
Maison >interface Web >js tutoriel >Analyser les principes et la syntaxe de l'expression régulière JS
Analyser les principes et la syntaxe de l'expression régulière JS
- php中世界最好的语言original
- 2018-03-29 16:17:431824parcourir
Cette fois, je vais vous apporter les principes et la syntaxe de l'analyse des regex JS. Quelles sont les précautions pour analyser les principes et la syntaxe des regex JS. Voici des cas pratiques, jetons un coup d'œil.
Zhengze est comme un phare. Quand vous êtes perdu dans la mer de ficelles, cela peut toujours vous donner des idées ; Zhengze est comme un détecteur de billets de banque. Quand vous ne connaissez pas l'utilisateur Quand. les billets que vous soumettez sont authentiques ou faux, cela peut toujours vous aider à les identifier d'un coup d'oeil ; la régularité est comme une lampe de poche, quand vous avez besoin de trouver quelque chose, cela peut toujours vous aider à obtenir ce que vous voulez...
——Extrait de l'exercice de phrases parallèles chinoises de Stinson "Regular"
Après avoir apprécié un extrait littéraire, nous allons trier formellement les règles régulières en JS. Le but principal de cet article est de m'éviter d'oublier certains réguliers. Règles d'utilisation, je l'ai donc trié et noté pour améliorer mes compétences et l'utiliser comme référence. Le but principal est de partager avec vous. S'il y a des erreurs, n'hésitez pas à m'éclairer. .
Puisque cet article s'intitule "One Dragon", il doit être digne du "dragon", il inclura donc les principes de régularité, un aperçu de la syntaxe, la régularité en JS (ES5), l'expansion de la régularité ES6 et des idées pour pratiquer la régularité, j'essaie d'expliquer ces choses aussi profondément que possible et de manière simple (comme si je pouvais vraiment les expliquer de manière simple. Si vous voulez juste savoir comment l'appliquer, alors lisez le deuxième, le troisième). et la cinquième partie, qui répondra essentiellement à vos besoins. Si vous voulez maîtriser les règles habituelles de JS, alors vous feriez mieux de suivre mes idées, hé hé !
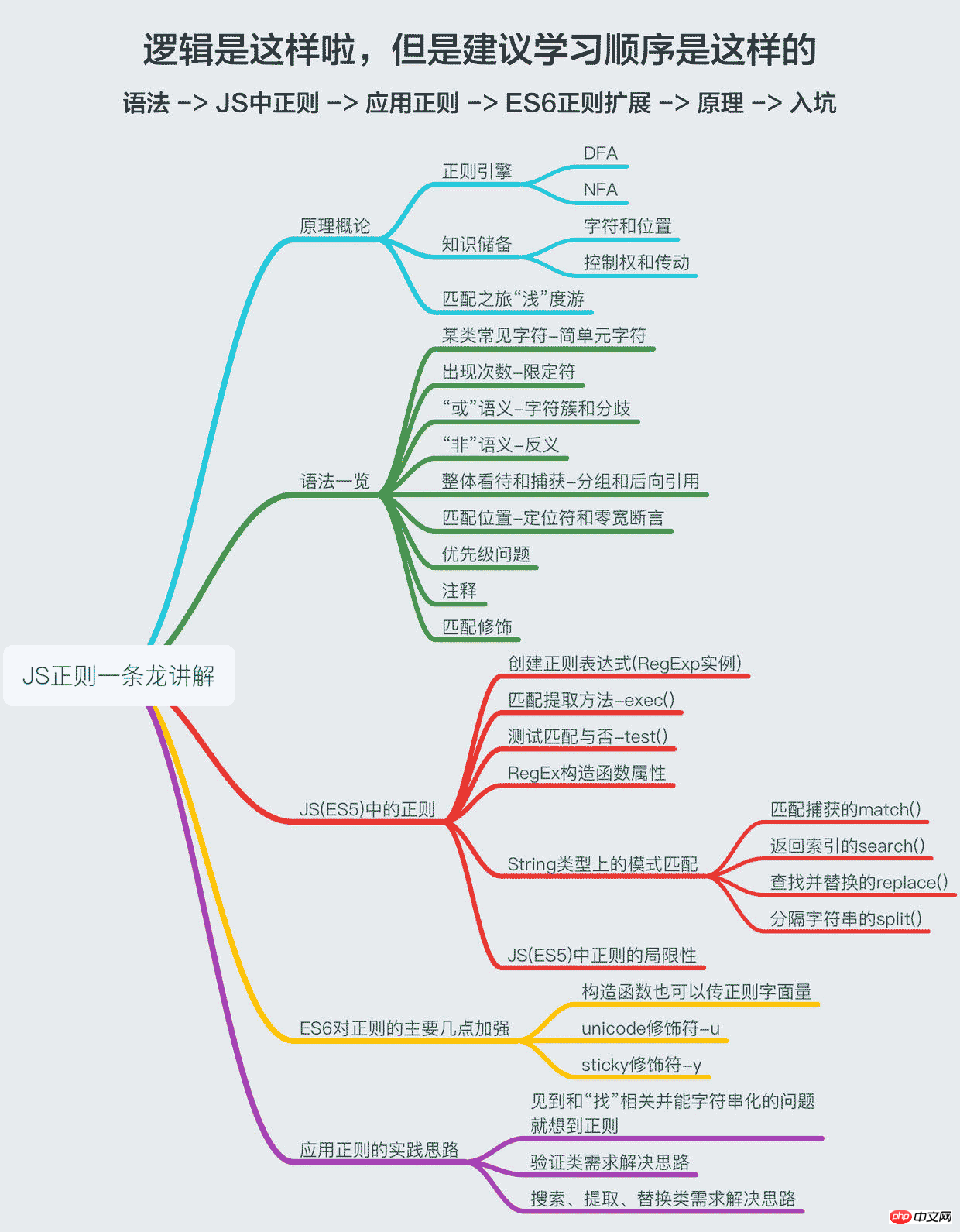
1. Introduction aux principes
Quand j'ai commencé à utiliser les expressions régulières, j'ai trouvé incroyable la façon dont l'ordinateur pouvait utiliser une Expression régulière pour faire correspondre les chaînes ? Ce n'est que plus tard que j'ai découvert un livre intitulé "Computational Theory" et que j'ai vu les concepts et les liens entre la régularité, DFA et NFA, et j'ai soudainement eu une certaine illumination.
Mais si vous voulez vraiment comprendre les expressions régulières en principe, alors j'ai bien peur que la meilleure façon soit :
1 Tout d'abord, trouvez un livre spécifiquement sur les expressions régulières, celui d'O'REILLY. la série "Animal Story"
2. Ensuite, implémentez vous-même un moteur standard.
Cet article se concentre sur l'application des expressions régulières en JS, le principe n'est donc que brièvement présenté (car je n'ai jamais écrit de moteur régulier, et je n'entrerai pas dans les détails), pour grossièrement " "idiot" des gens curieux comme moi. Pour les bébés qui ont des doutes sur les principes de régularité, deuxièmement, connaître quelques connaissances de base des principes est très utile pour comprendre la grammaire et la régularité de l'écriture.
1. Moteur de régularité
La raison pour laquelle la régularité peut être efficace est qu'il existe un moteur. C'est la même chose que la raison pour laquelle JS peut être exécuté. -appelé moteur de régularité peut être compris comme Utiliser un algorithme pour simuler une machine basée sur votre expression régulière. Cette machine a de nombreux états en lisant la chaîne à tester, elle saute entre ces états. "état terminal" (Happy Ending), puis dites oui, sinon dites que vous êtes un homme bon. En convertissant une expression régulière en une machine capable de calculer le résultat en un nombre limité d'étapes, un moteur est implémenté.
Les moteurs réguliers peuvent être grossièrement divisés en deux catégories : DFA et NFA
1. DFA (Automate fini déterministe) Automate fini déterministe
2. automate) Automate fini non déterministe, dont la plupart sont NFA
Le "déterministe" signifie ici que pour la saisie d'un certain caractère, l'état de cette machine passera définitivement de a Jumping à b, "non -déterministe" signifie que pour la saisie d'un certain caractère, la machine peut avoir plusieurs états de saut ; "fini" signifie ici que l'état est limité et peut être sauté en un nombre limité d'étapes. Déterminer si une certaine chaîne est acceptée ou émis une bonne carte en quelques secondes ; la « machine automatique » peut ici être comprise comme une fois les règles de cette machine fixées, vous pouvez vous faire votre propre jugement sans que personne ne le regarde.
Le moteur DFA ne nécessite pas de retour en arrière, donc l'efficacité de la correspondance est généralement élevée. Cependant, il ne prend pas en charge les groupes de capture, il ne prend donc pas en charge les références inversées et les références $, ni les recherches. (Lookaround), mode non gourmand et autres fonctionnalités uniques du moteur NFA.
Si vous souhaitez en savoir plus sur les expressions régulières, DFA et NFA, vous pouvez lire « Computational Theory » et ensuite dessiner un automate basé sur une certaine expression régulière.
2. Réserve de connaissances
Cette section est très utile pour vous permettre de comprendre les expressions régulières, notamment ce qu'est un caractère et ce qu'est une position.
2.1 Chaîne aux yeux de l'expression régulière - n caractères, n+1 positions

Dans la chaîne « rire » ci-dessus, il y a 8 caractères au total, qui sont ce que vous pouvez voir, et 9 positions, que seules les personnes intelligentes peuvent voir. Pourquoi avons-nous besoin de personnages et de positions ? Parce que l'emplacement peut être assorti.
Ensuite, allons plus loin pour comprendre les « caractères occupés » et la « largeur nulle » :
Si une expression sous-régulière correspond à des caractères, pas à des positions, et sera enregistrée dans le résultat final. La sous-expression occupe des caractères. Par exemple, /ha/ (correspond à ha) occupe des caractères
Si une correspondance sous-régulière est une position, pas un caractère, ou la correspondance ; le contenu n'est pas enregistré dans le résultat (en fait, il peut également être considéré comme une position), alors cette sous-expression a une largeur nulle, comme /read(?=ing)/ (correspond à la lecture, mais met uniquement read dans le résultat . La syntaxe sera décrite en détail ci-dessous. Ceci n'est qu'un exemple.), où (?=ing) est de largeur nulle et représente essentiellement une position.
Les caractères possédant des caractères s'excluent mutuellement, la largeur nulle n'est pas mutuellement exclusive. Autrement dit, un caractère ne peut correspondre qu'à une seule sous-expression à la fois, mais une position peut correspondre à plusieurs sous-expressions de largeur nulle en même temps. Par exemple, /aa/ ne peut pas correspondre à a. Le a dans cette chaîne ne peut être mis en correspondance que par le premier caractère a de l'expression régulière, et ne peut pas être mis en correspondance par le second a en même temps (non-sens mais il peut y en avoir plusieurs) ; Par exemple, /bba/ peut correspondre à a. Bien qu'il y ait deux métacaractères b dans l'expression régulière qui représentent le début du mot, ces deux b peuvent correspondre à la position 0 (dans cet exemple) en même temps.
Remarque : Nous parlons de caractères et de positions pour les chaînes, tandis que parler de caractères occupés et de largeur nulle concerne les expressions régulières.
2.2 Contrôle et transmission
Ces deux mots peuvent être rencontrés lors de la recherche de certains articles de blog ou d'informations Voici une explication :
Contrôle <.> fait référence à la sous-expression régulière (qui peut être composée d'un caractère ordinaire, d'un métacaractère ou d'une séquence de métacaractères) correspondant à la chaîne, puis à l'endroit où se trouve le contrôle.
Transmission fait référence à un mécanisme du moteur régulier. Le dispositif de transmission localisera l'endroit où dans la chaîne commence la correspondance régulière.
Lorsqu'une expression régulière commence à correspondre, elle prend généralement le contrôle d'une sous-expression et commence à essayer de correspondre à partir d'une certaine position dans la chaîne. La position où une sous-expression commence à essayer de correspondre est la sous-expression précédente. commence à la position finale d'un match réussi. À titre d'exemple, read(?=ing)ingsbook correspond à reading book Nous considérons cette expression régulière comme cinq sous-expressions : read, (?=ing), ing, s et book Bien sûr, vous. can trop read est traité comme une sous-expression de quatre caractères distincts, mais nous le traitons ici de cette façon pour des raisons de commodité. read commence à partir de la position 0 et correspond à la position 4. Le (?=ing) suivant continue de correspondre à partir de la position 4. On constate que la position 4 est effectivement suivie de ing, on affirme donc que la correspondance est réussie, c'est-à-dire que le entier (?=ing) correspond à la position. 4 est juste une position (vous pouvez mieux comprendre ce qu'est la largeur nulle ici), puis le ing suivant correspond à la position 4 à la position 7, puis s correspond à la position 7 à la position 8. , et les correspondances finales du livre à partir de la position 8. À la position 12, la correspondance entière est terminée.3. Voyage de correspondance « peu profond » (peut être ignoré) Cela dit, nous nous considérons comme un moteur régulier, étape par étape dans la plus petite unité - - " Caractère" et "position" - Jetons un coup d'œil au processus de correspondance régulière et donnons quelques exemples.
Expression régulière : facile
Chaîne source : Si facile
Processus de correspondance : Tout d'abord, le caractère de l'expression régulière e prend le contrôle, à partir de la position 0 de la chaîne Correspondance, lorsque le caractère de chaîne « S » est rencontré, la correspondance échoue, puis le moteur normal avance, à partir de la position 1. Lorsque le caractère de chaîne « o » est rencontré, la correspondance échoue et la transmission continue naturellement aussi. échoue, alors essayez de faire correspondre à partir de la position 3, faites correspondre avec succès le caractère de chaîne 'e', le contrôle est donné à la sous-expression de l'expression régulière (voici aussi un caractère) a, essayez de faire correspondre à partir de la position finale 4 du dernier correspondance réussie, correspondance réussie du caractère Le caractère de chaîne « a » correspond jusqu'à « y », puis la correspondance est terminée et le résultat de la correspondance est facile.
正则:^(?=[aeiou])[a-z]+$ 源字符串:appleTout d'abord, cette expression régulière : correspond à une chaîne aussi complète du début à la fin. Cette chaîne entière est composée uniquement de lettres minuscules et commence par. a, Cela commence par l'une des cinq lettres e, i, o, u.
匹配过程:首先正则的^(表示字符串开始的位置)获取控制权,从位置0开始匹配,匹配成功,控制权交给(?=[aeiou]),这个子表达式要求该位置右边必须是元音小写字母中的一个,零宽子表达式相互间不互斥,所以从位置0开始尝试匹配,右侧是字符串的‘a',符合因此匹配成功,所以(?=[aeiou])匹配此处的位置0匹配成功,控制权交给[a-z]+,从位置0开始匹配,字符串‘apple'中的每个字符都匹配成功,匹配到字符串末尾,控制权交回正则的$,尝试匹配字符串结束位置,成功,至此,整个匹配完成。
3.3 贪婪匹配和非贪婪匹配
正则1:{.*}
正则2:{.*?}
源字符串:{233}
这里有两个正则,在限定符(语法会讲什么是限定符)后面加?符号表示忽略优先量词,也就是非贪婪匹配,这个栗子我剥得快一点。
首先开头的{匹配,两个正则都是一样的表现。
正则1的.*为贪婪匹配,所以一直匹配余下字符串'233}',匹配到字符串结束位置,只是每次匹配,都记录一个备选状态,为了以后回溯,每次匹配有两条路,选择了匹配这条路,但记一下这里还可以有不匹配这条路,如果前面死胡同了,可以退回来,此时控制权交还给正则的},去匹配字符串结束位置,失败,于是回溯,意思就是说前面的.*你吃的太多了,吐一个出来,于是控制权回给.*,吐出一个}(其实是用了前面记录的备选状态,尝试不用.*去匹配'}'),控制权再给正则的},这次匹配就成功了。
正则2的.*?为非贪婪匹配,尽可能少地匹配,所以匹配'233}'的每一个字符的时候,都是尝试不匹配,但是一但控制权交还给最后的}就发现出问题了,赶紧回溯乖乖匹配,于是每一个字符都如此,最终匹配成功。
云里雾里?这就对了!可以移步去下面推荐的博客看看:
想详细了解贪婪和非贪婪匹配原理以及获取更多正则相关原理,除了看书之外,推荐去一个CSDN的博客 雁过无痕-博客频道 - CSDN.NET ,讲解得很详细和透彻
二、语法一览
正则的语法相信许多人已经看过deerchao写的30分钟入门教程,我也是从那篇文字中入门的,deerchao从语法逻辑的角度以.NET正则的标准来讲述了正则语法,而我想重新组织一遍,以便于应用的角度、以JS为宿主语言来重新梳理一遍语法,这将便于我们把语言描述翻译成正则表达式。
下面这张一览图(可能需要放大),整理了常用的正则语法,并且将JS不支持的语法特性以红色标注出来了(正文将不会描述这些不支持的特性),语法部分的详细描述也将根据下面的图,从上到下,从左到右的顺序来梳理,尽量不啰嗦。
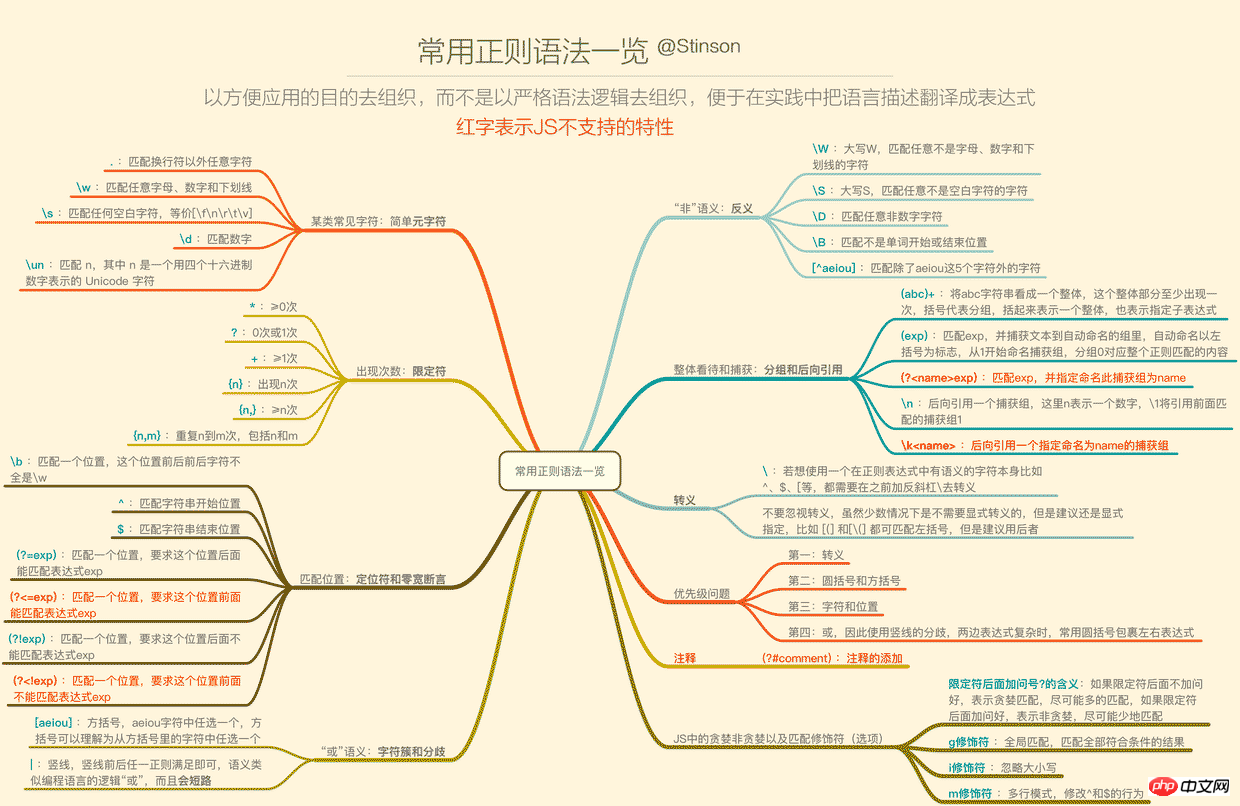
1. 要用某类常见字符——简单元字符
为什么这里要加简单2个字,因为在正则中,\d、\w这样的叫元字符,而{n,m}、(?!exp)这样的也叫元字符,所以元字符是在正则中有特定意义的标识,而这一小节讲的是简单的一些元字符。
.匹配除了换行符以外的任意字符,也即是[^\n],如果要包含任意字符,可使用(.|\n)
\w匹配任意字母、数字或者下划线,等价于[a-zA-Z0-9_],在deerchao的文中还指出可匹配汉字,但是\w在JS中是不能匹配汉字的
\s匹配任意空白符,包含换页符\f、换行符\n、回车符\r、水平制表符\t、垂直制表符\v
\d匹配数字
\un匹配n,这里的n是一个有4个十六进制数字表示的Unicode字符,比如\u597d表示中文字符“好”,那么超过\uffff编号的字符怎么表示呢?ES6的u修饰符会帮你。
2. 要表示出现次数(重复)——限定符
a*表示字符a连续出现次数 >= 0 次
a+表示字符a连续出现次数 >= 1 次
a? signifie que le caractère a apparaît 0 ou 1 fois
a{5} signifie que le caractère a apparaît 5 fois de suite
a{5,} représente le nombre d'occurrences consécutives du caractère a >= 5 fois
a{5,10} représente le nombre d'occurrences consécutives du caractère a de 5 à 10 fois, dont 5 et 10
3. Position correspondante - localisateur et assertion de largeur nulle
Les expressions correspondant à une certaine position sont toutes nulles. width, donc Il contient principalement deux parties, l'une est le localisateur, qui correspond à une position spécifique, et l'autre est l'assertion de largeur nulle, qui correspond à une position qui doit répondre à une certaine exigence. Les localisateurs
sont couramment utilisés comme suit :
b correspond à la position limite du mot. La description précise est qu'il correspond à une position. Cette position ne peut pas être décrite par w avant. et après les caractères, donc quelque chose comme u597dbabc peut correspondre à "bon abc".
^ correspond à la position de départ de la chaîne, qui est la position 0. Si la propriété Multiline de l'objet RegExp est définie, ^ correspond également à la position après 'n' ou 'r'
$ correspond à la position de fin de la chaîne. Si la propriété Multiline de l'objet RegExp est définie, $ correspond également à la position avant 'n' ou 'r'
- (?=exp) correspond à une position. Le côté droit de cette position peut correspondre à l'expression. exp. Notez que cette expression ne correspond qu'à une seule position, mais elle a des exigences pour le côté droit de cette position, et les éléments du côté droit ne seront pas mis dans le résultat. Par exemple, si vous utilisez read(?=ing) pour correspondre à "reading", le résultat est "read", et "ing" est
- (?!exp), qui ne sera pas inclus dans le résultat, correspond à une position, et le côté droit de cette position ne peut pas correspondre à l'expression exp
- [abc] représente un , b , c. Si les lettres ou les chiffres sont consécutifs, ils peuvent être représentés par - [b-f] représente l'un des caractères de b à f
- [(ab)( cd)] ne sera pas utilisé pour faire correspondre la chaîne "ab" ou "cd", mais pour faire correspondre l'un des six caractères a, b, c, d, (,) , c'est-à-dire si vous souhaitez exprimer l'exigence de "correspondant à la chaîne ab ou cd", vous ne pouvez pas faire cela. Vous devez écrire ab|cd comme ceci. Mais ici, vous devez faire correspondre les parenthèses elles-mêmes. Logiquement, vous devez les échapper avec des barres obliques inverses. Cependant, entre crochets, les parenthèses sont traitées comme des caractères ordinaires. Même ainsi, il est toujours recommandé d'échapper explicitement La différenciation est utilisée pour exprimer la sémantique "ou" au niveau de l'expression, ce qui signifie faire correspondre | Toute expression à gauche ou à droite :
- ab|cd sera correspondre à la chaîne " ab" ou "cd"
- sera court-circuité. Rappelez-vous le court-circuit du OU logique dans le
- langage de programmation
, utilisez donc (ab. |abc) pour correspondre à la chaîne "abc", le résultat sera "ab", car le côté gauche de la barre verticale a été satisfait, donc le résultat correspondant à gauche représente le résultat de l'expression régulière entière
5. Vouloir exprimer le sens de "pas" ——Antonymes
Parfois, nous voulons exprimer le besoin "sauf pour certains caractères". antonymes
- W, D , S, B. Les métacaractères représentés par des lettres majuscules sont les antonymes du contenu correspondant correspondant aux lettres minuscules. Ces métacaractères correspondent aux "caractères sauf les lettres, les chiffres et". traits de soulignement", "caractères non numériques" et "espaces non vides" dans l'ordre. "Caractère", "position limite non-mot"
- [^aeiou] représente n'importe quel caractère sauf a, e, i, o, u, qui est entre crochets et apparaît au début. Le ^ dans la position signifie l'exclusion. Si ^ n'apparaît pas au début entre crochets, alors il ne représente que le caractère ^ lui-même <.>
- 6. Vue globale et capture - regroupement et Référence arrière
En fait, vous avez vu des parenthèses à certains endroits ci-dessus. Oui, les parenthèses le sont. utilisé pour le regroupement. Ce qui est entouré d’une paire de parenthèses est un groupe.
上面讲的大部分是针对字符级别的,比如重复字母 “A” 5次,可以用A{5}来表示,但是如果想要字符串“ABC”重复5次呢?这个时候就需要用到括号。
括号的第一个作用,将括起来的分组当做一个整体看待,所以你可以像对待字符重复一样在一个分组后面加限定符,比如(ABC){5}。
分组匹配到的内容也就是这个分组捕获到的内容,从左往右,以左括号为标志,每个分组会自动拥有一个从1开始的编号,编号0的分组对应整个正则表达式,JS不支持捕获组显示命名。
括号的第二个作用,分组捕获到的内容,可以在之后通过\分组编号的形式进行后向引用。比如(ab|cd)123\1可以匹配“ab123ab”或者“cd123cd”,但是不能匹配“ab123cd”或“cd123ab”,这里有一对括号,也是第一对括号,所以编号为捕获组1,然后在正则中通过\1去引用了捕获组1的捕获的内容,这叫后向引用。
括号的第三个作用,改变优先级,比如abc|de和(abc|d)e表达的完全不是一个意思。
7. 转义
任何在正则表达式中有作用的字符都建议转义,哪怕有些情况下不转义也能正确,比如[]中的圆括号、^符号等。
8. 优先级问题
优先级从高到低是:
转义 \
括号(圆括号和方括号)(), (?:), (?=), []
字符和位置
竖线 |
9. 贪婪和非贪婪
在限定符中,除了{n}确切表示重复几次,其余的都是一个有下限的范围。
在默认的模式(贪婪)下,会尽可能多的匹配内容。比如用ab*去匹配字符串“abbb”,结果是“abbb”。
而通过在限定符后面加问号?可以进行非贪婪匹配,会尽可能少地匹配。用ab*?去匹配“abbb”,结果会是“a”。
不带问号的限定符也称匹配优先量词,带问号的限定符也称忽略匹配优先量词。
10. 修饰符(匹配选项)
其实正则的匹配选项有很多可选,不同的宿主语言环境下可能各有不同,此处就JS的修饰符作一个说明:
加g修饰符:表示全局匹配,模式将被应用到所有字符串,而不是在发现第一个匹配项时停止
加i修饰符:表示不区分大小写
加m修饰符:表示多行模式,会改变^和$的行为,上文已述
三、JS(ES5)中的正则
JS中的正则由引用类型RegExp表示,下面主要就RegExp类型的创建、两个主要方法和构造函数属性来展开,然后会提及String类型上的模式匹配,最后会简单罗列JS中正则的一些局限。
1. 创建正则表达式
一种是用字面量的方式创建,一种是用构造函数创建,我们始终建议用前者。
//创建一个正则表达式
var exp = /pattern/flags;
//比如
var pattern=/\b[aeiou][a-z]+\b/gi;
//等价下面的构造函数创建
var pattern=new RegExp("\\b[aeiou][a-z]+\\b","gi");
其中pattern可以是任意的正则表达式,flags部分是修饰符,在上文中已经阐述过了,有 g、i、m 这3个(ES5中)。
现在说一下为什么不要用构造函数,因为用构造函数创建正则,可能会导致对一些字符的双重转义,在上面的例子中,构造函数中第一个参数必须传入字符串(ES6可以传字面量),所以字符\ 会被转义成\,因此字面量的\b会变成字符串中的\\b,这样很容易出错,贼多的反斜杠。
2. RegExp上用来匹配提取的方法——exec()
var matches=pattern.exec(str); 接受一个参数:源字符串 返回:结果数组,在没有匹配项的情况下返回null
结果数组包含两个额外属性,index表示匹配项在字符串中的位置,input表示源字符串,结果数组matches第一项即matches[0]表示匹配整个正则表达式匹配的字符串,matches[n]表示于模式中第n个捕获组匹配的字符串。
要注意的是,第一,exec()永远只返回一个匹配项(指匹配整个正则的),第二,如果设置了g修饰符,每次调用exec()会在字符串中继续查找新匹配项,不设置g修饰符,对一个字符串每次调用exec()永远只返回第一个匹配项。所以如果要匹配一个字符串中的所有需要匹配的地方,那么可以设置g修饰符,然后通过循环不断调用exec方法。
//匹配所有ing结尾的单词
var str="Reading and Writing";
var pattern=/\b([a-zA-Z]+)ing\b/g;
var matches;
while(matches=pattern.exec(str)){
console.log(matches.index +' '+ matches[0] + ' ' + matches[1]);
}
//循环2次输出
//0 Reading Read
//12 Writing Writ
3. RegExp上用来测试匹配成功与否的方法——test()
var result=pattern.test(str);
接受一个参数:源字符串
返回:找到匹配项,返回true,没找到返回false
4. RegExp构造函数属性
RegExp构造函数包含一些属性,适用于作用域中的所有正则表达式,并且基于所执行的最近一次正则表达式操作而变化。
RegExp.input或RegExp["$_"]:最近一次要匹配的字符串
RegExp.lastMatch或RegExp["$&"]:最近一次匹配项
RegExp.lastParen或RegExp["$+"]:最近一次匹配的捕获组
RegExp.leftContext或RegExp["$`"]:input字符串中lastMatch之前的文本
RegExp.rightContext或RegExp["$'"]:input字符串中lastMatch之后的文本
RegExp["$n"]:表示第n个捕获组的内容,n取1-9
5. String类型上的模式匹配方法
上面提到的exec和test都是在RegExp实例上的方法,调用主体是一个正则表达式,而以字符串为主体调用模式匹配也是最为常用的。
5.1 匹配捕获的match方法
在字符串上调用match方法,本质上和在正则上调用exec相同,但是match方法返回的结果数组是没有input和index属性的。
var str="Reading and Writing"; var pattern=/\b([a-zA-Z]+)ing\b/g; //在String上调用match var matches=str.match(pattern); //等价于在RegExp上调用exec var matches=pattern.exec(str);
5.2 返回索引的search方法
接受的参数和match方法相同,要么是一个正则表达式,要么是一个RegExp对象。
//下面两个控制台输出是一样的,都是5 var str="I am reading."; var pattern=/\b([a-zA-Z]+)ing\b/g; var matches=pattern.exec(str); console.log(matches.index); var pos=str.search(pattern); console.log(pos);
5.3 查找并替换的replace方法
var result=str.replace(RegExp or String, String or Function); 第一个参数(查找):RegExp对象或者是一个字符串(这个字符串就被看做一个平凡的字符串) 第二个参数(替换内容):一个字符串或者是一个函数 返回:替换后的结果字符串,不会改变原来的字符串
第一个参数是字符串
只会替换第一个子字符串
第一个参数是正则
指定g修饰符,则会替换所有匹配正则的地方,否则只替换第一处
第二个参数是字符串
可以使用一些特殊的字符序列,将正则表达式操作的值插进入,这是很常用的。
$n:匹配第n个捕获组的内容,n取0-9
$nn:匹配第nn个捕获组内容,nn取01-99
$`:匹配子字符串之后的字符串
$':匹配子字符串之前的字符串
$&:匹配整个模式得字符串
$$:表示$符号本身
第二个参数是一个函数
在只有一个匹配项的情况下,会传递3个参数给这个函数:模式的匹配项、匹配项在字符串中的位置、原始字符串
在有多个捕获组的情况下,传递的参数是模式匹配项、第一个捕获组、第二个、第三个...最后两个参数是模式的匹配项在字符串位置、原始字符串
这个函数要返回一个字符串,表示要替换掉的匹配项
5.4 分隔字符串的split
基于指定的分隔符将一个字符串分割成多个子字符串,将结果放入一个数组,接受的第一个参数可以是RegExp对象或者是一个字符串(不会被转为正则),第二个参数可选指定数组大小,确保数组不会超过既定大小。
6 JS(ES5)中正则的局限
JS(ES5)中不支持以下正则特性(在一览图中也可以看到):
匹配字符串开始和结尾的\A和\Z锚 向后查找(所以不支持零宽度后发断言) 并集和交集类 原子组 Unicode支持(\uFFFF之后的) 命名的捕获组 单行和无间隔模式 条件匹配 注释
四、ES6对正则的主要加强
ES6对正则做了一些加强,这边仅仅简单罗列以下主要的3点,具体可以去看ES6
1. 构造函数可以传正则字面量了
ES5中构造函数是不能接受字面量的正则的,所以会有双重转义,但是ES6是支持的,即便如此,还是建议用字面量创建,简洁高效。
2. u修饰符
加了u修饰符,会正确处理大于\uFFFF的Unicode,意味着4个字节的Unicode字符也可以被支持了。
// \uD83D\uDC2A是一个4字节的UTF-16编码,代表一个字符
/^\uD83D/u.test('\uD83D\uDC2A')
// false,加了u可以正确处理
/^\uD83D/.test('\uD83D\uDC2A')
// true,不加u,当做两个unicode字符处理
加了u修饰符,会改变一些正则的行为:
.原本只能匹配不大于\uFFFF的字符,加了u修饰符可以匹配任何Unicode字符
Unicode字符新表示法\u{码点}必须在加了u修饰符后才是有效的
使用u修饰符后,所有量词都会正确识别码点大于0xFFFF的Unicode字符
使一些反义元字符对于大于\uFFFF的字符也生效
3. y修饰符
y修饰符的作用与g修饰符类似,也是全局匹配,开始从位置0开始,后一次匹配都从上一次匹配成功的下一个位置开始。
不同之处在于,g修饰符只要剩余位置中存在匹配就可,而y修饰符确保匹配必须从剩余的第一个位置开始。
所以/a/y去匹配"ba"会匹配失败,因为y修饰符要求,在剩余位置第一个位置(这里是位置0)开始就要匹配。
ES6对正则的加强,可以看这篇
五、应用正则的实践思路
应用正则,一般是要先想到正则(废话),只要看到和“找”相关的需求并且这个源是可以被字符串化的,就可以想到用正则试试。
一般在应用正则有两类情况,一是验证类问题,另一类是搜索、提取、替换类问题。验证,最常见的如表单验证;搜索,以某些设定的命令加关键词去搜索;提取,从某段文字中提取什么,或者从某个JSON对象中提取什么(因为JSON对象可以字符串化啊);替换,模板引擎中用到。
1. 验证类问题
验证类问题是我们最常遇到的,这个时候其实源字符串长什么样我们是不知道,鬼知道萌萌哒的用户会做出什么邪恶的事情来,推荐的方式是这样的:
首先用白话描述清楚你要怎样的字符串,描述好了之后,就开脑洞地想用户可能输入什么奇怪的东西,就是自己举例,拿一张纸可举一大堆的,有接受的和不接受的(这个是你知道的),这个过程中可能你会去修改之前的描述;
把你的描述拆解开来,翻译成正则表达式;
测试你的正则表达式对你之前举的例子的判断是不是和你预期一致,这里就推荐用在线的JS正则测试去做,不要自己去一遍遍写了。
2. 搜索、提取、替换类问题
这类问题,一般我们是知道源文本的格式或者大致内容的,所以在解决这类问题时一般已经会有一些测试的源数据,我们要从这些源数据中提取出什么、或者替换什么。
找到这些手上的源数据中你需要的部分;
观察这些部分的特征,这些部分本身的特征以及这些部分周围的特征,比如这部分前一个符号一定是一个逗号,后一个符号一定是一个冒号,总之就是找规律;
考察你找的特征,首先能不能确切地标识出你要的部分,不会少也不会多,然后考虑下以后的源数据也是如此么,以后会不会这些特征就没有了;
组织你对要找的这部分的描述,描述清楚经过你考察的特征;
翻译成正则表达式;
测试。
Enfin, j'ai fini d'écrire plus de 10 000 mots d'explications sur la régularité JS Après l'avoir écrit, j'ai constaté que ma maîtrise de la régularité s'est encore améliorée, je vous recommande donc de le faire fréquemment. , c'est très utile, et puis avoir envie de partager est très bénéfique pour moi et pour les autres. Merci à tous ceux qui peuvent le lire.
Je pense que vous maîtrisez la méthode après avoir lu le cas dans cet article. Pour des informations plus intéressantes, veuillez prêter attention aux autres articles connexes sur le site Web chinois de php !
Lecture recommandée :
Explication détaillée de l'utilisation de groupes réguliers de non-capture et de groupes de capture
Correspond à la banque numéro de carte saisi par l'utilisateur algorithme de Luhn
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Une analyse approfondie du composant de groupe de liste Bootstrap
- Explication détaillée du currying de la fonction JavaScript
- Exemple complet de génération de mot de passe JS et de détection de force (avec téléchargement du code source de démonstration)
- Angularjs intègre l'interface utilisateur WeChat (weui)
- Comment basculer rapidement entre le chinois traditionnel et le chinois simplifié avec JavaScript et l'astuce permettant aux sites Web de prendre en charge le basculement entre les compétences en chinois simplifié et traditionnel_javascript