
Maison >développement back-end >tutoriel php >Solution distribuée d'analyse des journaux en temps réel Architecture de déploiement ELK
Solution distribuée d'analyse des journaux en temps réel Architecture de déploiement ELK

- 不言original
- 2018-05-05 15:10:124873parcourir
ELK est devenue la solution de journalisation centralisée la plus populaire à l'heure actuelle. Elle est principalement composée de Beats, Logstash, Elasticsearch, Kibana et d'autres composants pour compléter conjointement la collecte, le stockage, l'affichage et d'autres solutions uniques de journaux en temps réel. . Cet article vous présente principalement l'architecture de déploiement ELK de la solution distribuée d'analyse des journaux en temps réel. Les amis dans le besoin peuvent consulter
Recommandation de cours → : 《 elasticsearch. recherche en texte intégral en pratique" (vidéo de combat réelle)
Extrait du cours "Solution simultanée pour des dizaines de millions de données (théorie + combat pratique)"
1, Présentation
ELK est devenue la solution de journalisation centralisée la plus populaire à l'heure actuelle. Elle est principalement composée de Beats, Logstash, Elasticsearch, Kibana et d'autres composants pour compléter conjointement la collecte, le stockage et l'affichage. de journaux en temps réel dans une solution unique. Cet article présentera l'architecture commune d'ELK et résoudra les problèmes associés.
Filebeat : Filebeat est un moteur de collecte de données léger qui consomme très peu de ressources de service. Il s'agit d'un nouveau membre de la famille ELK et peut remplacer Logstash en tant que collecte de journaux sur le serveur d'applications. Le moteur prend en charge la sortie des données collectées vers des files d'attente telles que Kafka et Redis.
Logstash : moteur de collecte de données, plus lourd que Filebeat, mais il intègre un grand nombre de plug-ins et prend en charge une riche collecte de sources de données. Les données collectées peuvent être filtrées et analysées. . Formater le format du journal.
Elasticsearch : un moteur de recherche de données distribué, implémenté sur la base d'Apache
Lucene, peut être mis en cluster et fournit un stockage et une analyse centralisés des données, ainsi qu'une recherche et une agrégation de données puissantes fonctions.Kibana : une plateforme de visualisation de données. Cette plateforme Web vous permet de visualiser des données pertinentes dans Elasticsearch en temps réel et fournit des statistiques graphiques riches.
2. Architecture de déploiement commune ELK
2.1. Logstash en tant que collecteur de journaux
Cette architecture est une architecture de déploiement relativement primitive. : déployez un composant Logstash sur chaque serveur d'applications en tant que collecteur de journaux, puis filtrez, analysez et formatez les données collectées par Logstash et envoyez-les au stockage Elasticsearch, et enfin utilisez Kibana pour l'affichage visuel. Cette architecture est insuffisante. Le point clé est : Logstash consomme plus de ressources serveur, ce qui augmentera la pression de charge sur le serveur d'applications.
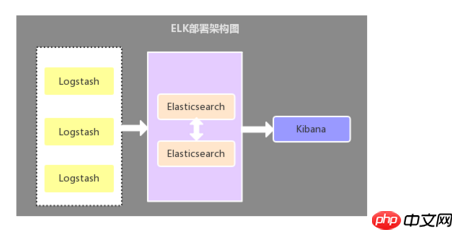
2.2. Filebeat comme collecteur de logs
La seule différence entre cette architecture et la première architecture Oui : le collecteur de journaux côté application est remplacé par Filebeat. Filebeat est léger et consomme moins de ressources du serveur. Filebeat est donc utilisé comme collecteur de journaux côté serveur d'application. Généralement, Filebeat est également utilisé avec Logstash. l'architecture la plus couramment utilisée à l'heure actuelle.
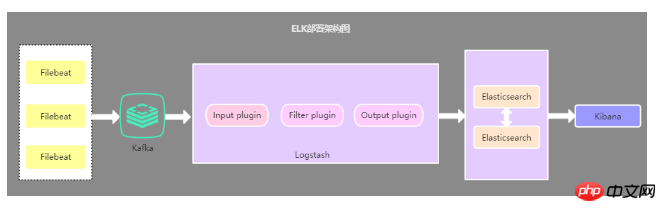
2.3 Architecture de déploiement qui introduit la file d'attente de cache
Cette architecture est basée sur la deuxième architecture La La file d'attente de messages Kafka (peut également être d'autres files d'attente de messages) est introduite, les données collectées par Filebeat sont envoyées à Kafka, puis les données dans Kafka sont lues via Logstasth. Cette architecture est principalement utilisée pour résoudre des solutions de collecte de journaux sous de gros volumes de données. , l'utilisation des files d'attente de cache vise principalement à résoudre la sécurité des données et à équilibrer la pression de charge de Logstash et Elasticsearch.
2.4.Résumé des trois architectures ci - dessus
La première architecture de déploiement présente des problèmes d'occupation des ressources, est désormais rarement utilisée, et la deuxième architecture de déploiement est actuellement la plus utilisée. Quant à la troisième architecture de déploiement, je pense personnellement qu'il n'est pas nécessaire d'introduire une file d'attente de messages, sauf s'il y a d'autres besoins, car dans le cas de gros montants. des données, pression d'utilisation de Filebeat Les protocoles sensibles envoient des données à Logstash ou Elasticsearch. Si Logstash est occupé à traiter des données, il demande à Filebeat de ralentir ses lectures. Une fois la congestion résolue, Filebeat reprendra sa vitesse d'origine et continuera à envoyer des données.
Recommander un groupe de communication et d'apprentissage : 478030634 qui partagera quelques vidéos enregistrées par des architectes senior : Spring, MyBatis, analyse du code source Netty, principes de haute concurrence, hautes performances, architecture distribuée et microservices, optimisation des performances JVM a devenir un système de connaissances nécessaire pour les architectes. Vous pouvez également recevoir des ressources d'apprentissage gratuites et en bénéficier jusqu'à présent :

Problèmes et solutions
Problème. : Comment implémenter la fonction de fusion multi-lignes des logs ?
Les journaux dans les applications système sont généralement imprimés dans un format spécifique. Par conséquent, lorsque vous utilisez ELK pour collecter des journaux, vous devez séparer plusieurs lignes de données appartenant au même journal. . Fusionner.
Solution : utilisez le plug-in de fusion multiligne multiligne dans Filebeat ou Logstash pour obtenir
Lorsque vous utilisez le plug-in de fusion multiligne multiligne, vous devez faire attention aux différents déploiements ELK L'architecture peut également utiliser le multiligne de différentes manières. S'il s'agit de la première architecture de déploiement dans cet article, alors le multiligne doit être configuré et utilisé dans Logstash. S'il s'agit de la deuxième architecture de déploiement, alors le multiligne doit être configuré. à configurer et à utiliser dans Filebeat, et il n'est pas nécessaire de le configurer dans Logstash Configure multiline.
1. Comment configurer le multiligne dans Filebeat :
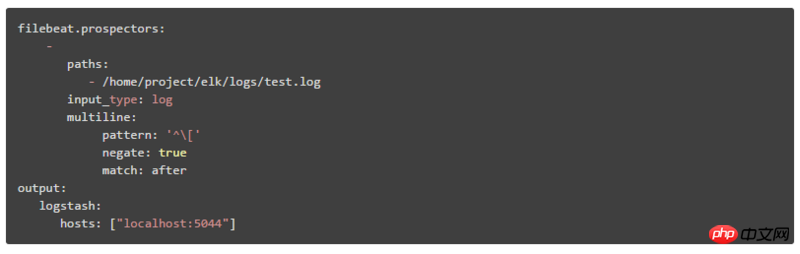
modèle : Expression régulière
negate : La valeur par défaut est false, ce qui signifie que les lignes correspondant au motif sont fusionnées dans la ligne précédente ; true signifie que les lignes qui ne correspondent pas au motif sont fusionnées dans la ligne précédente
match : après signifie fusionner vers la fin de la ligne précédente, avant signifie fusionner vers le début de la ligne précédente
Par exemple :
modèle : '['
négation : vrai
match : après
Cette configuration consiste à fusionner les lignes qui ne correspondent pas au motif à la fin de la ligne précédente
2. Multiligne dans la méthode de configuration de Logstash

(1) La valeur de l'attribut quoi configuré dans Logstash est précédente, ce qui est équivalent à after dans Filebeat. La valeur de l'attribut what configuré dans Logstash est équivalente à before dans Filebeat.
(2) pattern => "%{LOGLEVEL}s*]" Le LOGLEVEL dans "%{LOGLEVEL}s*]" est le modèle de correspondance régulier prédéfini de Logstash. Il existe de nombreux modèles de correspondance réguliers prédéfinis pour. Pour plus de détails, veuillez consulter : https://github .com/logstash-p…
Question : Comment remplacer le champ d'heure du journal affiché dans Kibana par l'heure dans les informations du journal ?
Par défaut, le champ d'heure que nous visualisons dans Kibana n'est pas cohérent avec l'heure dans les informations du journal, car la valeur du champ d'heure par défaut est l'heure actuelle à laquelle le journal est collecté, l'heure de ce champ. doit être modifié. Remplacez-le par l'heure indiquée dans le message du journal.
Solution : utilisez le plug-in de segmentation de mots grok et le plug-in de formatage de date et d'heure pour obtenir
Configurez le plug-in de segmentation de mots grok et le format de date et d'heure dans le filtre du plug-in de configuration du fichier de configuration Logstash, tel que :

Si le format de journal à faire correspondre est : "DEBUG[DefaultBeanDefinitionDocumentReader : 106] Chargement des définitions de bean", analyser le journal. Les méthodes du champ temporel sont :
① En introduisant un fichier d'expression écrit, par exemple, le fichier d'expression est customer_patterns et le contenu est :
CUSTOMER_TIME % {YEAR}%{MONTHNUM}%{MONTHDAY}s+ %{TIME}
Remarque : Le format du contenu est : [nom de l'expression personnalisée] [expression régulière]
Il peut ensuite être cité comme ceci dans logstash :

② Sous forme d'éléments de configuration, la règle est : (?

Question : Comment afficher les données dans Kibana en sélectionnant différents modules de journal système
Généralement, les données de journal affichées dans Kibana mélange les données de différents modules système, alors comment sélectionner ou filtrer pour afficher uniquement les données de journal du module système spécifié ?
Solution : ajoutez des champs qui identifient différents modules système ou créez des index ES basés sur différents modules système
1. Ajoutez des champs qui identifient différents modules système, puis Kibana peut le faire. filtrer et interroger les données de différents modules en fonction de ce champ
Nous expliquerons ici la deuxième architecture de déploiement. Le contenu de la configuration dans Filebeat est :
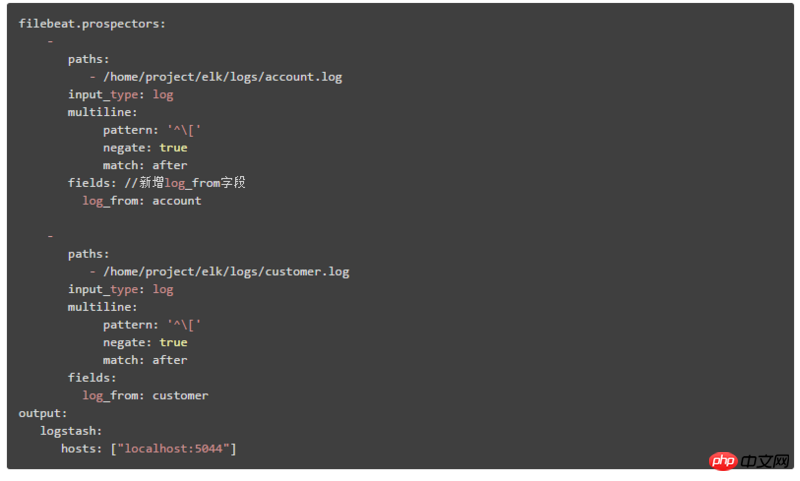
Identifier les différents. journaux du module système en ajoutant : champ log_from
2. Configurez l'index ES correspondant en fonction des différents modules système, puis créez le modèle d'index correspondant correspondant dans Kibana, et vous pouvez transmettre l'index sur la page Mode drop- la case vers le bas sélectionne différentes données du module système.
La deuxième architecture de déploiement est expliquée ici, qui est divisée en deux étapes :
① Le contenu de la configuration dans Filebeat est :
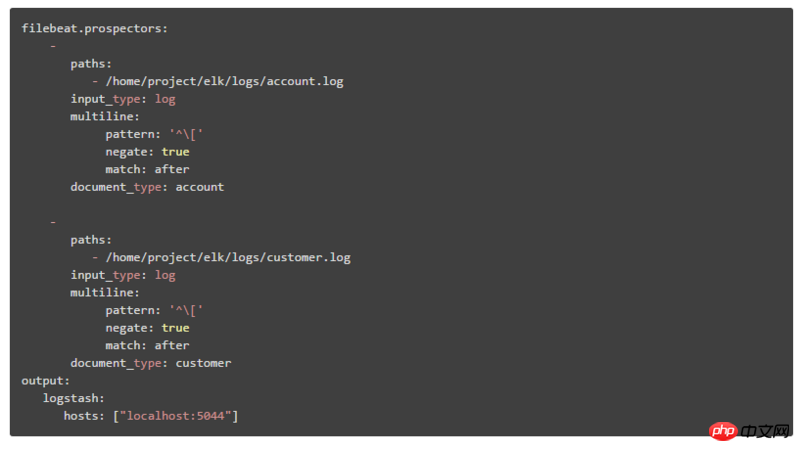
via document_type Identifier différents modules système
② Modifiez le contenu de la configuration de sortie dans Logstash comme suit :
Ajoutez l'attribut index à la sortie, %{type} signifie construire l'index ES en fonction de différentes valeurs de document_type
4. Résumé
Cet article présente principalement les trois architectures de déploiement de l'analyse des journaux en temps réel ELK, ainsi que les problèmes que différentes architectures peuvent résoudre. Parmi ces trois architectures, la deuxième méthode de déploiement est la. La méthode de déploiement la plus populaire et la plus couramment utilisée, et présente enfin certains problèmes et solutions d'ELK dans l'analyse des journaux. En fin de compte, ELK peut non seulement être utilisé pour une requête et une gestion centralisées des données de journaux distribuées, mais peut également être utilisé comme outil. application de projet. Ainsi que la surveillance des ressources du serveur et d’autres scénarios.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Tous les symboles d'expression dans les expressions régulières (résumé)