
Maison >développement back-end >Tutoriel Python >Exemple d'utilisation de python pour générer un pdf en txt
Exemple d'utilisation de python pour générer un pdf en txt

- 不言original
- 2018-04-23 15:16:592336parcourir
Ce qui suit est un exemple de la façon d'utiliser Python pour générer un pdf en txt. Il a une bonne valeur de référence et j'espère qu'il sera utile à tout le monde. Allons jeter un oeil
Un camarade de classe m'a posé une question à ce sujet il y a une semaine. Comme je participais au concours de Huawei auparavant, j'ai jeté un œil au concours et on m'a dit que je devais utiliser le package pdfminer. . Je l'ai donc installé, et le processus d'installation a été très simple :
sudo pip install pdfminer;
Il n'y a eu aucune erreur au milieu. Quant à comment l'appeler, je n'ai pas très bien étudié la bibliothèque pdfminer, alors j'ai lancé Baidu...
Documentation officielle : http://www .unixuser .org/~euske/python/pdfminer/index.html
Écrit entièrement en python. (Applicable à la version 2.4 ou plus récente)
Analysez, analysez et convertissez des documents PDF.
Prise en charge des spécifications PDF-1.7. (Presque)
Support du langage CJK et des scripts d'écriture verticale.
Prise en charge de différents types de polices (Type1, TrueType, Type3 et CID).
Prise en charge du cryptage de base (RC4).
Conversion PDF et HTML.
Extraction de contour (TOC).
extraction du contenu des balises.
Reconstruisez la mise en page originale en regroupant des blocs de texte.
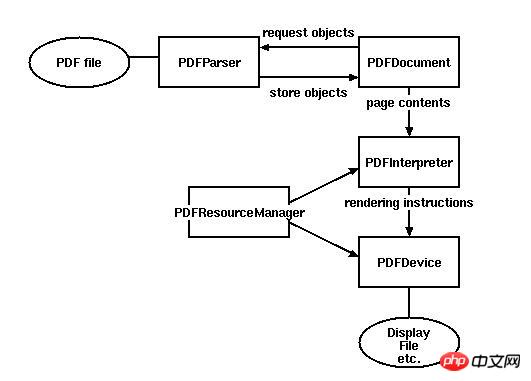
Quelques cours de base
PDFParser : récupère les données d'un fichier
PDFDocument : enregistre les données obtenues, et PDFParser est interdépendants
PDFPageInterpreter gère le contenu de la page
PDFDevice le traduit dans le format dont vous avez besoin
PDFResourceManager est utilisé pour stocker des ressources partagées telles que des polices ou des images.
Implémentation simple
Lisez test.pdf et affichez-le sous forme de sortie.txt :
# -*- coding: utf-8 -*-
from pdfminer.pdfparser import PDFParser
from pdfminer.pdfdocument import PDFDocument
from pdfminer.pdfpage import PDFPage
from pdfminer.pdfpage import PDFTextExtractionNotAllowed
from pdfminer.pdfinterp import PDFResourceManager
from pdfminer.pdfinterp import PDFPageInterpreter
from pdfminer.pdfdevice import PDFDevice
from pdfminer.layout import *
from pdfminer.converter import PDFPageAggregator
import os
fp = open('test.pdf', 'rb')
#来创建一个pdf文档分析器
parser = PDFParser(fp)
#创建一个PDF文档对象存储文档结构
document = PDFDocument(parser)
# 检查文件是否允许文本提取
if not document.is_extractable:
raise PDFTextExtractionNotAllowed
else:
# 创建一个PDF资源管理器对象来存储共赏资源
rsrcmgr=PDFResourceManager()
# 设定参数进行分析
laparams=LAParams()
# 创建一个PDF设备对象
# device=PDFDevice(rsrcmgr)
device=PDFPageAggregator(rsrcmgr,laparams=laparams)
# 创建一个PDF解释器对象
interpreter=PDFPageInterpreter(rsrcmgr,device)
# 处理每一页
for page in PDFPage.create_pages(document):
interpreter.process_page(page)
# 接受该页面的LTPage对象
layout=device.get_result()
for x in layout:
if(isinstance(x,LTTextBoxHorizontal)):
with open('output.txt','a') as f:
f.write(x.get_text().encode('utf-8')+'\n')
Recommandations associées :
Méthode Python pour convertir des PDF en images
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!