
Maison >développement back-end >Tutoriel Python >Comment résoudre le problème 403 dans les robots d'exploration
Comment résoudre le problème 403 dans les robots d'exploration

- 零到壹度original
- 2018-04-03 11:25:247361parcourir
Lors de l'écriture d'un robot en Python, html.getcode() rencontrera le problème de l'accès 403 interdit, qui est une interdiction des robots automatisés sur le site Web. Cet article présente principalement comment résoudre le problème 403 des robots d'exploration dans Angular2 Advanced. L'éditeur pense que c'est plutôt bon, je vais donc le partager avec vous maintenant et le donner comme référence. Suivons l'éditeur pour y jeter un œil
Pour résoudre ce problème, vous devez utiliser le module python urllib2 module
urllib2 module Il s'agit d'un module avancé d'exploration de robots. Il existe de nombreuses méthodes
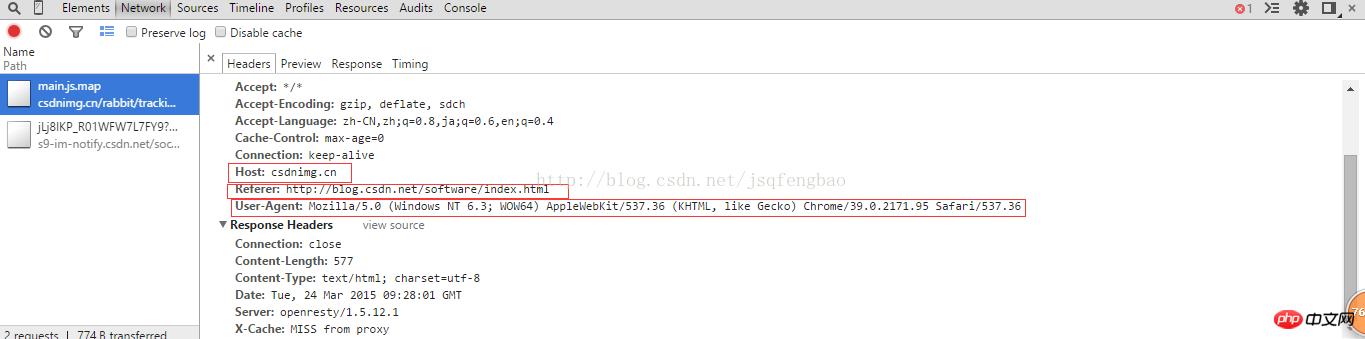
Par exemple, connect url=http://blog.csdn.net/qysh123
Il peut y avoir un problème d'accès interdit 403 pour cette connexion
Pour résoudre ce problème, les étapes suivantes sont requises :
<span style="font-size:18px;">req = urllib2.Request(url)
req.add_header("User-Agent","Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36")
req.add_header("GET",url)
req.add_header("Host","blog.csdn.net")
req.add_header("Referer","http://blog.csdn.net/")</span>User-Agent est un attribut spécifique au navigateur. Vous pouvez afficher le code source via le navigateur pour voir
puis html=urllib2. .urlopen(req)
print html.read()
peut télécharger tout le code de la page Web sans problème d'accès 403 interdit.
Pour les problèmes ci-dessus, il peut être encapsulé dans une fonction pour une utilisation facile à l'avenir. Le code spécifique :
- .
#-*-coding:utf-8-*- import urllib2 import random url="http://blog.csdn.net/qysh123/article/details/44564943" my_headers=["Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.153 Safari/537.36", "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:30.0) Gecko/20100101 Firefox/30.0" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.75.14 (KHTML, like Gecko) Version/7.0.3 Safari/537.75.14", "Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2; Win64; x64; Trident/6.0)" ] def get_content(url,headers): ''''' @获取403禁止访问的网页 ''' randdom_header=random.choice(headers) req=urllib2.Request(url) req.add_header("User-Agent",randdom_header) req.add_header("Host","blog.csdn.net") req.add_header("Referer","http://blog.csdn.net/") req.add_header("GET",url) content=urllib2.urlopen(req).read() return content print get_content(url,my_headers)
La fonction aléatoire est utilisée pour obtenir automatiquement les informations User-Agent du type de navigateur qui ont été écrites. Dans la fonction personnalisée, vous devez écrire votre. propre hôte, référent, GET Information, etc., après avoir résolu ces problèmes, vous pouvez accéder en douceur et les informations d'accès 403 n'apparaîtront plus.
Bien sûr, si la fréquence d'accès est trop rapide, certains sites Web seront quand même filtrés. Pour résoudre ce problème, vous devez utiliser une méthode IP proxy. . . Résolvez-le spécifiquement par vous-même
Recommandations associées :
Le robot d'exploration Python résout l'erreur d'accès interdit 403
Erreur HTTP Python3 403 : Interdit
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!