
Maison >développement back-end >Tutoriel Python >Comment selenium+python explore le site Web de Jianshu
Comment selenium+python explore le site Web de Jianshu

- 零到壹度original
- 2018-04-16 09:52:564478parcourir
Cet article présente comment selenium+python explore le site Web de Jianshu. Il a une certaine valeur de référence. Maintenant, je le partage avec vous. Les amis dans le besoin peuvent s'y référer
.
Logique de chargement des pages
Lorsque vous apprenez avec enthousiasme les connaissances de base des robots d'exploration sur Internet, c'est comme trouver une cible pour pratiquer Ensuite, le petit livre avec un grand nombre d'articles contient beaucoup d'informations précieuses, cela deviendra donc naturellement votre choix si vous l'essayez, vous constaterez que ce n'est pas aussi simple que vous le pensez, car il contient beaucoup de transmission de données liées à js. . Permettez-moi d'abord d'utiliser un robot d'exploration traditionnel pour démontrer : >
Ouvrez la page d'accueil du Jianshu, il ne semble y avoir rien de spécial

Page d'accueil de Jianshu
Ouvrez le mode développeur de
chromeet constatez que le titre de l'article ethrefsont tous dans la balisea, et il ne semble y avoir aucune différence

a.png
L'étape suivante consiste à trouver toutes les balises
apparaisse en bas.asur la page, mais attendez si vous regardez soigneusement, vous constaterez que la poulie est à moitié roulée. Ensuite, la page se chargera davantage, et cette étape sera répétée trois fois jusqu'à ce que le bouton阅读更多

Pulley
Non seulement cela, mais la lecture en bas
hrefne nous dit pas de charger le reste des informations de la page , le seul moyen est不断点击阅读更多这个按钮
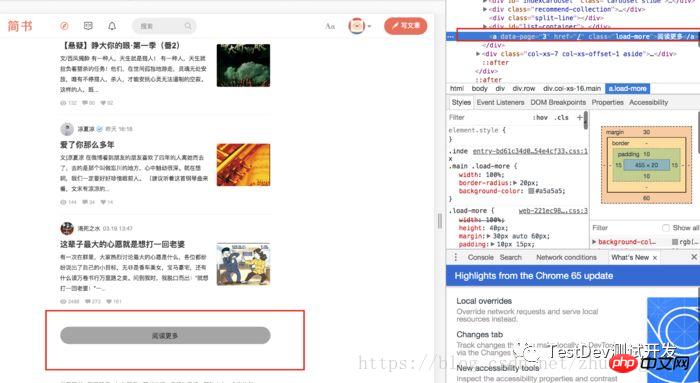
load_more.png
quoi, répétez la poulie trois fois pour la faire glisser vers le bas au centre de la pageetCliquer continuellement sur le boutonCe type d'opérationhttpne peut pas être effectué avec des requêtes. Est-ce plutôt une opération js ? C'est vrai, l'article de Jianshu n'est pas une requête http régulière. Nous ne pouvons pas rediriger constamment selon différentes URL, mais certaines actions sur la page pour charger les informations de la page.

Introduction à Selenium
Selenium est un outil de test d'automatisation Web qui prend en charge de nombreux langages. Nous pouvons utiliser le sélénium de Python ici lorsqu'il est utilisé comme. un robot d'exploration, en train d'explorer des livres courts, son principe de fonctionnement est d'injecter en continu du code js, de laisser la page se charger en continu et enfin d'extraire toutes les balises a. Vous devez d'abord télécharger le package selenium en python
>>> pip3 install selenium
chromedriver
selenium doit être utilisé avec un navigateur. Ici, j'utilise chromedriver, la version bêta open source. version de Chrome, il peut utiliser le mode sans tête pour accéder aux pages Web sans afficher le premier paragraphe, ce qui constitue la fonctionnalité la plus importante.
python中操作
在写代码之前一定要把chromedriver同一文件夹内,因为我们需要引用PATH,这样方便点。首先我们的第一个任务是刷出加载更多的按钮,需要做3次将滑轮重复三次滑倒页面的中央,这里方便起见我滑到了底部
from selenium import webdriverimport time
browser = webdriver.Chrome("./chromedriver")
browser.get("https://www.jianshu.com/")for i in range(3):
browser.execute_script("window.scrollTo(0, document.body.scrollHeight);") // execute_script是插入js代码的
time.sleep(2) //加载需要时间,2秒比较合理
看看效果
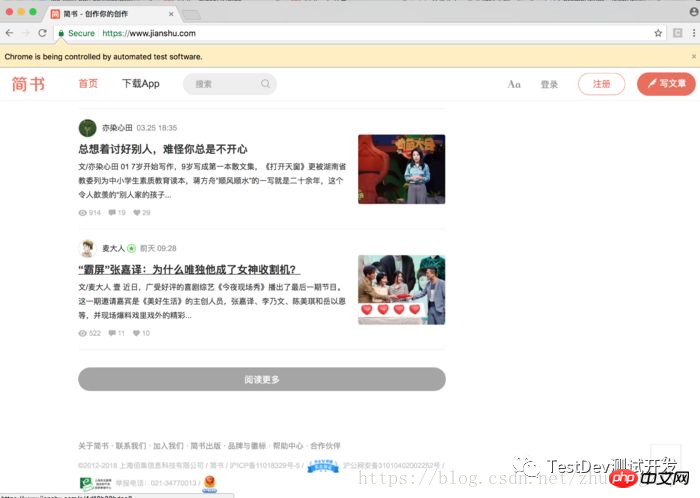
刷出了按钮
接下来就是不断点击按钮加载页面,继续加入刚才的py文件之中
for j in range(10): //这里我模拟10次点击
try:
button = browser.execute_script("var a = document.getElementsByClassName('load-more'); a[0].click();")
time.sleep(2) except: pass'''
上面的js代码说明一下
var a = document.getElementsByClassName('load-more');选择load-more这个元素
a[0].click(); 因为a是一个集合,索引0然后执行click()函数
'''
这个我就不贴图了,成功之后就是不断地加载页面 ,知道循环完了为止,接下来的工作就简单很多了,就是寻找a标签,get其中的text和href属性,这里我直接把它们写在了txt文件之中.
titles = browser.find_elements_by_class_name("title")with open("article_jianshu.txt", "w", encoding="utf-8") as f: for t in titles: try:
f.write(t.text + " " + t.get_attribute("href"))
f.write("\n") except TypeError: pass
最终结果
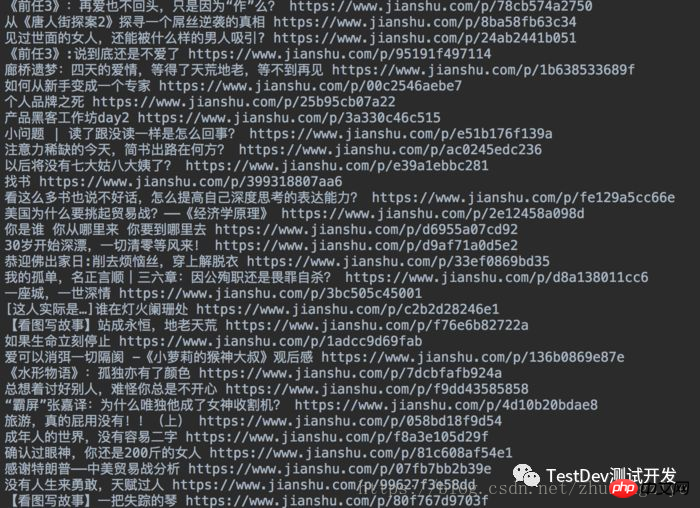
简书文章
headless模式
不断加载页面肯定也很烦人,所以我们测试成功之后并不想把浏览器显示出来,这需要加上headless模式
options = webdriver.ChromeOptions()
options.add_argument('headless')
browser = webdriver.Chrome("./chromedriver", chrome_options=options) //把上面的browser加入chrome_options参数
总结
当我们没办法使用正常的http请求爬取时,可以使用selenium操纵浏览器来抓取我们想要的内容,这样有利有弊,比如
优点
可以暴力爬虫
简书并不需要cookie才能查看文章,不需要费劲心思找代理,或者说我们可以无限抓取并且不会被ban
首页应该为ajax传输,不需要额外的http请求
缺点
爬取速度太满,想象我们的程序,点击一次需要等待2秒那么点击600次需要1200秒, 20分钟...
附加
这是所有完整的代码
from selenium import webdriverimport time
options = webdriver.ChromeOptions()
options.add_argument('headless')
browser = webdriver.Chrome("./chromedriver", chrome_options=options)
browser.get("https://www.jianshu.com/")for i in range(3):
browser.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(2)# print(browser)for j in range(10): try:
button = browser.execute_script("var a = document.getElementsByClassName('load-more'); a[0].click();")
time.sleep(2) except: pass#titles = browser.find_elements_by_class_name("title")with open("article_jianshu.txt", "w", encoding="utf-8") as f: for t in titles: try:
f.write(t.text + " " + t.get_attribute("href"))
f.write("\n") except TypeError: pass
相关推荐:
[python爬虫] Selenium爬取新浪微博内容及用户信息
[Python爬虫]利用Selenium等待Ajax加载及模拟自动翻页,爬取东方财富网公司公告
Python爬虫:Selenium+ BeautifulSoup 爬取JS渲染的动态内容(雪球网新闻)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!