
Maison >Java >javaDidacticiel >Compréhension approfondie des transactions distribuées JAVA
Compréhension approfondie des transactions distribuées JAVA

- 零到壹度original
- 2018-04-03 14:33:532580parcourir
Cet article présente principalement une compréhension approfondie des transactions distribuées JAVA. L'éditeur pense qu'il est plutôt bon. Maintenant, je vais le partager avec vous et vous donner une référence. Suivons l'éditeur et jetons un coup d'œil.
1. Qu'est-ce qu'une transaction distribuée
La transaction distribuée fait référence aux participants de la transaction, le serveur qui prend en charge la transaction. transaction, et le serveur de ressources et les gestionnaires de transactions sont situés sur différents nœuds dans différents systèmes distribués. Ce qui précède est l'explication de l'Encyclopédie Baidu. En termes simples, une grande opération est composée de différentes petites opérations. Ces petites opérations sont distribuées sur différents serveurs et appartiennent à différentes applications. Les transactions distribuées doivent garantir que ces petites opérations réussissent toutes. échouer tout. Essentiellement, les transactions distribuées visent à garantir la cohérence des données dans différentes bases de données.
2. Raisons des transactions distribuées
2.1. Sous-base de données et table
Lorsque les données sont générées par une seule table de base de données en un an dépasse 1000W, nous devons alors envisager le partage de bases de données et de tables. Les principes spécifiques du partage de bases de données et de tables ne seront pas expliqués ici. J'entrerai dans les détails plus tard lorsque j'aurai le temps. Pour le dire simplement, la base de données d'origine est devenue multiple. bases de données. À ce stade, si une opération accède à la fois à la bibliothèque 01 et à la bibliothèque 02, et que la cohérence des données doit être assurée, alors des transactions distribuées doivent être utilisées.
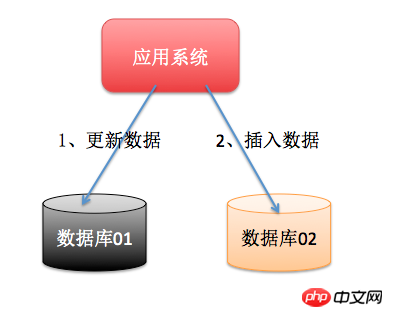
2.2. Appliquer la SOA
La soi-disant SOA est l'activité orientée services. Par exemple, une seule machine prenait à l'origine en charge l'ensemble du site Web de commerce électronique, mais maintenant l'ensemble du site Web a été démantelé et séparé en centre de commande, centre utilisateur et centre d'inventaire. Pour le centre de commande, il existe une base de données spéciale pour stocker les informations de commande, le centre utilisateur dispose également d'une base de données spéciale pour stocker les informations sur les utilisateurs et le centre d'inventaire dispose également d'une base de données spéciale pour stocker les informations d'inventaire. À l'heure actuelle, si vous souhaitez gérer les commandes et l'inventaire en même temps, cela impliquera la base de données des commandes et la base de données des stocks. Afin de garantir la cohérence des données, vous devez utiliser des transactions distribuées.
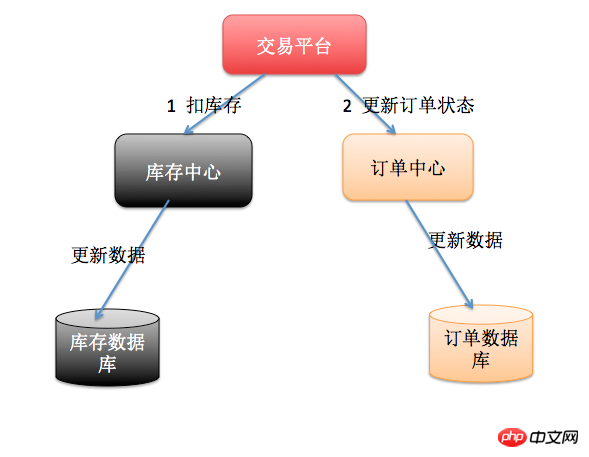
Les deux situations ci-dessus ont des apparences différentes, mais sont essentiellement les mêmes, toutes deux car il y a plus de bases de données à exploiter !
3. Caractéristiques ACID des transactions
3.1. Atomicité (A)
La soi-disant atomicité signifie que toutes les opérations de la transaction entière sont soit terminées, soit ne font rien. , il n’y a pas d’entre-deux. Si une erreur se produit lors de l'exécution de la transaction, toutes les opérations seront annulées et la transaction entière sera comme si elle n'avait jamais été exécutée.
3.2. Cohérence (C)
L'exécution des transactions doit assurer la cohérence du système. Prenons l'exemple du transfert A 500 yuans. yuans, si A transfère avec succès 50 yuans à B dans une transaction, alors quel que soit le nombre de simultanéités, quoi qu'il arrive, tant que la transaction est exécutée avec succès, alors dans le compte final A doit être de 450 yuans, et le compte B doit être de 350 yuans.
3.3. Isolement (I)
Ce que l'on appelle l'isolement signifie que les transactions ne s'affecteront pas et que l'état intermédiaire d'une transaction ne sera pas une autre transaction. conscience.
3.4. Durabilité (D)
La soi-disant persistance signifie qu'une fois qu'une seule transaction est terminée, les modifications apportées aux données par la transaction seront complètement enregistré dans la base de données, même en cas de panne de courant ou si le système est en panne.
4. Scénarios d'application des transactions distribuées
4.1. Paiement
Le scénario le plus classique est le paiement. compte personnel et ajouter de l'argent sur le compte du vendeur en même temps, ces opérations doivent être effectuées en une seule transaction, soit toutes réussissent, soit toutes échouent. Quant au compte de l'acheteur, qui appartient au centre acheteur, il correspond à la base de données de l'acheteur, tandis que le compte du vendeur appartient au centre du vendeur, qui correspond à la base de données du vendeur. Les opérations sur différentes bases de données doivent introduire des transactions distribuées.
4.2. Commande en ligne
Les acheteurs qui passent des commandes sur les plateformes de commerce électronique impliquent souvent deux actions, l'une consiste à déduire le stock et la seconde à mettre à jour le statut de la commande, les stocks et les commandes appartiennent généralement à des bases de données différentes, et des transactions distribuées doivent être utilisées pour garantir la cohérence des données.
5. Solutions de transactions distribuées courantes
5.1. Soumission en deux phases basée sur le protocole XA
XA est un protocole de transaction distribué proposé par Tuxedo. XA est grossièrement divisé en deux parties : le gestionnaire de transactions et le gestionnaire de ressources locales. Le gestionnaire de ressources local est souvent implémenté par une base de données. Les bases de données commerciales telles qu'Oracle et DB2 implémentent toutes l'interface XA, et le gestionnaire de transactions sert de planificateur global et est responsable de la soumission et de la restauration de chaque ressource locale. Le principe de XA implémentant des transactions distribuées est le suivant :
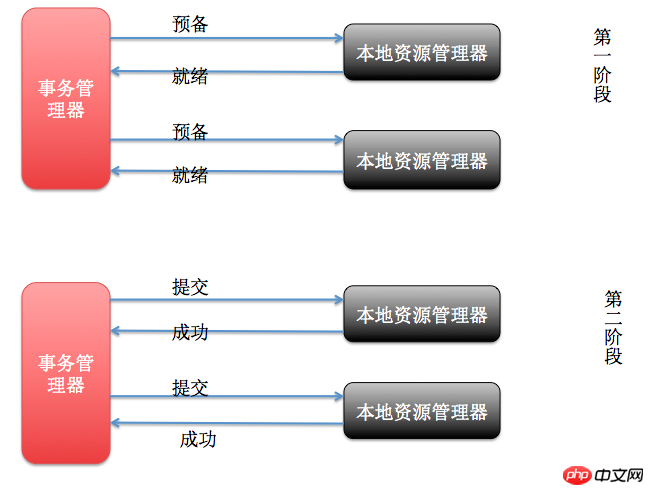
En général, le protocole XA est relativement simple, et une fois qu'une base de données commerciale implémente le XA protocole, utilisation Le coût des transactions distribuées est également relativement faible. Cependant, XA présente également un inconvénient fatal, c'est-à-dire que ses performances ne sont pas idéales, en particulier dans le lien d'ordre de transaction, qui a souvent une grande concurrence, et XA ne peut pas répondre à des scénarios de concurrence élevée. XA est actuellement idéalement pris en charge dans les bases de données commerciales, mais est loin d'être idéalement pris en charge dans les bases de données MySQL. L'implémentation XA de MySQL n'enregistre pas les journaux de phase de préparation, et le basculement entre les bases de données principale et secondaire entraîne une incohérence des données entre la base de données principale et la base de données secondaire. . De nombreux nosql ne prennent pas non plus en charge XA, ce qui rend les scénarios d'application de XA très restreints.
5.2. Transaction de message + cohérence éventuelle
La soi-disant transaction de message est une soumission en deux phases basée sur un middleware de message, qui est essentiellement une sorte de middleware de message . Utilisation spéciale, il place les transactions locales et l'envoi de messages dans une transaction distribuée, garantissant que soit l'opération locale réussit et que le message externe est envoyé avec succès, soit que les deux échouent. Le principe spécifique est le suivant :
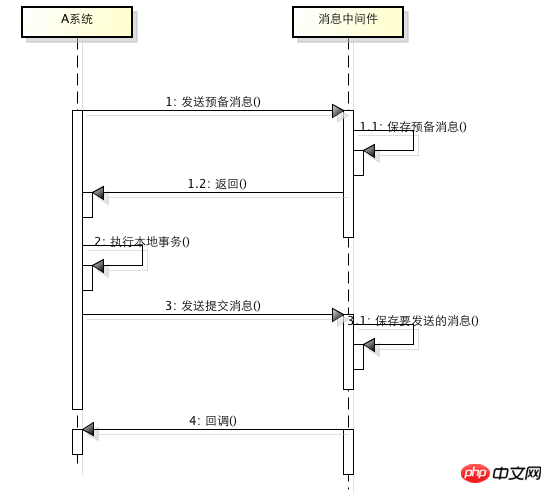
1. Le système A envoie un message préparé au middleware de message
2. Le middleware de message enregistre le message préparé et renvoie le succès3. A exécute une transaction locale
4. A envoie un message de validation au middleware de message
Une transaction de message est terminée via les 4 étapes ci-dessus. Pour les 4 étapes ci-dessus, chaque étape peut provoquer des erreurs. Analysons-les une par une :
Si une erreur se produit à la première étape, la transaction entière échouera. et ne sera pas exécuté. L'opération locale de A
Si une erreur se produit à la deuxième étape, la transaction entière échouera et l'opération locale de A .
ne sera pas exécuté Une erreur s'est produite à l'étape trois. À ce stade, le message de préparation doit être annulé. Comment revenir en arrière ? La réponse est que le système A implémente une interface de rappel pour le middleware de message. Le middleware de message exécutera en permanence l'interface de rappel pour vérifier si la transaction A est exécutée avec succès. En cas d'échec, le message préparé sera annulé .
Une erreur s'est produite à l'étape 4. À ce moment-là, la transaction locale de A a réussi. Le middleware de messages doit-il annuler A ? La réponse est non. En fait, grâce à l'interface de rappel, le middleware de message peut vérifier que A s'est exécuté avec succès. À ce stade, A n'a en fait pas besoin d'envoyer un message de soumission. Le middleware de message peut soumettre le message lui-même. , complétant ainsi l'intégralité de la transaction de message
La validation en deux phases basée sur un middleware de message est souvent utilisée dans des scénarios à forte concurrence pour diviser une transaction distribuée en une transaction de message (fonctionnement local du système A + envoi de messages) + fonctionnement local du système B. Le fonctionnement du système B est piloté par les messages. Tant que la transaction du message réussit, l'opération de A doit réussir et le message doit être envoyé. À ce moment-là, B recevra le message pour effectuer l'opération locale. Si l'opération locale échoue, le message sera relivré jusqu'à ce que l'opération de B réussisse, réalisant ainsi la transaction distribuée de A et B déguisée. Le principe est le suivant :
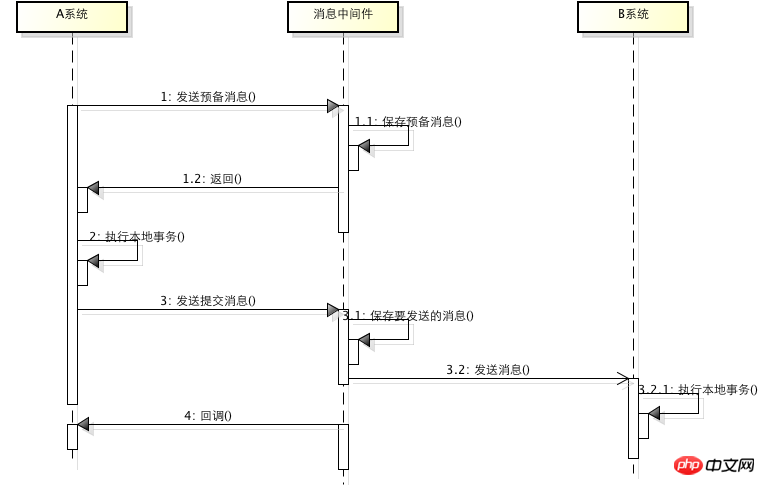
Bien que la solution ci-dessus puisse compléter les opérations de A et B, A et B ne sont pas strictement cohérents, mais finalement cohérent Oui, nous avons sacrifié ici la cohérence en échange d’une amélioration substantielle des performances. Bien sûr, ce type de jeu est également risqué.Si B continue de ne pas s'exécuter, la cohérence sera détruite, cela dépend du niveau de risque que l'entreprise peut supporter.
5.3, mode de programmation TCC
Le mode de programmation dit TCC est également une variante de soumission en deux phases. TCC fournit un cadre de programmation qui divise l'ensemble de la logique métier en trois parties : les opérations Essayer, Confirmer et Annuler. En prenant la commande en ligne comme exemple, l'étape Try déduira l'inventaire et l'étape Confirm mettra à jour le statut de la commande. Si la mise à jour de la commande échoue, elle entrera dans l'étape Cancel et l'inventaire sera restauré. En bref, TCC implémente artificiellement la soumission en deux étapes via le code. Les codes écrits dans différents scénarios commerciaux sont différents et la complexité est également différente. Par conséquent, ce modèle ne peut pas être bien réutilisé.
6. Résumé
Les transactions distribuées sont essentiellement un contrôle unifié des transactions dans plusieurs bases de données. Selon l'intensité du contrôle, elles peuvent être divisées en : aucun contrôle et partiel. contrôle et contrôle complet. Aucun contrôle signifie ne pas introduire de transactions distribuées. Un contrôle partiel signifie une validation en deux phases de diverses variantes, y compris la transaction de message + cohérence éventuelle et le mode TCC mentionné ci-dessus. L'avantage du contrôle partiel est que la concurrence et les performances sont très bonnes. L'inconvénient est que le contrôle total sacrifie les performances et garantit la cohérence. La méthode à utiliser dépend en fin de compte du scénario commercial. En tant que technicien, vous ne devez pas oublier que la technologie est au service de l'entreprise. N'utilisez pas la technologie pour le plaisir de la technologie. La sélection de technologies pour différentes entreprises est également une capacité très importante !
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!