
Maison >développement back-end >Tutoriel Python >Exemple de partage de robot d'exploration dynamique Python
Exemple de partage de robot d'exploration dynamique Python

- 小云云original
- 2018-03-30 16:41:113966parcourir
Cet article partage principalement avec vous des exemples de robots d'exploration dynamiques Python. Lorsque vous utilisez Python pour explorer des pages Web statiques conventionnelles, urllib2 est souvent utilisé pour obtenir la page HTML entière, puis les mots-clés correspondants sont recherchés mot pour mot à partir du fichier HTML. . Comme indiqué ci-dessous :
#encoding=utf-8
import urllib2 url="http://mm.taobao.com/json/request_top_list.htm?type=0&page=1"up=urllib2.urlopen(url)#打开目标页面,存入变量upcont=up.read()#从up中读入该HTML文件key1='<a href="http'#设置关键字1key2="target"#设置关键字2pa=cont.find(key1)#找出关键字1的位置pt=cont.find(key2,pa)#找出关键字2的位置(从字1后面开始查找)urlx=cont[pa:pt]#得到关键字1与关键字2之间的内容(即想要的数据)print urlx
Cependant, dans les pages dynamiques, le contenu affiché n'est souvent pas présenté via des pages HTML, mais les données sont obtenues à partir de la base de données en appelant js et d'autres méthodes, et sont répercutées à la page Web.
Prenons comme exemple les « Informations d'enregistrement » (http://beian.hndrc.gov.cn/) sur le site Web de la Commission nationale du développement et de la réforme. Nous souhaitons capturer certains des éléments de dépôt sur cette page. . Par exemple « http://beian.hndrc.gov.cn/indexinvestment.jsp?id=162518 ».
Ensuite, ouvrez cette page dans le navigateur :
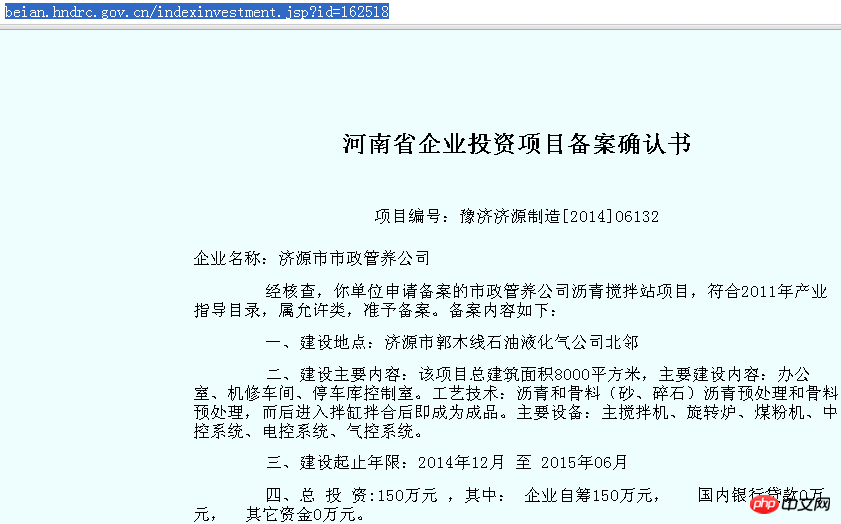
Les informations pertinentes sont entièrement affichées, mais si vous suivez la méthode précédente :
up=urllib2.urlopen(url) cont=up.read()
ne peut pas capturer le contenu ci-dessus.
Vérifions le code source correspondant de cette page :

Comme le montre le code source, cette "Lettre de confirmation de dépôt" est sous la forme de "remplir les blancs", HTML Un modèle de texte est fourni, et js fournit différentes variables en fonction de différents identifiants, qui sont "remplies" dans le modèle de texte pour former une "Lettre de confirmation de dépôt" spécifique. Ainsi, le simple fait de saisir ce code HTML ne peut obtenir que certains modèles de texte, mais pas le contenu spécifique.
Alors, comment trouver ces contenus spécifiques ? Vous pouvez utiliser les « Outils de développement » de Chrome pour découvrir qui est le véritable fournisseur de contenu.
Ouvrez le navigateur Chrome et appuyez sur F12 sur le clavier pour appeler cet outil. Comme indiqué ci-dessous :
À ce moment, sélectionnez le label « Réseau » et entrez dans cette page « http://beian.hndrc.gov.cn/indexinvestment.jsp? " dans la barre d'adresse. id=162518", le navigateur analysera l'ensemble du processus de cette réponse, et les fichiers dans la case rouge sont toutes les communications entre le navigateur et le backend Web dans cette réponse.
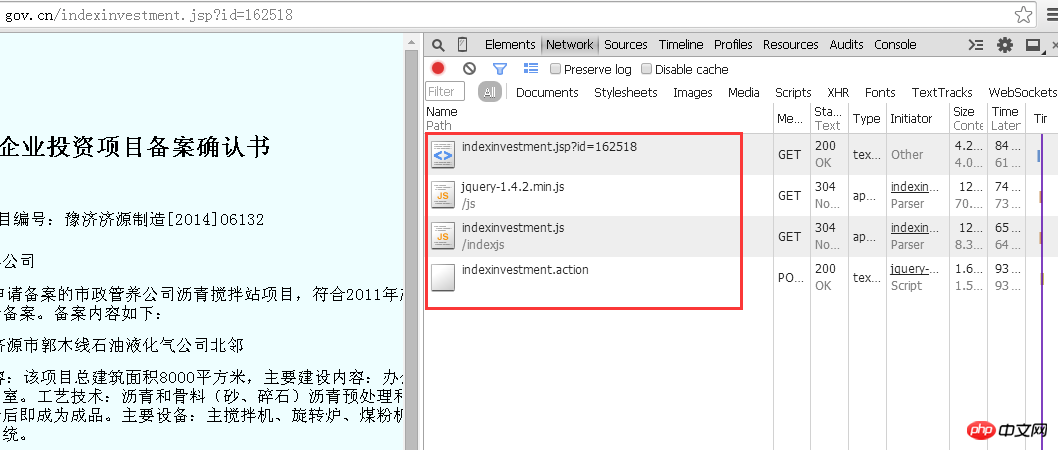
Parce que vous souhaitez obtenir différentes informations correspondant à différentes entreprises, la requête envoyée par le navigateur au serveur doit avoir un paramètre lié à l'identifiant actuel de l'entreprise.
Alors, quels sont les paramètres ? Il y a "jsp?id=162518" sur l'URL. Le point d'interrogation indique que les paramètres doivent être appelés, suivi du numéro d'identification qui est le paramètre à appeler. Grâce à l'analyse de ces fichiers, il ressort clairement que des informations corporatives existent dans le fichier « indexinvestment.action ».
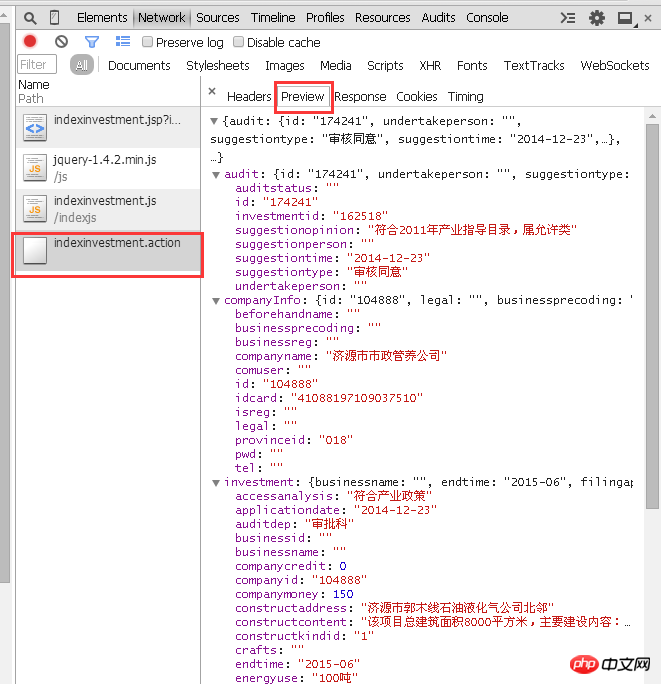
Cependant, double-cliquer pour ouvrir ce fichier n'obtient pas d'informations sur l'entreprise, mais un tas de code. Parce qu'il n'y a pas de paramètre correspondant pour indiquer le nombre d'informations à afficher. Comme le montre l'image :

Alors, comment devez-vous lui transmettre des paramètres ? En ce moment, nous regardons toujours la fenêtre F12 :
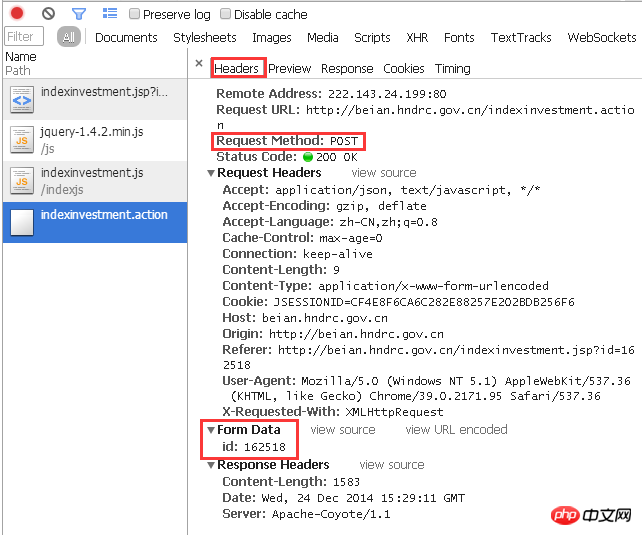
La colonne "En-tête" montre clairement le processus de cette réponse :
Pour l'URL cible , À l'aide de POST, un paramètre avec un ID de 162518 est transmis.
Faisons-le manuellement d’abord. Comment js appelle-t-il les paramètres ? Oui, comme mentionné ci-dessus : point d'interrogation + nom de la variable + signe égal + numéro correspondant à la variable. En d'autres termes, lorsque vous soumettez le paramètre avec l'ID 162518 à la page "http://beian.hndrc.gov.cn/indexinvestment.action", vous devez ajouter
"?id=162518" après l'URL. , à savoir
"http://beian.hndrc.gov.cn/indexinvestment.action?id=162518".
Collons cette URL dans le navigateur pour voir :

Il semble qu'il y ait du contenu, mais tout est tronqué. Comment le casser ? Des amis familiers peuvent voir d'un coup d'œil qu'il s'agit d'un problème d'encodage. C'est parce que le contenu renvoyé dans la réponse est différent de l'encodage par défaut du navigateur. Allez simplement dans le menu dans le coin supérieur droit de Chrome – Plus d’outils – Codage – « Détection automatique ». (En fait, il s'agit d'un encodage UTF-8 et Chrome utilise par défaut le chinois simplifié). Comme indiqué ci-dessous :
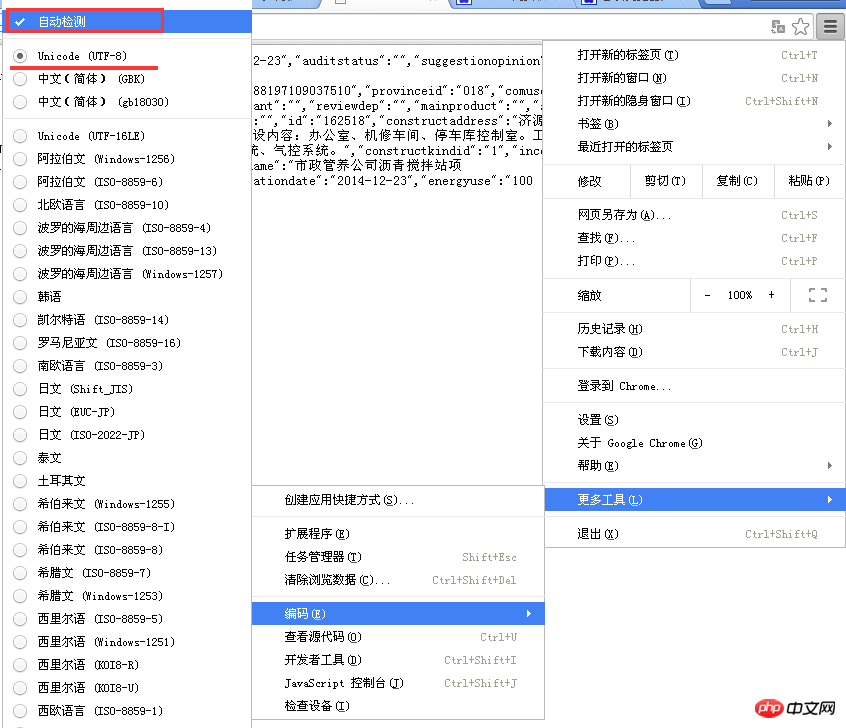
Eh bien, la véritable source d'informations a été déterrée. Il ne reste plus qu'à utiliser Python pour traiter les chaînes de ces pages, puis à les couper et à les épisser. un nouveau « Document de dépôt de projet » a été réorganisé.
Utilisez ensuite les boucles for, while et autres pour obtenir ces "Documents d'enregistrement" par lots.
Tout comme "Qu'il s'agisse d'une page web statique, d'une page web dynamique, d'une connexion simulée, etc., vous devez d'abord analyser et comprendre la logique avant d'écrire le code", le langage de programmation n'est qu'un outil, ce qui est important, c'est l'idée de résoudre le problème. Une fois que vous avez une idée, vous pouvez trouver les outils dont vous avez besoin pour la résoudre, et vous serez prêt à partir.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!