
Maison >développement back-end >tutoriel php >Explication détaillée des trois façons de charger des données dans Tensorflow
Explication détaillée des trois façons de charger des données dans Tensorflow

- 不言original
- 2018-04-24 14:24:093506parcourir
Cet article présente principalement les trois méthodes de chargement de données dans tensorflow. Maintenant, je le partage avec vous et vous donne une référence. Jetons un coup d'œil ensemble
Il existe trois façons de lire les données Tensorflow :
Données préchargées : données préchargées
Alimentation : Python génère des données, puis les transmet au backend.
Lecture à partir du fichier : Lecture directement à partir du fichier
Quelles sont les différences entre ces trois méthodes de lecture ? Nous devons d’abord savoir comment fonctionne TensorFlow (TF).
Le noyau de TF est écrit en C++. L'avantage est qu'il s'exécute rapidement, mais l'inconvénient est que l'appel est rigide. Python est tout le contraire, il combine donc les avantages des deux langages. Les principaux opérateurs et le cadre d'exploitation impliqués dans les calculs sont écrits en C++ et les API sont fournies pour Python. Python appelle ces API, conçoit le modèle de formation (Graph), puis envoie le Graph conçu au backend pour exécution. En bref, le rôle de Python est de concevoir et le rôle de C++ est d'exécuter.
1. Précharger les données :
import tensorflow as tf # 设计Graph x1 = tf.constant([2, 3, 4]) x2 = tf.constant([4, 0, 1]) y = tf.add(x1, x2) # 打开一个session --> 计算y with tf.Session() as sess: print sess.run(y)
2. python génère des données puis transmet les données au backend
import tensorflow as tf
# 设计Graph
x1 = tf.placeholder(tf.int16)
x2 = tf.placeholder(tf.int16)
y = tf.add(x1, x2)
# 用Python产生数据
li1 = [2, 3, 4]
li2 = [4, 0, 1]
# 打开一个session --> 喂数据 --> 计算y
with tf.Session() as sess:
print sess.run(y, feed_dict={x1: li1, x2: li2})
Remarque : x1 ici, x2 est juste un espace réservé et n'a pas de valeur spécifique. Alors, où obtient-il la valeur lors de son exécution ? À ce stade, vous devez utiliser le paramètre feed_dict dans sess.run() pour transmettre les données générées par Python au backend et calculer y.
Inconvénients de ces deux solutions :
1. Préchargement : intégrez les données directement dans le Graph, puis transmettez le Graph dans la Session pour l'exécuter. Lorsque la quantité de données est relativement importante, la transmission Graph rencontrera des problèmes d'efficacité.
2. Utilisez des espaces réservés pour remplacer les données et remplissez les données lors de leur exécution.
Les deux premières méthodes sont très pratiques, mais elles seront très difficiles face à des données volumineuses. Même pour l'alimentation, l'augmentation des liens intermédiaires n'est pas une petite surcharge, comme la conversion du type de données, etc. La meilleure solution consiste à définir la méthode de lecture du fichier dans Graph et à laisser TF lire les données du fichier et les décoder en un ensemble d'échantillons utilisable.
3. Lecture à partir du fichier, en termes simples, configurez le schéma du module de lecture des données
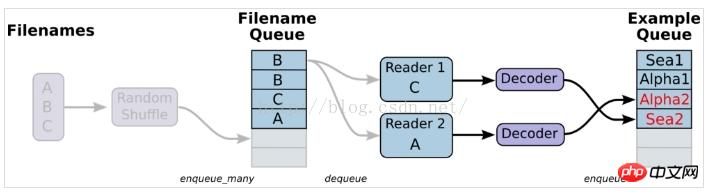
1. Préparez les données et construisez trois fichiers, A.csv, B.csv, C.csv
$ echo -e "Alpha1,A1\nAlpha2,A2\nAlpha3,A3" > A.csv $ echo -e "Bee1,B1\nBee2,B2\nBee3,B3" > B.csv $ echo -e "Sea1,C1\nSea2,C2\nSea3,C3" > C.csv
2. sample
#-*- coding:utf-8 -*-
import tensorflow as tf
# 生成一个先入先出队列和一个QueueRunner,生成文件名队列
filenames = ['A.csv', 'B.csv', 'C.csv']
filename_queue = tf.train.string_input_producer(filenames, shuffle=False)
# 定义Reader
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
# 定义Decoder
example, label = tf.decode_csv(value, record_defaults=[['null'], ['null']])
#example_batch, label_batch = tf.train.shuffle_batch([example,label], batch_size=1, capacity=200, min_after_dequeue=100, num_threads=2)
# 运行Graph
with tf.Session() as sess:
coord = tf.train.Coordinator() #创建一个协调器,管理线程
threads = tf.train.start_queue_runners(coord=coord) #启动QueueRunner, 此时文件名队列已经进队。
for i in range(10):
print example.eval(),label.eval()
coord.request_stop()
coord.join(threads)
Remarque : tf.train.shuffle_batch n'est pas utilisé ici, ce qui empêchera les échantillons et les étiquettes générés de correspondre les uns aux autres et d'être hors service. Les résultats générés sont les suivants :
Alpha1 A2
Alpha3 B1
Bee2 B3
Sea1 C2
Sea3 A1
Alpha2 A3
Bee1 B2
Bee3 C1
Sea2 C3
Alpha1 A2
Solution : utilisez tf.train.shuffle_batch, les résultats générés peuvent alors correspondre.
#-*- coding:utf-8 -*-
import tensorflow as tf
# 生成一个先入先出队列和一个QueueRunner,生成文件名队列
filenames = ['A.csv', 'B.csv', 'C.csv']
filename_queue = tf.train.string_input_producer(filenames, shuffle=False)
# 定义Reader
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
# 定义Decoder
example, label = tf.decode_csv(value, record_defaults=[['null'], ['null']])
example_batch, label_batch = tf.train.shuffle_batch([example,label], batch_size=1, capacity=200, min_after_dequeue=100, num_threads=2)
# 运行Graph
with tf.Session() as sess:
coord = tf.train.Coordinator() #创建一个协调器,管理线程
threads = tf.train.start_queue_runners(coord=coord) #启动QueueRunner, 此时文件名队列已经进队。
for i in range(10):
e_val,l_val = sess.run([example_batch, label_batch])
print e_val,l_val
coord.request_stop()
coord.join(threads)
3. Lecteur unique, plusieurs échantillons, principalement implémentés via tf.train.shuffle_batch
#-*- coding:utf-8 -*-
import tensorflow as tf
filenames = ['A.csv', 'B.csv', 'C.csv']
filename_queue = tf.train.string_input_producer(filenames, shuffle=False)
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
example, label = tf.decode_csv(value, record_defaults=[['null'], ['null']])
# 使用tf.train.batch()会多加了一个样本队列和一个QueueRunner。
#Decoder解后数据会进入这个队列,再批量出队。
# 虽然这里只有一个Reader,但可以设置多线程,相应增加线程数会提高读取速度,但并不是线程越多越好。
example_batch, label_batch = tf.train.batch(
[example, label], batch_size=5)
with tf.Session() as sess:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
for i in range(10):
e_val,l_val = sess.run([example_batch,label_batch])
print e_val,l_val
coord.request_stop()
coord.join(threads)
Explication : Dans la méthode d'écriture suivante, les échantillons, caractéristiques et étiquettes batch_size extraits sont également désynchronisés
#-*- coding:utf-8 -*-
import tensorflow as tf
filenames = ['A.csv', 'B.csv', 'C.csv']
filename_queue = tf.train.string_input_producer(filenames, shuffle=False)
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
example, label = tf.decode_csv(value, record_defaults=[['null'], ['null']])
# 使用tf.train.batch()会多加了一个样本队列和一个QueueRunner。
#Decoder解后数据会进入这个队列,再批量出队。
# 虽然这里只有一个Reader,但可以设置多线程,相应增加线程数会提高读取速度,但并不是线程越多越好。
example_batch, label_batch = tf.train.batch(
[example, label], batch_size=5)
with tf.Session() as sess:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
for i in range(10):
print example_batch.eval(), label_batch.eval()
coord.request_stop()
coord.join(threads)
Explication : Le résultat de sortie est le suivant : on peut voir qu'il n'y a pas de correspondance entre la caractéristique et l'étiquette
['Alpha1' 'Alpha2' 'Alpha3' 'Abeille1' 'Abeille2'] ['B3' 'C1' 'C2' 'C3' 'A1']
['Alpha2' 'Alpha3' 'Abeille1' 'Abeille2' 'Abeille3'] ['C1 ' 'C2' 'C3' 'A1' 'A2']
['Alpha3' 'Bee1' 'Bee2' 'Bee3' 'Mer1'] ['C2' 'C3' 'A1' 'A2' 'A3' ]
4. Lecteurs multiples, échantillons multiples
#-*- coding:utf-8 -*-
import tensorflow as tf
filenames = ['A.csv', 'B.csv', 'C.csv']
filename_queue = tf.train.string_input_producer(filenames, shuffle=False)
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
record_defaults = [['null'], ['null']]
#定义了多种解码器,每个解码器跟一个reader相连
example_list = [tf.decode_csv(value, record_defaults=record_defaults)
for _ in range(2)] # Reader设置为2
# 使用tf.train.batch_join(),可以使用多个reader,并行读取数据。每个Reader使用一个线程。
example_batch, label_batch = tf.train.batch_join(
example_list, batch_size=5)
with tf.Session() as sess:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
for i in range(10):
e_val,l_val = sess.run([example_batch,label_batch])
print e_val,l_val
coord.request_stop()
coord.join(threads)
tf.train.batch et The tf. La fonction train.shuffle_batch lit à partir d'un seul lecteur, mais peut être multithread. tf.train.batch_join et tf.train.shuffle_batch_join peuvent configurer plusieurs lecteurs à lire, et chaque lecteur utilise un thread. Quant à l’efficacité des deux méthodes, avec un seul Reader, deux threads ont atteint la limite de vitesse. Lorsqu'il y a plusieurs lecteurs, 2 lecteurs atteindront la limite. Ce n’est donc pas que plus de threads sont plus rapides, ou même plus de threads réduiront l’efficacité.
5. Contrôle itératif, définir les paramètres d'époque, spécifier combien de tours notre échantillon ne peut être utilisé que pendant l'entraînement
#-*- coding:utf-8 -*-
import tensorflow as tf
filenames = ['A.csv', 'B.csv', 'C.csv']
#num_epoch: 设置迭代数
filename_queue = tf.train.string_input_producer(filenames, shuffle=False,num_epochs=3)
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
record_defaults = [['null'], ['null']]
#定义了多种解码器,每个解码器跟一个reader相连
example_list = [tf.decode_csv(value, record_defaults=record_defaults)
for _ in range(2)] # Reader设置为2
# 使用tf.train.batch_join(),可以使用多个reader,并行读取数据。每个Reader使用一个线程。
example_batch, label_batch = tf.train.batch_join(
example_list, batch_size=1)
#初始化本地变量
init_local_op = tf.initialize_local_variables()
with tf.Session() as sess:
sess.run(init_local_op)
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
try:
while not coord.should_stop():
e_val,l_val = sess.run([example_batch,label_batch])
print e_val,l_val
except tf.errors.OutOfRangeError:
print('Epochs Complete!')
finally:
coord.request_stop()
coord.join(threads)
coord.request_stop()
coord.join(threads)
Dans le contrôle d'itération, pensez à ajouter tf.initialize_local_variables() Le tutoriel du site officiel ne l'explique pas, mais s'il n'est pas initialisé, une erreur sera signalée lors de l'exécution.
Pour l'apprentissage automatique traditionnel, tel que les problèmes de classification, [x1 x2 x3] est une fonctionnalité. Pour un problème de classification à deux classes, l'étiquette sera [0,1] ou [1,0] après un codage à chaud. Dans des circonstances normales, nous envisagerons d'organiser les données dans un fichier CSV, avec une ligne représentant un échantillon. Utilisez ensuite la file d'attente pour lire les données
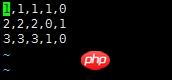
说明:对于该数据,前三列代表的是feature,因为是分类问题,后两列就是经过one-hot编码之后得到的label
使用队列读取该csv文件的代码如下:
#-*- coding:utf-8 -*-
import tensorflow as tf
# 生成一个先入先出队列和一个QueueRunner,生成文件名队列
filenames = ['A.csv']
filename_queue = tf.train.string_input_producer(filenames, shuffle=False)
# 定义Reader
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
# 定义Decoder
record_defaults = [[1], [1], [1], [1], [1]]
col1, col2, col3, col4, col5 = tf.decode_csv(value,record_defaults=record_defaults)
features = tf.pack([col1, col2, col3])
label = tf.pack([col4,col5])
example_batch, label_batch = tf.train.shuffle_batch([features,label], batch_size=2, capacity=200, min_after_dequeue=100, num_threads=2)
# 运行Graph
with tf.Session() as sess:
coord = tf.train.Coordinator() #创建一个协调器,管理线程
threads = tf.train.start_queue_runners(coord=coord) #启动QueueRunner, 此时文件名队列已经进队。
for i in range(10):
e_val,l_val = sess.run([example_batch, label_batch])
print e_val,l_val
coord.request_stop()
coord.join(threads)
输出结果如下:
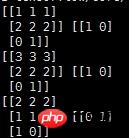
说明:
record_defaults = [[1], [1], [1], [1], [1]]
代表解析的模板,每个样本有5列,在数据中是默认用‘,'隔开的,然后解析的标准是[1],也即每一列的数值都解析为整型。[1.0]就是解析为浮点,['null']解析为string类型
相关推荐:
TensorFlow入门使用 tf.train.Saver()保存模型
关于Tensorflow中的tf.train.batch函数
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Tous les symboles d'expression dans les expressions régulières (résumé)