
Maison >développement back-end >tutoriel php >Algorithme de tri PHP Heap Sort (Heap Sort)
Algorithme de tri PHP Heap Sort (Heap Sort)

- 不言original
- 2018-04-21 14:17:252205parcourir
Cet article présente principalement l'algorithme de tri PHP (Heap Sort). Il analyse en détail les principes, les méthodes de mise en œuvre et les précautions d'utilisation associées du tri par tas sous forme d'exemples. Les amis dans le besoin peuvent s'y référer
.Cet article décrit l'algorithme de tri PHP Heap Sort avec des exemples. Partagez-le avec tout le monde pour votre référence, les détails sont les suivants :
Introduction à l'algorithme :
Ici, je cite directement le début de "Dahua Structure des données" :
Comme mentionné précédemment, le tri par sélection simple nécessite une comparaison n - 1 fois pour sélectionner le plus petit enregistrement parmi les n enregistrements à trier. Ceci est compréhensible. Trouver les premières données nécessite une comparaison comme celle-ci Plusieurs fois c'est normal, sinon comment savoir qu'il est le plus petit record.
Malheureusement, cette opération ne sauvegarde pas les résultats de comparaison de chaque voyage. Les résultats de comparaison dans ce dernier voyage sont plus lourds. De nombreuses comparaisons ont été effectuées lors du voyage précédent, mais en raison du voyage précédent, ces résultats de comparaison ont été. non sauvegardés lors du tri, ces opérations de comparaison ont donc été répétées lors de la passe de tri suivante, donc un plus grand nombre de comparaisons ont été enregistrées.
Si vous pouvez sélectionner le plus petit enregistrement à chaque fois et apporter les ajustements correspondants aux autres enregistrements en fonction des résultats de la comparaison, l'efficacité globale du tri sera très élevée. Le tri par tas est une amélioration par rapport au tri par sélection simple, et l'effet de cette amélioration est très évident.
Idée de base :
Avant d'introduire le tri par tas, introduisons d'abord le tas :
"Structure de données Dahua" 》Définition dans : Un tas est un arbre binaire complet avec les propriétés suivantes : la valeur de chaque nœud est supérieure ou égale à la valeur de ses nœuds enfants gauche et droit, devenant un grand tas supérieur (grand tas racine ou le) ; La valeur de chaque nœud est inférieure ou égale à sa valeur. Les valeurs des nœuds gauche et droit deviennent le petit tas supérieur (petit tas racine).
Quand j'ai vu cela, j'ai également eu des doutes quant à "si le tas est un arbre binaire complet". Il y a aussi des gens sur Internet qui disent que ce n'est pas un arbre binaire complet, mais que le tas soit ou non. est un arbre binaire complet, je réserve quand même mon avis. Il faut seulement savoir que nous utilisons ici un grand tas racine (petit tas racine) sous la forme d'un arbre binaire complet, principalement pour faciliter le stockage et le calcul (nous verrons la commodité plus tard).
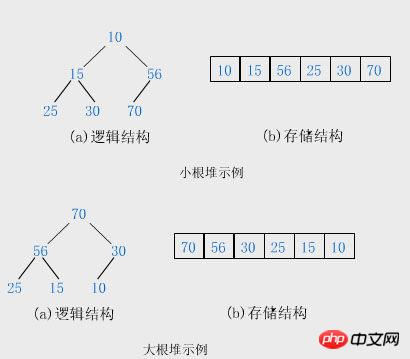
Algorithme de tri par tas :
Le tri par tas est une méthode de tri utilisant un tas (en supposant qu'il s'agit d'un grand tas racine). basic L'idée est : Construire la séquence à trier dans un grand tas racine. À ce stade, la valeur maximale de la séquence entière est le nœud racine en haut du tas. Supprimez-le (en fait, échangez-le avec le dernier élément du tableau de tas, auquel moment le dernier élément est la valeur maximale), puis reconstruisez les n - 1 séquences restantes dans un tas, de sorte que vous obteniez les n éléments La prochaine plus petite valeur. Si vous exécutez ceci à plusieurs reprises, vous pouvez obtenir une séquence ordonnée.
Opérations de base de l'algorithme de tri du tas de grandes racines :
①Construction de tas, la construction de tas est un processus de constante en ajustant le tas, commencez à ajuster de len/2 au premier nœud, où len est le nombre d'éléments dans le tas. Le processus de construction d'un tas est un processus linéaire. Le processus d'ajustement du tas est toujours appelé de len/2 à 0, ce qui équivaut à o(h1) + o(h2) ... + o(hlen/2) où h représente la profondeur du nœud, len /2 représente le nombre de nœuds. Il s'agit d'un processus de sommation et le résultat est linéaire O(n).
②Tas d'ajustement : Le tas d'ajustement sera utilisé dans le processus de construction du tas, et sera également utilisé dans le processus de tri du tas. L'idée est de comparer le nœud i avec ses nœuds enfants gauche(i) et droit(i), et de sélectionner le plus grand (ou le plus petit) des trois si la valeur la plus grande (la plus petite) n'est pas le nœud i mais l'un de ses nœuds enfants. , Là, le nœud i interagit avec le nœud, puis appelle le processus d'ajustement du tas. Il s'agit d'un processus récursif. La complexité temporelle du processus d'ajustement du tas est liée à la profondeur du tas. Il s'agit d'une opération de lgn car elle est ajustée dans le sens de la profondeur.
③Tri par tas : Le tri par tas est effectué à l'aide des deux processus ci-dessus. La première consiste à construire un tas basé sur des éléments. Retirez ensuite le nœud racine du tas (généralement échangez-le avec le dernier nœud), continuez le processus d'ajustement du tas avec les premiers nœuds len-1, puis retirez le nœud racine jusqu'à ce que tous les nœuds aient été supprimés. La complexité temporelle du processus de tri du tas est O(nlgn). Parce que la complexité temporelle de la construction d'un tas est O(n) (un appel) ; la complexité temporelle de l'ajustement du tas est lgn, et elle est appelée n-1 fois, donc la complexité temporelle du tri du tas est O(nlgn).
Ce processus nécessite beaucoup de schémas pour comprendre clairement, mais je suis paresseux. . . . . .
Implémentation de l'algorithme :
<?php
//堆排序(对简单选择排序的改进)
function swap(array &$arr,$a,$b){
$temp = $arr[$a];
$arr[$a] = $arr[$b];
$arr[$b] = $temp;
}
//调整 $arr[$start]的关键字,使$arr[$start]、$arr[$start+1]、、、$arr[$end]成为一个大根堆(根节点最大的完全二叉树)
//注意这里节点 s 的左右孩子是 2*s + 1 和 2*s+2 (数组开始下标为 0 时)
function HeapAdjust(array &$arr,$start,$end){
$temp = $arr[$start];
//沿关键字较大的孩子节点向下筛选
//左右孩子计算(我这里数组开始下标识 0)
//左孩子2 * $start + 1,右孩子2 * $start + 2
for($j = 2 * $start + 1;$j <= $end;$j = 2 * $j + 1){
if($j != $end && $arr[$j] < $arr[$j + 1]){
$j ++; //转化为右孩子
}
if($temp >= $arr[$j]){
break; //已经满足大根堆
}
//将根节点设置为子节点的较大值
$arr[$start] = $arr[$j];
//继续往下
$start = $j;
}
$arr[$start] = $temp;
}
function HeapSort(array &$arr){
$count = count($arr);
//先将数组构造成大根堆(由于是完全二叉树,所以这里用floor($count/2)-1,下标小于或等于这数的节点都是有孩子的节点)
for($i = floor($count / 2) - 1;$i >= 0;$i --){
HeapAdjust($arr,$i,$count);
}
for($i = $count - 1;$i >= 0;$i --){
//将堆顶元素与最后一个元素交换,获取到最大元素(交换后的最后一个元素),将最大元素放到数组末尾
swap($arr,0,$i);
//经过交换,将最后一个元素(最大元素)脱离大根堆,并将未经排序的新树($arr[0...$i-1])重新调整为大根堆
HeapAdjust($arr,0,$i - 1);
}
}
$arr = array(9,1,5,8,3,7,4,6,2);
HeapSort($arr);
var_dump($arr);
Résultat d'exécution :
array(9) {
[0]=>
int(1)
[1]=>
int(2)
[2]=>
int(3)
[3]=>
int(4)
[4]=>
int(5)
[5]=>
int(6)
[6]=>
int(7)
[7]=>
int(8)
[8]=>
int(9)
}
Analyse de complexité temporelle :
Son temps d'exécution est aussi long qu'il est consommé dans le construction initiale du couple Et sur le tri répété du tas de merde reconstitué.
Dans l'ensemble, la complexité temporelle du tri par tas est O(nlogn). Étant donné que le tri par tas n'est pas sensible à l'état de tri des enregistrements d'origine, sa complexité temporelle meilleure, pire et moyenne est O(nlogn). C'est évidemment bien meilleur en termes de performances que la complexité temporelle du bouillonnement, de la sélection simple et de l'insertion directe de O(n^2).
Le tri par tas est une méthode de tri instable.
Cet article est référencé à partir de "Dahua Data Structure". Il n'est enregistré ici que pour référence future.
Recommandations associées :
tri radix de l'algorithme de tri PHP (Radix Sort
algorithme de tri PHP de tri rapide (Quick Sort) et Son optimisation
Algorithme de tri PHP Merging Sort
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Tous les symboles d'expression dans les expressions régulières (résumé)