
Maison >développement back-end >tutoriel php >Stupide php+mysql pseudo-statique (vraie page html)
Stupide php+mysql pseudo-statique (vraie page html)

- 不言original
- 2018-04-19 10:22:261949parcourir
Le contenu de cet article concerne le pseudo-statique php+mysql (véritable page html existante). Il a une certaine valeur de référence. Maintenant, je le partage avec vous. Les amis dans le besoin peuvent s'y référer
Tout le monde devrait connaître le pseudo-statiquePar exemple, la page générée par votre page php est xxx.php?id=1
Pour le référencement et l'exploration facile par les moteurs de recherche tels que Baidu, et pour éviter les ressources du serveur ne sont pas occupées en cas de concurrence élevée
Nous devrions afficher le lien vers la page xxx.php?id=1 au format xxx_1.html ou similaire, de toute façon, le suffixe .html l'est.
<?php
//连接数据库
$con = mysql_connect("localhost","root","root");
//选择数据库
mysql_select_db("test", $con);
//查询数据库
$result = mysql_query("SELECT * FROM list");
//遍历输出数据库
while($row = mysql_fetch_array($result))
{
$url = $row["url"];
$id = $row["id"];
if(empty($url)){
echo "<a href='p.php?id=$id'/>$row[title]</a><br/>";
}else{
echo "<a href='http://localhost/20180417/$url'/>$row[title]</a><br/>";
}
}
mysql_close($con);
?> comme indiqué :

L'important est que la page p.php
interroge le champ URL de la base de données If. il est vide, puis démarrez file_get_contents pour obtenir le code html de la page entière, puis écrivez le code dans un fichier html nommé LKY_$id.html, où $id est l'identifiant de la page actuelle si l'identifiant de la page actuelle =. 1, Ensuite, le nom du fichier généré est LKY_1.html, puis le nom du fichier est mis à jour dans le champ URL de la base de données
<!DOCTYPE html>
<html>
<head>
</head>
<body>
<?php
//连接数据库
$con = mysql_connect("localhost","root","root");
//选择数据库
mysql_select_db("test", $con);
//获得id
$id =$_GET["id"];
//查询数据库
$result = mysql_query("SELECT * FROM list where id =".$id);
//遍历输出数据库
while($row = mysql_fetch_array($result))
{
$url = $row["url"];
if(empty($url)){
$get_html = "http://localhost/20180417/get_html.php?id=$id";
$html_utl = "LKY_$id.html";
$con_html = file_get_contents($get_html);
$html = fopen($html_utl, "w");
fwrite($html, $con_html);
fclose($html);
echo $row["zhengwen"];
mysql_query("UPDATE list SET url = '$html_utl' WHERE id = '$id'");
}else{
echo $row["zhengwen"];
}
}
mysql_close($con);
?>
</body>
</html>Lorsque l'utilisateur accède à xxx.p.php?id= 1, La base de données sera interrogée si le champ url est vide, le html de la page entière sera obtenu à l'aide d'un get_html.php
<!DOCTYPE html>
<html>
<head>
</head>
<body>
<?php
//连接数据库
$con = mysql_connect("localhost","root","root");
//选择数据库
mysql_select_db("test", $con);
//获得id
$id =$_GET["id"];
//查询数据库
$result = mysql_query("SELECT * FROM list where id =".$id);
//遍历输出数据库
while($row = mysql_fetch_array($result))
{
echo $row["zhengwen"];
}
mysql_close($con);
?>
</body>
</html>Après l'avoir obtenu, générez un fichier html et enregistrez-le dans le répertoire que nous précisons sur le serveur Si vous accédez à xxx.p.php?id=1 et jugez-le. le champ URL n'est pas vide, les données de la page seront affichées directement ou passez à LKY_1.html
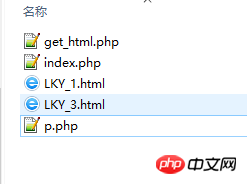
.
Ensuite, un jugement correspondant est effectué dans la liste sur la page d'accueil pour déterminer si l'URL est vide, si elle est vide, la sortie est le lien hypertexte de p.php?id=1, sinon de. la base de données Prenez le nom du fichier html du champ URL, puis affichez LKY_1.html
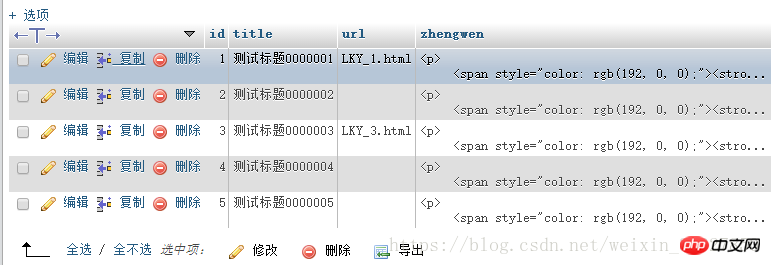
Ce que je veux dire, c'est que cela génère en fait des fichiers HTML !
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Tous les symboles d'expression dans les expressions régulières (résumé)