
Maison >développement back-end >Tutoriel Python >Comment utiliser Python pour explorer les commentaires populaires sur NetEase Cloud Music
Comment utiliser Python pour explorer les commentaires populaires sur NetEase Cloud Music

- 零到壹度original
- 2018-04-11 17:33:253413parcourir
Le contenu partagé dans cet article explique comment utiliser Python pour explorer les commentaires populaires sur NetEase Cloud Music. Il a une certaine valeur de référence. Les amis dans le besoin peuvent s'y référer
Avant-propos
Récemment, j'ai étudié le contenu lié au text mining. Une femme dite intelligente ne peut pas préparer un repas sans riz. Pour effectuer une analyse de texte, vous devez d'abord disposer d'un texte. Il existe de nombreuses façons d'obtenir du texte, par exemple en téléchargeant des documents texte prêts à l'emploi sur Internet ou en obtenant des données via des API fournies par des tiers. Mais parfois, les données que nous souhaitons ne peuvent pas être obtenues directement car il n’existe pas de canal de téléchargement direct ni d’API permettant d’obtenir les données. Alors que devons-nous faire à ce moment-là ? Une meilleure façon consiste à utiliser un robot d'exploration Web, qui consiste à écrire un programme informatique pour se faire passer pour un utilisateur afin d'obtenir les données souhaitées. Grâce à l'efficacité des ordinateurs, nous pouvons obtenir des données facilement et rapidement.
À propos des robots
Alors, comment écrire un robot Étoffe de laine? Il existe de nombreux langagesqui peuvent être utilisés pour écrire des robots, tels que Java, php, python, etc. Personnellement, je préfère utiliser python. Parce que Python possède non seulement de puissantes bibliothèques réseau intégrées, mais également de nombreuses excellentes bibliothèques tierces. D'autres ont directement construit la roue, et nous pouvons simplement l'utiliser. Cela apporte une grande commodité à l'écriture de robots. Il n'est pas exagéré de dire que vous pouvez réellement écrire un petit robot avec moins de 10 lignes de code python, alors que l'utilisation d'autres langages peut vous obliger à écrire beaucoup plus de code Être simple et. facile à comprendre est un énorme avantage de python .
Bon, sans plus tarder, passons au sujet principal d'aujourd'hui. NetEase Cloud Music est devenu très populaire ces dernières années. Je suis un utilisateur de NetEase Cloud Music et je l'utilise depuis plusieurs années. J'ai utilisé QQ Music et Kugou dans le passé. Grâce à ma propre expérience personnelle, je pense que les meilleures fonctionnalités de NetEase Cloud Music sont ses recommandations de chansons précises et ses commentaires d'utilisateurs uniques (Déclaration formelle !!! Ce n'est pas un article doux, pas une publicité ! C'est juste une opinion personnelle, ne la critiquez pas ). Il y aura souvent des commentaires sous une chanson qui a reçu de nombreux likes. Couplé au fait que NetEase Cloud Music a mis dans le métro des avis d'utilisateurs sélectionnés il y a quelques jours, les avis de NetEase Cloud Music sont redevenus populaires. Je souhaite donc analyser les commentaires de NetEase Cloud et découvrir les modèles, notamment les caractéristiques communes de certains commentaires chauds. Dans ce but, j'ai commencé à explorer les commentaires NetEase Cloud.
Bibliothèque réseau
Python a deux bibliothèques réseau intégrées, urllib et urllib2, mais ces deux bibliothèques ne sont pas particulièrement pratiques à utiliser, nous utilisons donc ici une bibliothèque tierce bien reçue requêtes. À l'aide de requêtes, vous pouvez réaliser des travaux d'exploration plus complexes, tels que la configuration d'agents et la simulation de connexions avec seulement quelques lignes de code. Si pip est déjà installé, utilisez simplement les requêtes d'installation de pip pour l'installer.
L'adresse du document chinois est ici http://docs.python-requests.org/zh_CN/latest/user/quickstart. html
Si vous avez des questions, vous pouvez vous référer à la documentation officielle, ci-dessus Il y aura une introduction très détaillée. Quant aux deux bibliothèques urllib et urllib2, elles sont également bien utiles je vous les présenterai si j'en ai l'occasion dans le futur.
Principe de fonctionnement
Avant de commencer officiellement à présenter le robot, parlons d'abord des bases travail du robot d'exploration. Principe, nous savons que lorsque nous ouvrons le navigateur pour visiter une certaine URL, nous envoyons essentiellement une certaine requête au serveur Une fois que le serveur aura reçu notre demande, il renverra les données en conséquence. à notre demande, puis transmettez-la via le navigateur. Analysez ces données et présentez-les devant nous.
Si nous utilisons le code , nous devons ignorer l'étape du navigateur et aller directement Envoyer certaines données au serveur, puis récupérer les données renvoyées par le serveur pour extraire les informations souhaitées.
Mais le problème est que parfois le serveur doit vérifier la demande que nous envoyons. S'il pense que notre demande est illégale, aucune donnée ne sera envoyée. renvoyé, sinon des données incorrectes seront renvoyées. Ainsi, afin d'éviter cette situation, nous devons parfois déguiser le programme en utilisateur normal afin d'obtenir avec succès une réponse du serveur.
Comment le déguiser ?
Cela dépend de la différence entre les utilisateurs qui accèdent à une page Web via un navigateur et nous qui accédons à une page Web via un programme.
De manière générale, lorsque nous accédons à une page Web via un navigateur, en plus d'envoyer l'URL visitée, des informations supplémentaires seront envoyées au service. Informations , telles que les en-têtes (informations d'en-tête), etc., qui sont équivalentes au certificat d'identité de la demande. Lorsque le serveur verra ces données, il saura que nous y accédons via un navigateur normal, et il renverra les données docilement.
Connexion simulée
Notre programme doit donc être comme un navigateur, apportant ces informations qui marquent notre identité lors de l'envoi d'une demande, afin que nous puissions obtenir les données en douceur. Parfois, nous devons être connectés pour obtenir certaines données, nous devons donc simuler la connexion.
Essentiellement, se connecter via un navigateur signifie publier certaines informations du formulaire sur le serveur (y compris le nom d'utilisateur, le mot de passe et d'autres informations après vérification du serveur). Nous pouvons nous connecter en douceur, et il en va de même pour l'application. Nous pouvons simplement envoyer les données publiées telles quelles par le navigateur.
À propos de la connexion simulée , je l'introduireai plus tard. Bien sûr, les choses ne se passent parfois pas aussi bien, car certains sites Internet ont mis en place des mesures anti-crawling Par exemple, si l'accès est trop rapide, l'adresse IP sera parfois bloquée (typiquement Douban). . Pour le moment, nous devons encore configurer un serveur proxy, c'est-à-dire changer notre adresse IP si une IP est bloquée, passer à une autre IP. Comment procéder spécifiquement, nous parlerons de ces sujets plus tard.
Conseils
Enfin, permettez-moi de vous présenter une petite astuce qui me semble très utile dans le processus d'écriture d'un robot. Si vous utilisez Firefox ou Chrome, vous avez peut-être remarqué un endroit appelé outils de développement (chrome) ou console Web (firefox). Cet outil est très utile car nous pouvons voir clairement quelles informations le navigateur envoie et quelles informations le serveur renvoie lors de la visite d'un site Web. Ces informations sont la clé pour écrire un robot. Ci-dessous, vous verrez à quel point cela peut être utile.
Comment explorer les commentaires
Ouvrez d'abord la version Web de NetEase Cloud Music et sélectionnez une chanson pour l'ouvrir page Web, je prends ici "Sunny Day" de Jay Chou comme exemple. Comme indiqué ci-dessous :
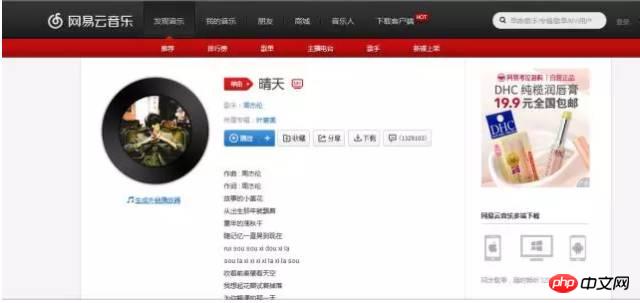
Ensuite, ouvrez la console Web (ouvrez les outils de développement pour Chrome, cela devrait être similaire pour les autres navigateurs), comme indiqué ci-dessous :
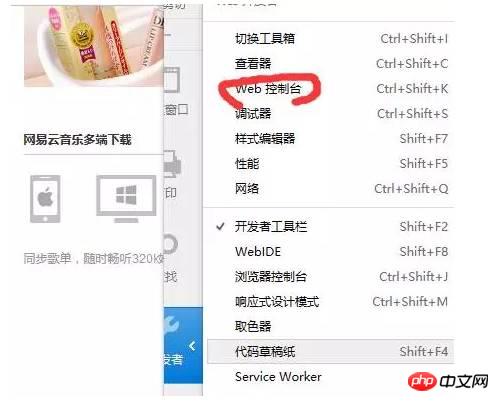
Ensuite, à ce moment-là, nous devons cliquer sur le réseau, effacer toutes les informations, puis cliquer sur Renvoyer (équivalent à actualiser le navigateur), de cette manière, nous pouvons voir intuitivement quelles informations le navigateur envoie et à quelles informations le serveur répond. Comme indiqué ci-dessous :
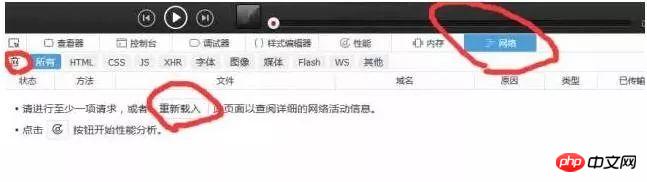
Les données obtenues après actualisation sont les suivantes

Vous pouvez voir que le navigateur envoie beaucoup d'informations, alors lequel faire nous voulons ? Que veux-tu ? Ici, nous pouvons faire un jugement préliminaire via le code d'état. Le code d'état marque l'état de la demande du serveur. Ici le code d'état 200 signifie que la demande est normale, tandis que 304 signifie qu'il s'agit d'une anomalie <.> (Il existe de nombreux types de codes de statut. Si vous souhaitez en savoir plus, vous pouvez le rechercher par vous-même. La signification spécifique de 304 ne sera pas mentionnée ici) . Nous n'avons donc généralement besoin d'examiner que les requêtes avec le code d'état 200. De plus, nous pouvons observer grossièrement les informations renvoyées par le serveur (ou afficher la réponse) via l'aperçu dans la colonne de droite. Comme indiqué ci-dessous :
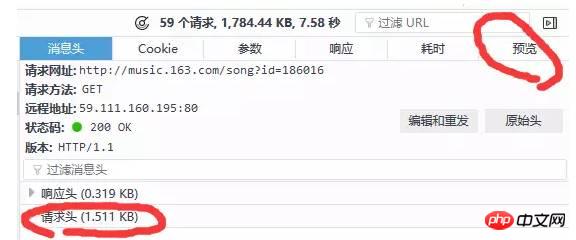
get et post. Une autre chose sur laquelle il faut se concentrer est l'en-tête de la requête, qui contient l'utilisateur -. Agent (informations sur le client), référence (d'où accéder) et autres informations. Généralement, nous apporterons les informations d'en-tête, qu'il s'agisse de la méthode get ou post. Les informations d'en-tête sont les suivantes :
De plus, il convient de noter que : dans les requêtes get, généralement les paramètres de la requête sont directement modifiés en ? paramètre1=value1¶meter2=value2 etc. sont envoyés sous cette forme, il n'est donc pas nécessaire d'apporter des paramètres de requête supplémentaires, tandis que les demandes de publication doivent généralement apporter des paramètres supplémentaires au lieu de placer directement les paramètres dans l'URL. parfois, nous devons encore faire attention à la colonne des paramètres. Après une recherche minutieuse, nous avons finalement trouvé la demande originale liée au commentaire sur http://music.163.com/weapi/v1/resource/comments/R_SO_4_186016?csrf_token= Cette demande Parmi eux, comme indiqué ci-dessous :
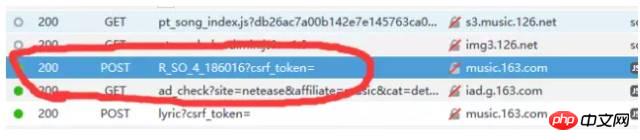
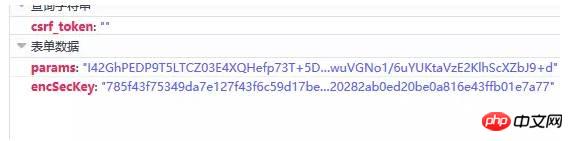
Cliquez sur cette demande , nous avons constaté qu'il s'agissait d'une requête de publication. Il y a deux paramètres dans la requête, l'un est params et l'autre est encSecKey. Les valeurs de ces deux paramètres sont très longues, et on a l'impression qu'elles le sont. crypté. Comme indiqué ci-dessous :
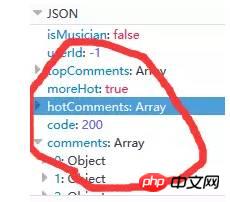
Les données liées aux commentaires renvoyés par le serveur sont au format json, qui contient des informations très riches (telles que des informations sur le commentateur, la date du commentaire, le nombre de likes, le contenu du commentaire, etc.), comme le montre la figure 9 ci-dessous : (En fait, hotComments sont des commentaires chauds et les commentaires sont un tableau de commentaires)
À ce stade, nous avons déterminé la direction, c'est-à-dire qu'il nous suffit de déterminer les valeursdes deux paramètres params et encSecKey. Ce problème m'a troublé tout l'après-midi. dessus depuis longtemps mais je n'arrive toujours pas à comprendre ces deux paramètres méthode de cryptage, mais j'ai découvert un modèle, http://music.163.com/weapi/v1/resource/comments. /R_SO_4_186016?csrf_token= dans R_SO_4_ Le nombre après est la valeur d'identification de la chanson pour les valeurs param et encSecKeyde différentes chansons, si les deux valeurs de paramètre . d'une chanson telle que A sont passées à la chanson B, alors pour un même numéro de page, ce paramètre est universel, c'est à dire si les deux valeurs de paramètres de la première page de A sont passées aux deux paramètres de n'importe quel autre chanson, les commentaires de la première page de la chanson correspondante peuvent être obtenus. Pour la deuxième page, il en va de même pour trois pages et ainsi de suite.
Mais malheureusement, différents paramètres de page sont différents, cette méthode ne peut capturer que quelques pages limitées (bien sûr, c'est suffisant pour capturer le nombre total de commentaires et de commentaires populaires), si vous souhaitez capturer toutes les données, vous devez comprendre la méthode de cryptage de ces deux valeurs de paramètres.
Je pensais ne pas avoir compris, alors hier soir je suis allé à Zhihu pour chercher cette question, et j'ai en fait trouvé la réponse. @ Petite Fée à la poitrine plate Cet ami m'a expliqué en détail comment déchiffrer le processus de cryptage de ces deux paramètres. Je l'ai étudié et j'ai trouvé que c'était encore un peu compliqué. Je l'ai modifié selon la méthode écrite par Ami , j'ai réussi à obtenir tous les commentaires. Je voudrais exprimer ma gratitude à Zhihu@petite fée à la poitrine plate.
Jusqu'à présent, nous avons fini d'expliquer comment capturer toutes les données des commentaires de NetEase Cloud Music. Comme d'habitude, j'ai téléchargé le code en dernier, et cela a fonctionné lors de mon propre test :
#!/usr/bin/env python2.7
# -*- coding: utf-8 -*-
# @Time : 2017/3/28 8:46
# @Author : Lyrichu
# @Email : 919987476@qq.com
# @File : NetCloud_spider3.py '''
@Description:
网易云音乐评论爬虫,可以完整爬取整个评论
部分参考了@平胸小仙女的文章
来源:知乎
''' from Crypto.Cipher import AES
import base64
import requests
import json
import codecs
import time
# 头部信息
headers = {
'Host':"music.163.com",
'Accept-Language':"zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
'Accept-Encoding':"gzip, deflate",
'Content-Type':"application/x-www-form-urlencoded",
'Cookie':"_ntes_nnid=754361b04b121e078dee797cdb30e0fd,1486026808627; _ntes_nuid=754361b04b121e078dee797cdb30e0fd; JSESSIONID-WYYY=yfqt9ofhY%5CIYNkXW71TqY5OtSZyjE%2FoswGgtl4dMv3Oa7%5CQ50T%2FVaee%2FMSsCifHE0TGtRMYhSPpr20i%5CRO%2BO%2B9pbbJnrUvGzkibhNqw3Tlgn%5Coil%2FrW7zFZZWSA3K9gD77MPSVH6fnv5hIT8ms70MNB3CxK5r3ecj3tFMlWFbFOZmGw%5C%3A1490677541180; _iuqxldmzr_=32; vjuids=c8ca7976.15a029d006a.0.51373751e63af8; vjlast=1486102528.1490172479.21; __gads=ID=a9eed5e3cae4d252:T=1486102537:S=ALNI_Mb5XX2vlkjsiU5cIy91-ToUDoFxIw; vinfo_n_f_l_n3=411a2def7f75a62e.1.1.1486349441669.1486349607905.1490173828142; P_INFO=m15527594439@163.com|1489375076|1|study|00&99|null&null&null#hub&420100#10#0#0|155439&1|study_client|15527594439@163.com; NTES_CMT_USER_INFO=84794134%7Cm155****4439%7Chttps%3A%2F%2Fsimg.ws.126.net%2Fe%2Fimg5.cache.netease.com%2Ftie%2Fimages%2Fyun%2Fphoto_default_62.png.39x39.100.jpg%7Cfalse%7CbTE1NTI3NTk0NDM5QDE2My5jb20%3D; usertrack=c+5+hljHgU0T1FDmA66MAg==; Province=027; City=027; _ga=GA1.2.1549851014.1489469781; __utma=94650624.1549851014.1489469781.1490664577.1490672820.8; __utmc=94650624; __utmz=94650624.1490661822.6.2.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; playerid=81568911; __utmb=94650624.23.10.1490672820",
'Connection':"keep-alive",
'Referer':'http://music.163.com/' }
# 设置代理服务器
proxies= {
'http:':'http://121.232.146.184',
'https:':'https://144.255.48.197'
}
# offset的取值为:
(评论页数-1)*20,total第一页为true,其余页为false # first_param = '{rid:"", offset:"0", total:"true", limit:"20", csrf_token:""}'
# 第一个参数 second_param = "010001"
# 第二个参数
# 第三个参数 third_param = "00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7"
# 第四个参数 forth_param = "0CoJUm6Qyw8W8jud"
# 获取参数 def get_params(page):
# page为传入页数
iv = "0102030405060708"
first_key = forth_param
second_key = 16 * 'F'
if(page == 1): # 如果为第一页
first_param = '{rid:"", offset:"0", total:"true", limit:"20", csrf_token:""}'
h_encText = AES_encrypt(first_param, first_key, iv)
else:
offset = str((page-1)*20)
first_param = '{rid:"", offset:"%s", total:"%s", limit:"20", csrf_token:""}' %(offset,'false')
h_encText = AES_encrypt(first_param, first_key, iv)
h_encText = AES_encrypt(h_encText, second_key, iv)
return h_encText
# 获取 encSecKey
def get_encSecKey():
encSecKey = "257348aecb5e556c066de214e531faadd1c55d814f9be95fd06d6bff9f4c7a41f831f6394d5a3fd2e3881736d94a02ca919d952872e7d0a50ebfa1769a7a62d512f5f1ca21aec60bc3819a9c3ffca5eca9a0dba6d6f7249b06f5965ecfff3695b54e1c28f3f624750ed39e7de08fc8493242e26dbc4484a01c76f739e135637c"
return encSecKey
# 解密过程
def AES_encrypt(text, key, iv):
pad = 16 - len(text) % 16
text = text + pad * chr(pad)
encryptor = AES.new(key, AES.MODE_CBC, iv)
encrypt_text = encryptor.encrypt(text)
encrypt_text = base64.b64encode(encrypt_text)
return encrypt_text
# 获得评论json数据
def get_json(url, params, encSecKey):
data = {
"params": params,
"encSecKey": encSecKey
}
response = requests.post(url, headers=headers, data=data,proxies = proxies)
return response.content
# 抓取热门评论,返回热评列表
def get_hot_comments(url):
hot_comments_list = []
hot_comments_list.append(u"用户ID 用户昵称 用户头像地址 评论时间 点赞总数 评论内容")
params = get_params(1) # 第一页
encSecKey = get_encSecKey()
json_text = get_json(url,params,encSecKey)
json_dict = json.loads(json_text)
hot_comments = json_dict['hotComments'] # 热门评论
print("共有%d条热门评论!" % len(hot_comments))
for item in hot_comments:
comment = item['content'] # 评论内容
likedCount = item['likedCount'] # 点赞总数
comment_time = item['time'] # 评论时间(时间戳)
userID = item['user']['userID'] # 评论者id
nickname = item['user']['nickname'] # 昵称
avatarUrl = item['user']['avatarUrl'] # 头像地址
comment_info = userID + " " + nickname + " " + avatarUrl + " " + comment_time + " " + likedCount + " " + comment + u""
hot_comments_list.append(comment_info)
return hot_comments_list
# 抓取某一首歌的全部评论
def get_all_comments(url):
all_comments_list = [] # 存放所有评论
all_comments_list.append(u"用户ID 用户昵称 用户头像地址 评论时间 点赞总数 评论内容") # 头部信息
params = get_params(1)
encSecKey = get_encSecKey()
json_text = get_json(url,params,encSecKey)
json_dict = json.loads(json_text)
comments_num = int(json_dict['total'])
if(comments_num % 20 == 0):
page = comments_num / 20
else:
page = int(comments_num / 20) + 1
print("共有%d页评论!" % page)
for i in range(page): # 逐页抓取
params = get_params(i+1)
encSecKey = get_encSecKey()
json_text = get_json(url,params,encSecKey)
json_dict = json.loads(json_text)
if i == 0:
print("共有%d条评论!" % comments_num) # 全部评论总数
for item in json_dict['comments']:
comment = item['content'] # 评论内容
likedCount = item['likedCount'] # 点赞总数
comment_time = item['time'] # 评论时间(时间戳)
userID = item['user']['userId'] # 评论者id
nickname = item['user']['nickname'] # 昵称
avatarUrl = item['user']['avatarUrl'] # 头像地址
comment_info = unicode(userID) + u" " + nickname + u" " + avatarUrl + u" " + unicode(comment_time) + u" " + unicode(likedCount) + u" " + comment + u""
all_comments_list.append(comment_info)
print("第%d页抓取完毕!" % (i+1))
return all_comments_list
# 将评论写入文本文件
def save_to_file(list,filename):
with codecs.open(filename,'a',encoding='utf-8') as f:
f.writelines(list)
print("写入文件成功!")
if __name__ == "__main__":
start_time = time.time() # 开始时间
url = "http://music.163.com/weapi/v1/resource/comments/R_SO_4_186016/?csrf_token="
filename = u"晴天.txt"
all_comments_list = get_all_comments(url)
save_to_file(all_comments_list,filename)
end_time = time.time() #结束时间
print("程序耗时%f秒." % (end_time - start_time))J'ai exécuté une course en utilisant le code ci-dessus et j'ai capté deux des chansons populaires de Jay Chou "Sunny Day" (avec plus de 1,3 million de commentaires) et "Confession Balloon" (avec plus de 200 000 commentaires), le premier a duré environ 20 minutes et le second a duré plus de 6 600 secondes (soit près de 2 heures). les captures d'écran sont les suivantes :
Notez que je les ai séparées par espaces, chaque ligne a ID utilisateur Pseudonyme de l'utilisateur Adresse de l'avatar de l'utilisateur Heure du commentaire Nombre total de likes Contenu du commentaire Ce contenu. Étudiants Lorsque vous exécutez le code à capturer par vous-même, veillez à ne pas ouvrir trop de threads et à ne pas mettre trop de pression sur le serveur NetEase Cloud (Il fut un temps où le serveur renvoyait des données très lentement. Je ne sais pas si c'est une limitation. J'ai visité et je me suis amélioré plus tard) . Je pourrai effectuer moi-même une analyse visuelle des données des commentaires plus tard, alors restez à l'écoute !
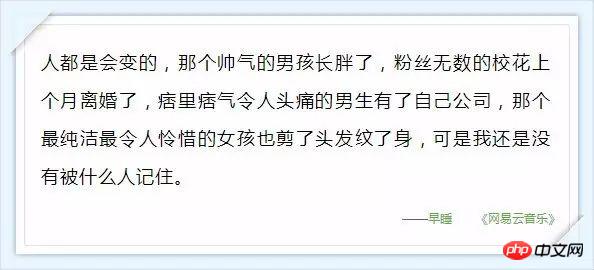
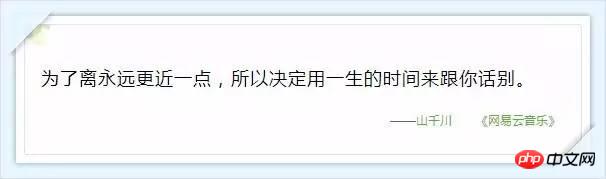
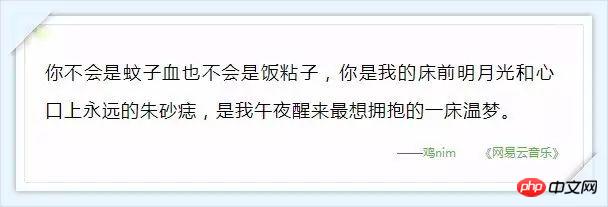
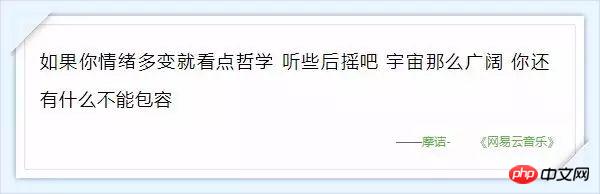
Annexe : Ces commentaires qui font chaud au cœur

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!