
Maison >interface Web >js tutoriel >Node implémente un serveur de ressources statiques
Node implémente un serveur de ressources statiques
- php中世界最好的语言original
- 2018-05-04 09:00:572045parcourir
Cette fois, je vais vous présenter Node pour implémenter un serveur de ressources statiques. Quelles sont les précautions pour que Node implémente un serveur de ressources statiques, jetons un coup d'œil.
Le principe de http est de regrouper la requête et la réponse. Lorsque le client se connecte, l'événement de connexion est déclenché en premier, puis la requête peut être envoyée plusieurs fois. Chaque requête déclenchera l'événement de requête
.let server = http.createServer();
let url = require('url');
server.on('connection', function (socket) {
console.log('客户端连接 ');
});
server.on('request', function (req, res) {
let { pathname, query } = url.parse(req.url, true);
let result = [];
req.on('data', function (data) {
result.push(data);
});
req.on('end', function () {
let r = Buffer.concat(result);
res.end(r);
})
});
server.on('close', function (req, res) {
console.log('服务器关闭 ');
});
server.on('error', function (err) {
console.log('服务器错误 ');
});
server.listen(8080, function () {
console.log('server started at http://localhost:8080');
});
req représente la connexion du client. Le serveur analyse les informations de demande et les met sur req. représente la réponse. , si vous souhaitez répondre au client, vous devez passer res
Les deux req et res proviennent du socket. Écoutez d'abord l'événement de données du socket, puis analysez-le lorsque l'événement se produit. , analysez l'objet d'en-tête de requête, créez l'objet de requête, puis créez l'objet de réponse basé sur l'objet de requête
req.url Obtenez le chemin de la requête
req .headers objet d'en-tête de requête
Ensuite, nous expliquerons quelques fonctions de base
Pourquoi compresser ? Quels sont les avantages ?
Vous pouvez utiliser le module zlib pour le traitement de compression et de décompression. Après avoir compressé le fichier, vous pouvez réduire la taille, accélérer la vitesse de transmission et économiser la bande passante. Les objets de compression et de décompression sont des flux de conversion de transformation, hérités du flux duplex duplex, qui est un flux lisible et inscriptible
zlib.createGzip : renvoie l'objet flux Gzip et utilise le Algorithme Gzip pour compresser les données- zlib.createGunzip : Renvoie l'objet flux Gzip, utilise l'algorithme Gzip pour décompresser les données compressées
- zlib .createDeflate : renvoie l'objet de flux Deflate, utilise Deflate L'algorithme compresse les données
- zlib.createInflate : renvoie l'objet de flux Deflate et utilise l'algorithme Deflate pour décompresser les données
Implémenter la compression et la décompression
La méthode gzip est utilisée pour implémenter la compression
let fs = require("fs");
let path = require("path");
let zlib = require("zlib");
function gzip(src) {
fs
.createReadStream(src)
.pipe(zlib.createGzip())
.pipe(fs.createWriteStream(src + ".gz"));
}
gzip(path.join(dirname,'msg.txt'));
function gunzip(src) {
fs
.createReadStream(src)
.pipe(zlib.createGunzip())
.pipe(
fs.createWriteStream(path.join(dirname, path.basename(src, ".gz")))
);
}
gunzip(path.join(dirname, "msg.txt.gz"));
- La méthode gunzip est utilisée pour implémenter la décompression
- où le fichier msg.txt est un répertoire frère
- Pourquoi devez-vous écrire ceci : gzip(path.join(dirname,'msg.txt'));
- Parce que console.log(process.cwd ()); Affiche que le répertoire de travail actuel est le répertoire racine, pas le répertoire où se trouve le fichier. Si vous écrivez gzip('. msg.txt'); si le fichier est introuvable, une erreur sera signalée
- basename obtient le nom du fichier à partir d'un chemin, y compris l'extension, vous pouvez passer un paramètre d'extension et le supprimer l'extension
- extname obtient l'extension
- Le format compressé et le format décompressé doivent correspondre, sinon une erreur sera signalée
- Parfois, la chaîne que nous obtenons n'est pas un flux, alors comment le résoudre Il est possible que le contenu compressé soit plus grand que l'original si le contenu l'est. trop petit, la compression n'aura aucun sens
L'effet de la compression du texte sera meilleur, car il y a des règles
let zlib=require('zlib');
let str='hello';
zlib.gzip(str,(err,buffer)=>{
console.log(buffer.length);
zlib.unzip(buffer,(err,data)=>{
console.log(data.toString());
})
});dans http Appliquer la compression et la décompression dans Ce qui suit implémente un tel fonction, comme le montre la figure :
Lorsque le client initie une requête au serveur, il transmettra accept-encoding (Par exemple : Accept-Encoding : gzip, par défaut ) indique au serveur le format de décompression que je prends en charge

- Si le format en Accept-Encoding requis par le client n'est pas disponible sur le serveur, la compression ne peut pas être obtenue
- mime : obtenez le type de contenu d'un fichier via le nom et le chemin du fichier. Différents types de contenu peuvent être renvoyés en fonction des différents types de contenu du fichier
let http = require("http");
let path = require("path");
let url = require("url");
let zlib = require("zlib");
let fs = require("fs");
let { promisify } = require("util");
let mime = require("mime");
//把一个异步方法转成一个返回promise的方法
let stat = promisify(fs.stat);
http.createServer(request).listen(8080);
async function request(req, res) {
let { pathname } = url.parse(req.url);
let filepath = path.join(dirname, pathname);
// fs.stat(filepath,(err,stat)=>{});现在不这么写了,异步的处理起来比较麻烦
try {
let statObj = await stat(filepath);
res.setHeader("Content-Type", mime.getType(pathname));
let acceptEncoding = req.headers["accept-encoding"];
if (acceptEncoding) {
if (acceptEncoding.match(/\bgzip\b/)) {
res.setHeader("Content-Encoding", "gzip");
fs
.createReadStream(filepath)
.pipe(zlib.createGzip())
.pipe(res);
} else if (acceptEncoding.match(/\bdeflate\b/)) {
res.setHeader("Content-Encoding", "deflate");
fs
.createReadStream(filepath)
.pipe(zlib.createDeflate())
.pipe(res);
} else {
fs.createReadStream(filepath).pipe(res);
}
} else {
fs.createReadStream(filepath).pipe(res);
}
} catch (e) {
res.statusCode = 404;
res.end("Not Found");
}
}
- acceptEncoding. : Écrit en minuscules pour être compatible avec les différents navigateurs, le nœud convertit tous les en-têtes de requêtes en minuscules
filepath:得到文件的绝对路径
启动服务后,访问http://localhost:8080/msg.txt 可看到结果
深刻理解并实现缓存
为什么要缓存呢,缓存有什么好处?
减少了冗余的数据传输,节省了网费。
减少了服务器的负担, 大大提高了网站的性能
加快了客户端加载网页的速度
缓存的分类
强制缓存:
强制缓存,在缓存数据未失效的情况下,可以直接使用缓存数据
在没有缓存数据的时候,浏览器向服务器请求数据时,服务器会将数据和缓存规则一并返回,缓存规则信息包含在响应header中
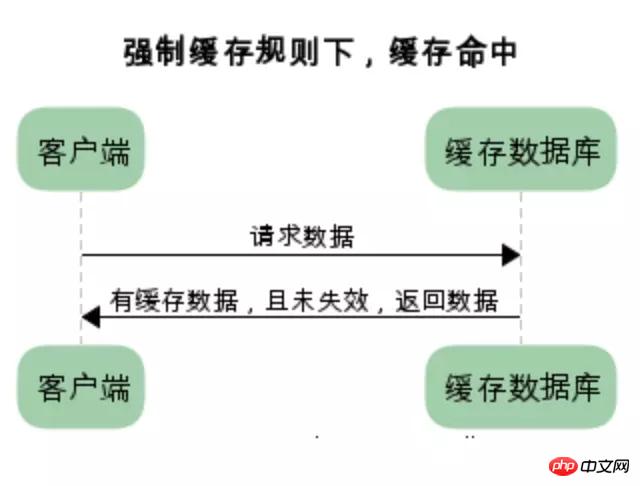
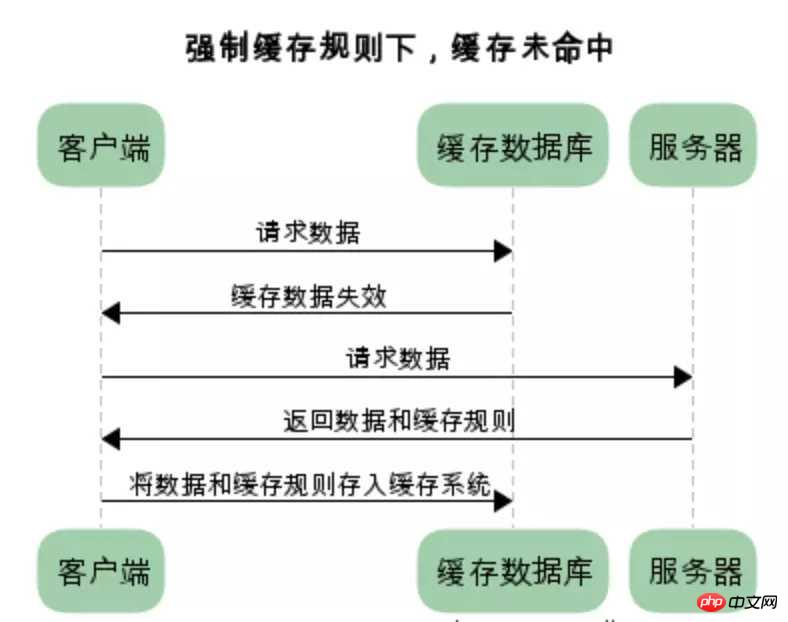
对比缓存:
浏览器第一次请求数据时,服务器会将缓存标识与数据一起返回给客户端,客户端将二者备份至缓存数据库中
再次请求数据时,客户端将备份的缓存标识发送给服务器,服务器根据缓存标识进行判断,判断成功后,返回304状态码,通知客户端比较成功,可以使用缓存数据
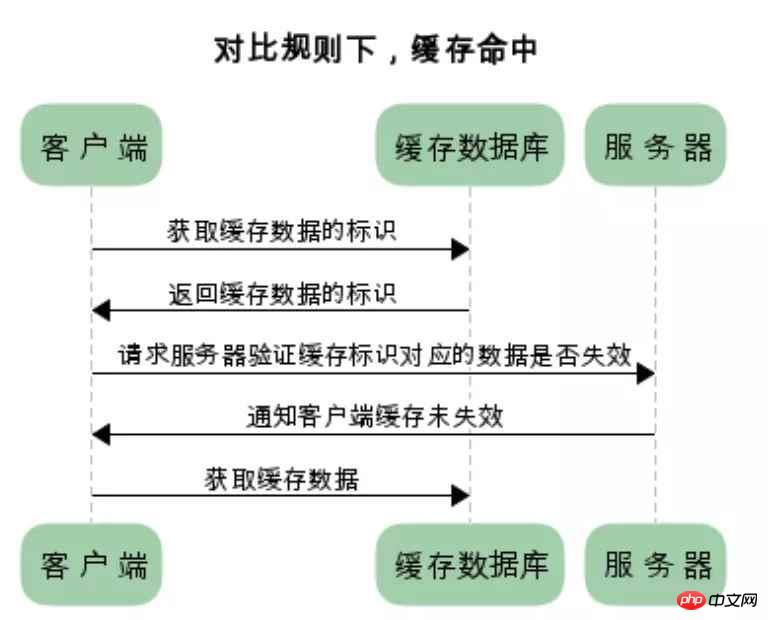
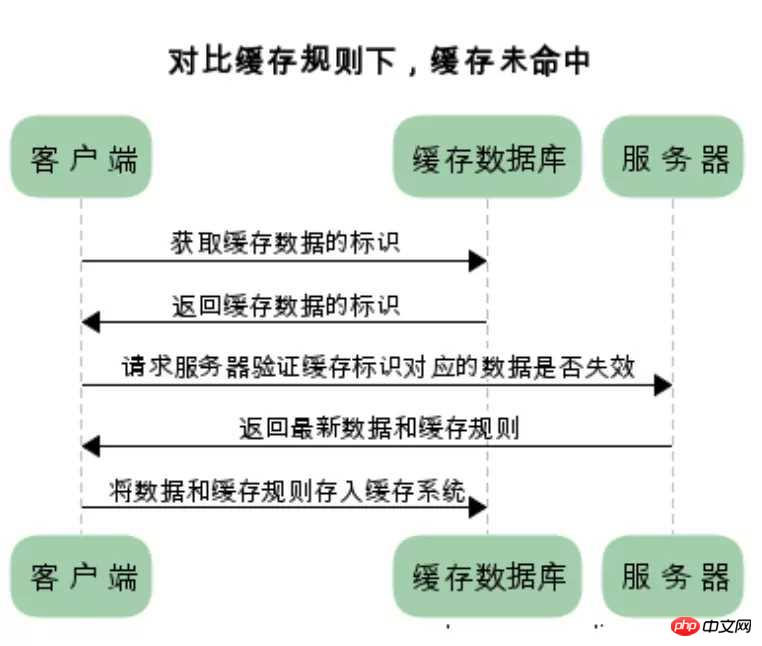
两类缓存的区别和联系
强制缓存如果生效,不需要再和服务器发生交互,而对比缓存不管是否生效,都需要与服务端发生交互
两类缓存规则可以同时存在,强制缓存优先级高于对比缓存,也就是说,当执行强制缓存的规则时,如果缓存生效,直接使用缓存,不再执行对比缓存规则
实现对比缓存
实现对比缓存一般是按照以下步骤:
第一次访问服务器的时候,服务器返回资源和缓存的标识,客户端则会把此资源缓存在本地的缓存数据库中。
第二次客户端需要此数据的时候,要取得缓存的标识,然后去问一下服务器我的资源是否是最新的。
如果是最新的则直接使用缓存数据,如果不是最新的则服务器返回新的资源和缓存规则,客户端根据缓存规则缓存新的数据
实现对比缓存一般有两种方式
通过最后修改时间来判断缓存是否可用
let http = require('http');
let url = require('url');
let path = require('path');
let fs = require('fs');
let mime = require('mime');
// http://localhost:8080/index.html
http.createServer(function (req, res) {
let { pathname } = url.parse(req.url, true);
//D:\vipcode\201801\20.cache\index.html
let filepath = path.join(dirname, pathname);
fs.stat(filepath, (err, stat) => {
if (err) {
return sendError(req, res);
} else {
let ifModifiedSince = req.headers['if-modified-since'];
let LastModified = stat.ctime.toGMTString();
if (ifModifiedSince == LastModified) {
res.writeHead(304);
res.end('');
} else {
return send(req, res, filepath, stat);
}
}
});
}).listen(8080);
function sendError(req, res) {
res.end('Not Found');
}
function send(req, res, filepath, stat) {
res.setHeader('Content-Type', mime.getType(filepath));
//发给客户端之后,客户端会把此时间保存起来,下次再获取此资源的时候会把这个时间再发回服务器
res.setHeader('Last-Modified', stat.ctime.toGMTString());
fs.createReadStream(filepath).pipe(res);
}
这种方式有很多缺陷
某些服务器不能精确得到文件的最后修改时间, 这样就无法通过最后修改时间来判断文件是否更新了
某些文件的修改非常频繁,在秒以下的时间内进行修改.Last-Modified只能精确到秒。
一些文件的最后修改时间改变了,但是内容并未改变。 我们不希望客户端认为这个文件修改了
如果同样的一个文件位于多个CDN服务器上的时候内容虽然一样,修改时间不一样
ETag
ETag是根据实体内容生成的一段hash字符串,可以标识资源的状态
资源发生改变时,ETag也随之发生变化。 ETag是Web服务端产生的,然后发给浏览器客户端
let http = require('http');
let url = require('url');
let path = require('path');
let fs = require('fs');
let mime = require('mime');
let crypto = require('crypto');
http.createServer(function (req, res) {
let { pathname } = url.parse(req.url, true);
let filepath = path.join(dirname, pathname);
fs.stat(filepath, (err, stat) => {
if (err) {
return sendError(req, res);
} else {
let ifNoneMatch = req.headers['if-none-match'];
let out = fs.createReadStream(filepath);
let md5 = crypto.createHash('md5');
out.on('data', function (data) {
md5.update(data);
});
out.on('end', function () {
let etag = md5.digest('hex');
let etag = `${stat.size}`;
if (ifNoneMatch == etag) {
res.writeHead(304);
res.end('');
} else {
return send(req, res, filepath, etag);
}
});
}
});
}).listen(8080);
function sendError(req, res) {
res.end('Not Found');
}
function send(req, res, filepath, etag) {
res.setHeader('Content-Type', mime.getType(filepath));
res.setHeader('ETag', etag);
fs.createReadStream(filepath).pipe(res);
}
客户端想判断缓存是否可用可以先获取缓存中文档的ETag,然后通过If-None-Match发送请求给Web服务器询问此缓存是否可用。
服务器收到请求,将服务器的中此文件的ETag,跟请求头中的If-None-Match相比较,如果值是一样的,说明缓存还是最新的,Web服务器将发送304 Not Modified响应码给客户端表示缓存未修改过,可以使用。
如果不一样则Web服务器将发送该文档的最新版本给浏览器客户端
实现强制缓存
把资源缓存在客户端,如果客户端再次需要此资源的时候,先获取到缓存中的数据,看是否过期,如果过期了。再请求服务器
如果没过期,则根本不需要向服务器确认,直接使用本地缓存即可
let http = require('http');
let url = require('url');
let path = require('path');
let fs = require('fs');
let mime = require('mime');
let crypto = require('crypto');
http.createServer(function (req, res) {
let { pathname } = url.parse(req.url, true);
let filepath = path.join(dirname, pathname);
console.log(filepath);
fs.stat(filepath, (err, stat) => {
if (err) {
return sendError(req, res);
} else {
send(req, res, filepath);
}
});
}).listen(8080);
function sendError(req, res) {
res.end('Not Found');
}
function send(req, res, filepath) {
res.setHeader('Content-Type', mime.getType(filepath));
res.setHeader('Expires', new Date(Date.now() + 30 * 1000).toUTCString());
res.setHeader('Cache-Control', 'max-age=30');
fs.createReadStream(filepath).pipe(res);
}
浏览器会将文件缓存到Cache目录,第二次请求时浏览器会先检查Cache目录下是否含有该文件,如果有,并且还没到Expires设置的时间,即文件还没有过期,那么此时浏览器将直接从Cache目录中读取文件,而不再发送请求
Expires是服务器响应消息头字段,在响应http请求时告诉浏览器在过期时间前浏览器可以直接从浏览器缓存取数据
Cache-Control与Expires的作用一致,都是指明当前资源的有效期,控制浏览器是否直接从浏览器缓存取数据还是重新发请求到服务器取数据,如果同时设置的话,其优先级高于Expires
下面开始写静态服务器
首先创建一个http服务,配置监听端口
let http = require('http');
let server = http.createServer();
server.on('request', this.request.bind(this));
server.listen(this.config.port, () => {
let url = `http://${this.config.host}:${this.config.port}`;
debug(`server started at ${chalk.green(url)}`);
});
下面写个静态文件服务器
先取到客户端想说的文件或文件夹路径,如果是目录的话,应该显示目录下面的文件列表
async request(req, res) {
let { pathname } = url.parse(req.url);
if (pathname == '/favicon.ico') {
return this.sendError('not found', req, res);
}
let filepath = path.join(this.config.root, pathname);
try {
let statObj = await stat(filepath);
if (statObj.isDirectory()) {
let files = await readdir(filepath);
files = files.map(file => ({
name: file,
url: path.join(pathname, file)
}));
let html = this.list({
title: pathname,
files
});
res.setHeader('Content-Type', 'text/html');
res.end(html);
} else {
this.sendFile(req, res, filepath, statObj);
}
} catch (e) {
debug(inspect(e));
this.sendError(e, req, res);
}
}
sendFile(req, res, filepath, statObj) {
if (this.handleCache(req, res, filepath, statObj)) return;
res.setHeader('Content-Type', mime.getType(filepath) + ';charset=utf-8');
let encoding = this.getEncoding(req, res);
let rs = this.getStream(req, res, filepath, statObj);
if (encoding) {
rs.pipe(encoding).pipe(res);
} else {
rs.pipe(res);
}
}
支持断点续传
getStream(req, res, filepath, statObj) {
let start = 0;
let end = statObj.size - 1;
let range = req.headers['range'];
if (range) {
res.setHeader('Accept-Range', 'bytes');
res.statusCode = 206;
let result = range.match(/bytes=(\d*)-(\d*)/);
if (result) {
start = isNaN(result[1]) ? start : parseInt(result[1]);
end = isNaN(result[2]) ? end : parseInt(result[2]) - 1;
}
}
return fs.createReadStream(filepath, {
start, end
});
}
支持对比缓存,通过etag的方式
handleCache(req, res, filepath, statObj) {
let ifModifiedSince = req.headers['if-modified-since'];
let isNoneMatch = req.headers['is-none-match'];
res.setHeader('Cache-Control', 'private,max-age=30');
res.setHeader('Expires', new Date(Date.now() + 30 * 1000).toGMTString());
let etag = statObj.size;
let lastModified = statObj.ctime.toGMTString();
res.setHeader('ETag', etag);
res.setHeader('Last-Modified', lastModified);
if (isNoneMatch && isNoneMatch != etag) {
return fasle;
}
if (ifModifiedSince && ifModifiedSince != lastModified) {
return fasle;
}
if (isNoneMatch || ifModifiedSince) {
res.writeHead(304);
res.end();
return true;
} else {
return false;
}
}
支持文件压缩
getEncoding(req, res) {
let acceptEncoding = req.headers['accept-encoding'];
if (/\bgzip\b/.test(acceptEncoding)) {
res.setHeader('Content-Encoding', 'gzip');
return zlib.createGzip();
} else if (/\bdeflate\b/.test(acceptEncoding)) {
res.setHeader('Content-Encoding', 'deflate');
return zlib.createDeflate();
} else {
return null;
}
}
编译模板,得到一个渲染的方法,然后传入实际数据数据就可以得到渲染后的HTML了
function list() {
let tmpl = fs.readFileSync(path.resolve(dirname, 'template', 'list.html'), 'utf8');
return handlebars.compile(tmpl);
}
这样一个简单的静态服务器就完成了,其中包含了静态文件服务,实现缓存,实现断点续传,分块获取,实现压缩的功能
相信看了本文案例你已经掌握了方法,更多精彩请关注php中文网其它相关文章!
推荐阅读:
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Une analyse approfondie du composant de groupe de liste Bootstrap
- Explication détaillée du currying de la fonction JavaScript
- Exemple complet de génération de mot de passe JS et de détection de force (avec téléchargement du code source de démonstration)
- Angularjs intègre l'interface utilisateur WeChat (weui)
- Comment basculer rapidement entre le chinois traditionnel et le chinois simplifié avec JavaScript et l'astuce permettant aux sites Web de prendre en charge le basculement entre les compétences en chinois simplifié et traditionnel_javascript