
Maison >développement back-end >tutoriel php >Explication détaillée des en-têtes de requête HTTP et du corps de la requête
Explication détaillée des en-têtes de requête HTTP et du corps de la requête

- 小云云original
- 2018-03-29 11:13:216889parcourir
Cet article partage principalement avec vous l'explication détaillée des en-têtes et des corps de requête HTTP. L'étude de HTTP comprend principalement les quatre parties des bases de HTTP, les en-têtes et corps de requête HTTP, les en-têtes et codes d'état de réponse HTTP et le cache HTTP. .Pour HTTP En ce qui concerne l'expansion et l'extension, nous devons également comprendre et pratiquer les bases de HTTPS, de HTTP/2 et de WebSocket. Les points de connaissances de cette partie sont également résumés dans la revue de l'auteur de ma préparation au recrutement scolaire : du front-end Web à l'architecture d'application côté serveur.
Requête HTTP
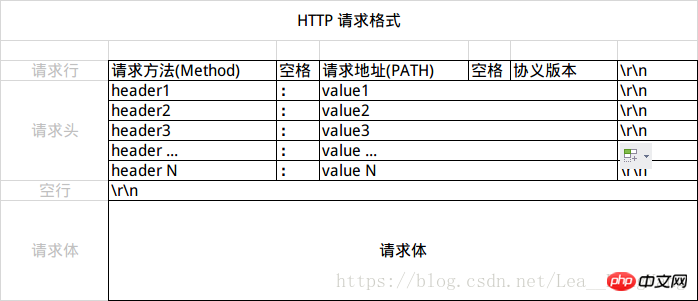
Le message de requête HTTP est divisé en trois parties : ligne de requête, en-tête de requête et corps de requête. Le format est le suivant : 
Les champs d'en-tête de message de requête typiques sont les suivants :
POST/GET http://download.microtool.de:80/somedata.exe Host: download.microtool.de Accept:*/* Pragma: no-cache Cache-Control: no-cache Referer: http://download.microtool.de/ User-Agent:Mozilla/4.04[en](Win95;I;Nav) Range:bytes=554554-
Ligne de requête : Ligne de requête
La ligne de requête (Request Line) est divisée en trois parties : méthode de requête, adresse de requête et protocole. et version, se terminant par CRLF(rn).
HTTP/1.1 définit 8 méthodes de requête : GET, POST, PUT, DELETE, PATCH, HEAD, OPTIONS, TRACE. Les deux plus courantes sont GET et POST. S'il s'agit d'une interface RESTful, GET et POST, DELETE, METTRE.
Méthodes de requête
Notez que seuls les trois verbes POST, PUT et PATCH contiendront le corps de la requête, tandis que les verbes GET, HEAD, DELETE, CONNECT, TRACE et OPTIONS contiendront le corps de la requête . Ne contient pas de corps de requête.
En-tête : En-tête de demande
| En-tête | Explication | Exemple |
|---|---|---|
| Accepter | Spécifiez les types de contenu que le client peut recevoir | Accepter : text/plain, text/html,application/json |
| Accept-Charset | Le jeu d'encodage de caractères que le navigateur peut accepter. | Accept-Charset : iso-8859-5 |
| Accept-Encoding | Spécifiez le type d'encodage de compression de contenu renvoyé par le serveur Web que le navigateur peut soutenir. | Accepter-Encodage : compresser, gzip |
| Accepter-Langue | Accepter-Langue : en,zh | |
| Vous pouvez demander un ou plusieurs champs de sous-plage de l'entité de la page Web | Accept-Ranges : octets | |
| Certificat d'autorisation pour autorisation HTTP | Autorisation : Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ== | |
| Spécifiez le mécanisme de mise en cache suivi par requêtes et réponses | Cache-Control : no-cache | |
| Indique si une connexion persistante est requise. (HTTP 1.1 utilise des connexions persistantes par défaut) | Connexion : fermer | |
| Lorsqu'une requête HTTP est envoyée, les informations stockées sous le demandé le nom de domaine sera Toutes les valeurs des cookies sont envoyées ensemble au serveur Web. | Cookie : $Version=1 ; Skin=new ; | |
| Content-Length | Longueur du contenu demandé | Content- Longueur : 348 |
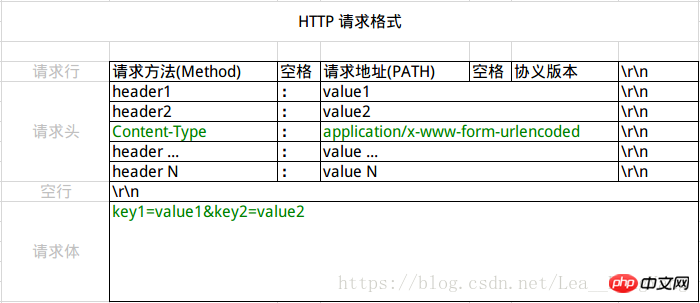
| Content-Type | Les informations MIME demandées correspondant à l'entité | Content-Type : application/x-www-form- urlencoded |
| Date | La date et l'heure auxquelles la demande a été envoyée | Date : mar 15 novembre 2010 08:12:31 GMT |
| Attendez-vous | Comportement spécifique du serveur demandé | Attendez-vous : 100-continuez |
| De | E-mail de l'utilisateur qui a fait la demande | De : user@email.com |
| Hôte | Précisez le nom de domaine et le numéro de port du serveur demandé | Hôte : www.zcmhi.com |
| If-Match | Valable uniquement si le contenu de la demande correspond à l'entité | If -Match : "737060cd8c284d8af7ad3082f209582d" |
| If-Modified-Since | Si la partie demandée est modifiée après le délai spécifié, la demande est réussie Si elle n'est pas modifiée. , un code 304 est renvoyé | If-Modified-Since : Sam 29 Oct 2010 19:43:31 GMT |
| If-None-Match | Si le contenu n'a pas changé, renvoie le code 304, le paramètre est l'Etag précédemment envoyé par le serveur, et est comparé à l'Etag répondu par le serveur pour déterminer s'il a changé | If-None- Correspondance : "737060cd8c284d8af7ad3082f209582d" |
| If-Range | Si l'entité n'a pas changé, le serveur envoie la partie manquante du client, sinon l'entité entière est envoyée.Les paramètres sont également Etag | If-Range: "737060cd8c284d8af7ad3082f209582d" |
| If-Unmodified-Since | seulement si l'entité n'a pas été modifiée après l'heure spécifiée La demande est réussie | If-Unmodified-Since : samedi 29 octobre 2010 19:43:31 GMT |
| Max-Forwards | Restreindre les informations via Time envoyé par les proxys et les passerelles | Max-Forwards : 10 : no-cache |
| Proxy-Authorization | Certificat d'autorisation pour se connecter au proxy | Proxy-Autorisation : Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ== |
| Plage | Ne demander qu'une partie de l'entité, préciser la plage | Plage : bytes=500-999 |
| Référent | L'adresse de la page Web précédente, suivie de la page Web actuellement demandée, c'est-à-dire la source | Référent : http://www.zcmhi.com/archives... |
| TE | Le codage de transfert que le client est prêt à accepter et demande au serveur d'accepter la queue ainsi que les informations d'en-tête | TE: trailers,deflate;q=0.5 |
| Mise à niveau | Spécifiez un certain protocole de transport vers le serveur pour conversion (si pris en charge) | Mise à niveau : HTTP/2.0, SHTTP/1.3, IRC/6.9, RTA/x11 |
| User-Agent | Le contenu de User-Agent contient les informations de l'utilisateur qui a fait la demande | User-Agent : Mozilla/5.0 (Linux; X11) |
| Via | Notifier l'adresse de la passerelle intermédiaire ou du serveur proxy, protocole de communication | Via : 1.0 fred, 1.1 nowhere.com (Apache/1.1) |
| Attention | Informations d'avertissement sur l'entité de message | Avertissement : 199 Avertissement divers |
Request Body:请求体Types根据应用场景的不同,HTTP请求的请求体有三种不同的形式。 任意类型移动开发者常见的,请求体是任意类型,服务器不会解析请求体,请求体的处理需要自己解析,如 POST JSON时候就是这类。 application/jsonapplication/json 这个 Content-Type 作为响应头大家肯定不陌生。实际上,现在越来越多的人把它作为请求头,用来告诉服务端消息主体是序列化后的 JSON 字符串。由于 JSON 规范的流行,除了低版本 IE 之外的各大浏览器都原生支持 JSON.stringify,服务端语言也都有处理 JSON 的函数,使用 JSON 不会遇上什么麻烦。 JSON 格式支持比键值对复杂得多的结构化数据,这一点也很有用。记得我几年前做一个项目时,需要提交的数据层次非常深,我就是把数据 JSON 序列化之后来提交的。不过当时我是把 JSON 字符串作为 val,仍然放在键值对里,以 x-www-form-urlencoded 方式提交。 Google 的 AngularJS 中的 Ajax 功能,默认就是提交 JSON 字符串。例如下面这段代码: JSvar data = {'title':'test', 'sub' : [1,2,3]};$http.post(url, data).success(function(result) {
...
});最终发送的请求是: BASHPOST http://www.example.com HTTP/1.1 Content-Type: application/json;charset=utf-8{"title":"test","sub":[1,2,3]}这种方案,可以方便的提交复杂的结构化数据,特别适合 RESTful 的接口。各大抓包工具如 Chrome 自带的开发者工具、Firebug、Fiddler,都会以树形结构展示 JSON 数据,非常友好。但也有些服务端语言还没有支持这种方式,例如 php 就无法通过 $_POST 对象从上面的请求中获得内容。这时候,需要自己动手处理下:在请求头中 Content-Type 为 application/json 时,从 当然 AngularJS 也可以配置为使用 x-www-form-urlencoded 方式提交数据。如有需要,可以参考这篇文章。 text/xml我的博客之前提到过 XML-RPC(XML Remote Procedure Call)。它是一种使用 HTTP 作为传输协议,XML 作为编码方式的远程调用规范。典型的 XML-RPC 请求是这样的: HTMLPOST http://www.example.com HTTP/1.1
Content-Type: text/xml<?xml version="1.0"?><methodCall>
<methodName>examples.getStateName</methodName>
<params>
<param>
<value><i4>41</i4></value>
</param>
</params></methodCall>XML-RPC 协议简单、功能够用,各种语言的实现都有。它的使用也很广泛,如 WordPress 的 XML-RPC Api,搜索引擎的 ping 服务等等。JavaScript 中,也有现成的库支持以这种方式进行数据交互,能很好的支持已有的 XML-RPC 服务。不过,我个人觉得 XML 结构还是过于臃肿,一般场景用 JSON 会更灵活方便。 Chaîne de requête :application/x-www-form-urlencodedIl s'agit du moyen le plus courant de soumettre des données via POST. Le formulaire ff9c23ada1bcecdd1a0fb5d5a0f18437 natif du navigateur, si l'attribut enctype n'est pas défini, soumettra finalement les données en mode application/x-www-form-urlencoded. La requête est similaire à la suivante (les en-têtes de requête non pertinents sont omis dans cet article) :
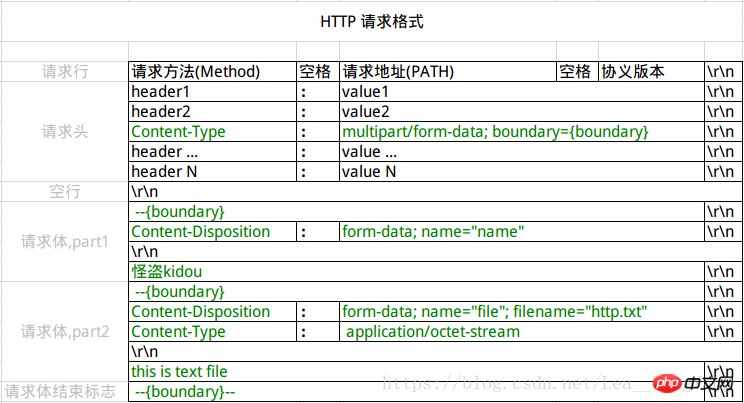
Tout d'abord, Content-Type est spécifié comme application/x-www-form-urlencoded ; l'exigence de format ici est l'exigence de format de la chaîne de requête dans l'URL : plusieurs paires clé-valeur sont connectées avec &, et des clés et des valeurs. sont précédés de = Connection, et seuls les caractères ASCII peuvent être utilisés. Les caractères non-ASCII doivent être codés à l'aide d'UrlEncode. La plupart des langages côté serveur prennent bien en charge cette méthode. Par exemple, en PHP, $_POST['title'] peut obtenir la valeur du titre et $_POST['sub'] peut obtenir le sous-tableau. Répartition des fichiersLe corps de la requête du troisième corps de la requête est divisé en plusieurs parties et sera utilisé lors du téléchargement de fichiers. Ce format est le premier. doit être utilisé dans la transmission par courrier électronique. Chaque champ/fichier est divisé en segments distincts par la limite (spécifiée dans Content-Type). Chaque segment commence par -- plus la limite, suivi de l'en-tête de description du segment, et est vide après le. en-tête de description. Le contenu est connecté sur une seule ligne. La fin de la requête est marquée de -- après la limite. La structure est présentée dans la figure ci-dessous : BASHPOST http://www.example.com HTTP/1.1Content-Type:multipart/form-data; boundary=----WebKitFormBoundaryrGKCBY7qhFd3TrwA------WebKitFormBoundaryrGKCBY7qhFd3TrwAContent-Disposition: form-data; name="text"title------WebKitFormBoundaryrGKCBY7qhFd3TrwAContent-Disposition: form-data; name="file"; filename="chrome.png"Content-Type: image/pngPNG ... content of chrome.png ...------WebKitFormBoundaryrGKCBY7qhFd3TrwA-- 这个例子稍微复杂点。首先生成了一个 boundary 用于分割不同的字段,为了避免与正文内容重复,boundary 很长很复杂。然后 Content-Type 里指明了数据是以 multipart/form-data 来编码,本次请求的 boundary 是什么内容。消息主体里按照字段个数又分为多个结构类似的部分,每部分都是以 这种方式一般用来上传文件,各大服务端语言对它也有着良好的支持。 上面提到的这两种 POST 数据的方式,都是浏览器原生支持的,而且现阶段标准中原生 ff9c23ada1bcecdd1a0fb5d5a0f18437 表单也只支持这两种方式(通过 ff9c23ada1bcecdd1a0fb5d5a0f18437 元素的 随着越来越多的 Web 站点,尤其是 WebApp,全部使用 Ajax 进行数据交互之后,我们完全可以定义新的数据提交方式,给开发带来更多便利。 Encoding:编码网页中的表单使用POST方法提交时,数据内容的类型是 application/x-www-form-urlencoded,这种类型会: 1.字符"a"-"z","A"-"Z","0"-"9",".","-","*",和"_" 都不会被编码; 2. Convertissez les espaces en signes plus (+) 3. Convertissez le contenu non textuel sous la forme de "%xy", xy est une valeur hexadécimale à deux chiffres 4. Placez un symbole & entre chaque paire nom=valeur. L'un des nombreux problèmes rencontrés par les concepteurs de sites Web est de savoir comment gérer les différences entre les différents systèmes d'exploitation. Ces différences entraînent des problèmes avec les URL : par exemple, certains systèmes d'exploitation autorisent les espaces dans les noms de fichiers, tandis que d'autres ne le font pas. La plupart des systèmes d'exploitation ne pensent pas que le symbole « # » dans le nom de fichier a une signification particulière ; mais dans une URL, le symbole « # » indique que le nom de fichier est terminé, suivi d'un identifiant de fragment (partie). D'autres caractères spéciaux, jeux de caractères non alphanumériques, qui ont une signification particulière dans l'URL ou sur un autre système d'exploitation, posent des problèmes similaires. Afin de résoudre ces problèmes, les caractères que nous utilisons dans l'URL doivent être des éléments d'un jeu de caractères fixe du jeu de caractères ASCII, comme suit : 1. Lettres majuscules A-Z 2. Lettres minuscules a-z 3. Chiffres 0-9 4. Caractères de ponctuation - _ ~ * ' (et,) Caractères tels que : / & @. # $ + = et % peuvent également être utilisés, mais chacun a son propre objectif particulier Si un nom de fichier contient ces caractères ( / & ? @ # $ + = % ), ces caractères et tous les autres caractères doivent être codés. Le processus d'encodage est très simple. Tous les caractères qui ne sont pas des chiffres ASCII, des lettres ou les caractères de ponctuation susmentionnés seront convertis sous forme d'octets. Chaque octet est écrit sous cette forme : un "%" suivi de deux valeurs hexadécimales. Les espaces sont un cas particulier car ils sont très courants. En plus d'être codé sous la forme "%20", il peut également être codé sous la forme d'un "+". Le signe plus (+) lui-même est codé comme %2B. /# = & et ? doivent être codés lorsqu'ils sont utilisés dans le cadre d'un nom, plutôt que comme séparateur entre les parties de l'URL. ATTENTION Cette stratégie n'est pas idéale dans des environnements hétérogènes comportant un grand nombre de jeux de caractères. Par exemple : sur les systèmes Windows américains, é est codé sous la forme %E9. Sur les Mac américains, il est codé sous la forme %8E. L’existence de cette incertitude constitue une lacune évidente des URI existants. Par conséquent, les futures spécifications d’URI devraient être améliorées grâce aux identifiants internationaux de ressources (IRI). Les URL de classe n'effectuent pas automatiquement l'encodage ou le décodage. Vous pouvez générer un objet URL, qui peut contenir des caractères ASCII et non-ASCII illégaux et/ou %xx. Ces caractères et caractères d'échappement ne sont pas automatiquement codés ou décodés lors de l'utilisation des méthodes getPath() et toExternalForm() comme méthodes de sortie. Vous êtes responsable des objets chaîne utilisés pour générer un objet URL, en vous assurant que tous les caractères sont codés de manière appropriée. Recommandations associées : |
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Tous les symboles d'expression dans les expressions régulières (résumé)