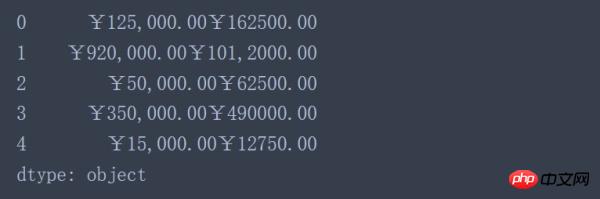
données['2016'] + données['2017'] #Pris pour acquis
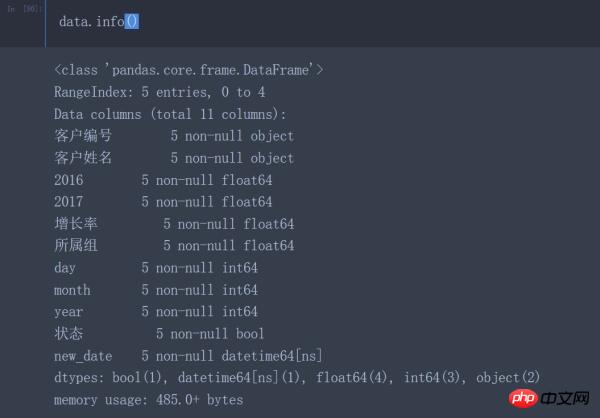
data.info() #Avant de traiter les données, vous devez vérifier les informations pertinentes des données chargées
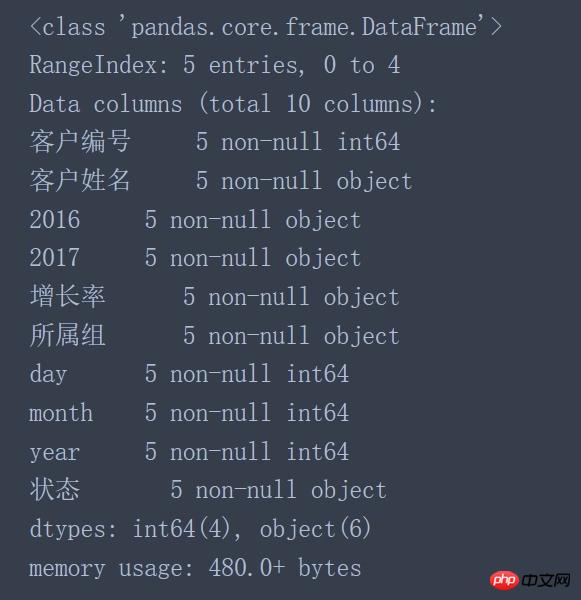
- Le type de données du numéro de client est int64 au lieu du type d'objet
- Le type de données des colonnes 2016 et 2017 est un objet au lieu d'un type numérique (int64, float64)
- Le type de données du taux de croissance et du groupe doit être type numérique au lieu du type d'objet
- Les types de données année, mois et jour doivent être de type datetime64 au lieu du type d'objet
- Utilisez la fonction astype() pour la conversion de type forcée
- Fonction personnalisée pour la conversion de type de données
- Utilisez les fonctions fournies par Pandas telles que to_numeric(), to_datetime()
Utilisez la fonction astype() pour la conversion de type
data['客户编号'].astype('object') data['客户编号'] = data['客户编号'].astype('object') #对原始数据进行转换并覆盖原始数据列
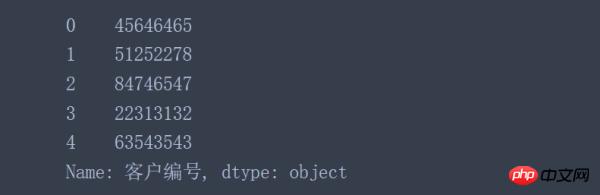
data['2017'].astype('float').
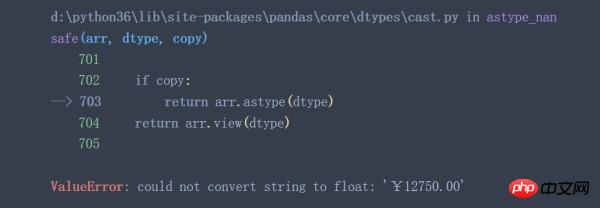
data['所属组'].astype('int')
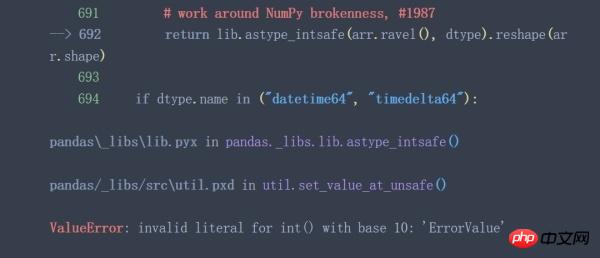
从上面两个例子可以看出,当待转换列中含有不能转换的特殊值时(例子中¥,ErrorValue等)astype()函数将失效。有些时候astype()函数执行成功了也并不一定代表着执行结果符合预期(神坑!)
data['状态'].astype('bool')
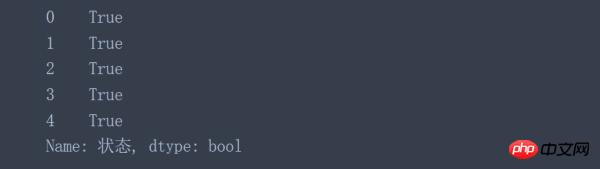
乍一看,结果看起来不错,但仔细观察后,会发现一个大问题。那就是所有的值都被替换为True了,但是该列中包含好几个N标志,所以astype()函数在该列也是失效的。
总结一下astype()函数有效的情形:
数据列中的每一个单位都能简单的解释为数字(2, 2.12等)
数据列中的每一个单位都是数值类型且向字符串object类型转换
如果数据中含有缺失值、特殊字符astype()函数可能失效。
使用自定义函数进行数据类型转换
该方法特别适用于待转换数据列的数据较为复杂的情形,可以通过构建一个函数应用于数据列的每一个数据,并将其转换为适合的数据类型。
对于上述数据中的货币,需要将它转换为float类型,因此可以写一个转换函数:
def convert_currency(value): """ 转换字符串数字为float类型 - 移除 ¥ , - 转化为float类型 """ new_value = value.replace(',', '').replace('¥', '') return np.float(new_value)
现在可以使用Pandas的apply函数通过covert_currency函数应用于2016列中的所有数据中。
data['2016'].apply(convert_currency)
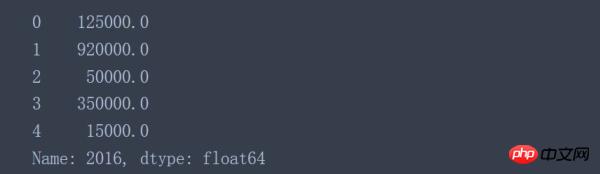
该列所有的数据都转换成对应的数值类型了,因此可以对该列数据进行常见的数学操作了。如果利用lambda表达式改写一下代码,可能会比较简洁但是对新手不太友好。
data['2016'].apply(lambda x: x.replace('¥', '').replace(',', '')).astype('float')
当函数需要重复应用于多个列时,个人推荐使用第一种方法,先定义函数还有一个好处就是可以搭配read_csv()函数使用(后面介绍)。
#2016、2017列完整的转换代码 data['2016'] = data['2016'].apply(convert_currency) data['2017'] = data['2017'].apply(convert_currency)
同样的方法运用于增长率,首先构建自定义函数
def convert_percent(value): """ 转换字符串百分数为float类型小数 - 移除 % - 除以100转换为小数 """ new_value = value.replace('%', '') return float(new_value) / 100
使用Pandas的apply函数通过covert_percent函数应用于增长率列中的所有数据中。
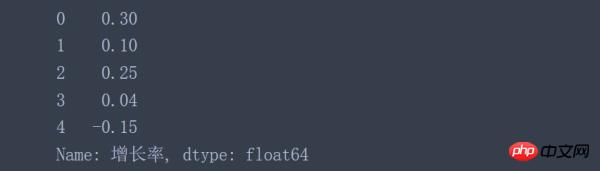
data['增长率'].apply(convert_percent)
使用lambda表达式:
data['增长率'].apply(lambda x: x.replace('%', '')).astype('float') / 100
结果都相同:
为了转换状态列,可以使用Numpy中的where函数,把值为Y的映射成True,其他值全部映射成False。
data['状态'] = np.where(data['状态'] == 'Y', True, False)
同样的你也可以使用自定义函数或者使用lambda表达式,这些方法都可以完美的解决这个问题,这里只是多提供一种思路。
利用Pandas的一些辅助函数进行类型转换
Pandas的astype()函数和复杂的自定函数之间有一个中间段,那就是Pandas的一些辅助函数。这些辅助函数对于某些特定数据类型的转换非常有用(如to_numeric()、to_datetime())。所属组数据列中包含一个非数值,用astype()转换出现了错误,然而用to_numeric()函数处理就优雅很多。
pd.to_numeric(data['所属组'], errors='coerce').fillna(0)

可以看到,非数值被替换成0.0了,当然这个填充值是可以选择的,具体文档见
pandas.to_numeric - pandas 0.22.0 documentation
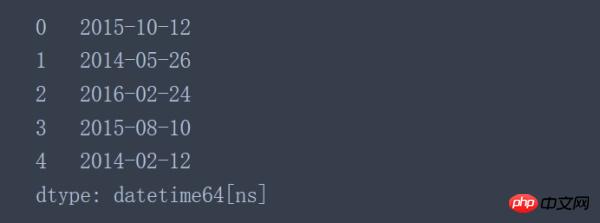
Pandas中的to_datetime()函数可以把单独的year、month、day三列合并成一个单独的时间戳。
pd.to_datetime(data[['day', 'month', 'year']])
完成数据列的替换
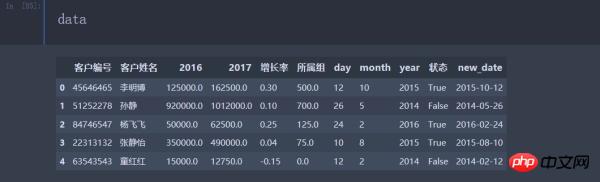
data['new_date'] = pd.to_datetime(data[['day', 'month', 'year']]) #新产生的一列数据 data['所属组'] = pd.to_numeric(data['所属组'], errors='coerce').fillna(0)
到这里所有的数据列都转换完毕,最终的数据显示:
在读取数据时就对数据类型进行转换,一步到位
data2 = pd.read_csv("data.csv",
converters={
'客户编号': str,
'2016': convert_currency,
'2017': convert_currency,
'增长率': convert_percent,
'所属组': lambda x: pd.to_numeric(x, errors='coerce'),
'状态': lambda x: np.where(x == "Y", True, False)
},
encoding='gbk')
在这里也体现了使用自定义函数比lambda表达式要方便很多。(大部分情况下lambda还是很简洁的,笔者自己也很喜欢使用)
Résumé
La première étape de l'exploitation d'un ensemble de données consiste à s'assurer que le type de données correct est défini, puis les données peuvent être analysé et visualisé Pour d'autres opérations, Pandas propose de nombreuses fonctions très pratiques. Avec ces fonctions, il sera très pratique d'analyser les données.
Recommandations associées :
Pandas implémente la sélection de lignes d'index spécifiques
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!