
Maison >développement back-end >tutoriel php >Comment développer un robot simple avec PHP
Comment développer un robot simple avec PHP

- 零到壹度original
- 2018-03-27 10:52:536924parcourir
Parfois, en raison du travail et de nos propres besoins, nous parcourons différents sites Web pour obtenir les données dont nous avons besoin, c'est pourquoi les robots d'exploration sont nés. Voici le processus de développement d'un robot d'exploration simple et les problèmes rencontrés. Pour développer un robot, vous devez d'abord savoir à quoi va servir votre robot. Je souhaite l'utiliser pour trouver des articles avec des mots-clés spécifiques sur différents sites Web et obtenir leurs liens afin de pouvoir les lire rapidement.
Selon mes habitudes personnelles, j'ai d'abord besoin d'écrire une interface et de clarifier mes idées.
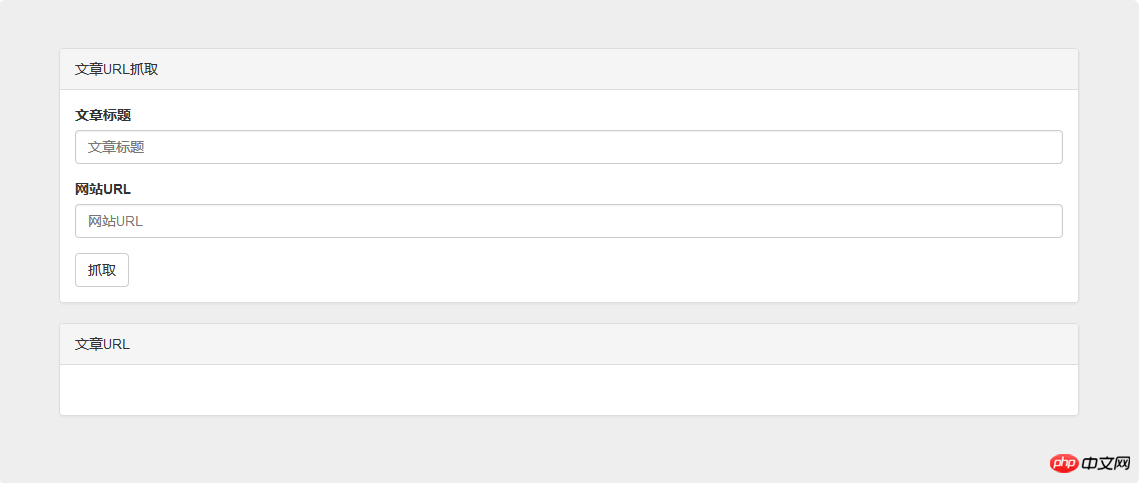
1. Accédez à différents sites Web. Ensuite, nous avons besoin d’une zone de saisie d’URL.
2. Recherchez des articles avec des mots-clés spécifiques. Ensuite, nous avons besoin d’une zone de saisie du titre de l’article.
3. Obtenez le lien de l'article. Ensuite, nous avons besoin d'un conteneur d'affichage pour les résultats de recherche.
[xhtml] view plain copy
<p class="jumbotron" id="mainJumbotron">
<p class="panel panel-default">
<p class="panel-heading">文章URL抓取</p>
<p class="panel-body">
<p class="form-group">
<label for="article_title">文章标题</label>
<input type="text" class="form-control" id="article_title" placeholder="文章标题">
</p>
<p class="form-group">
<label for="website_url">网站URL</label>
<input type="text" class="form-control" id="website_url" placeholder="网站URL">
</p>
<button type="submit" class="btn btn-default">抓取</button>
</p>
</p>
<p class="panel panel-default">
<p class="panel-heading">文章URL</p>
<p class="panel-body">
<h3></h3>
</p>
</p>
</p>Ajoutez le code directement, puis ajoutez vos propres ajustements de style, et l'interface est terminée :
Ensuite, le la prochaine étape est la fonction Elle a été implémentée. J'utilise PHP pour l'écrire. La première étape consiste à obtenir le code html du site. Il existe de nombreuses façons d'obtenir le code html, je ne les présenterai pas une par une. J'utilise curl pour l'obtenir. Il suffit de transmettre l'url du site. Vous avez le code html :
[xhtml] view plain copy
private function get_html($url){
$ch = curl_init();
$timeout = 10;
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_ENCODING, 'gzip');
curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.131 Safari/537.36');
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, $timeout);
$html = curl_exec($ch);
return $html;
}Bien que vous ayez le code html, vous rencontrerez bientôt un problème, c'est-à-dire le problème d'encodage, qui. peut faire votre prochaine étape de correspondance en vain. Nous voilà Unifier le contenu html obtenu en encodage utf8 :
[php] view plain copy $coding = mb_detect_encoding($html); if ($coding != "UTF-8" || !mb_check_encoding($html, "UTF-8")) $html = mb_convert_encoding($html, 'utf-8', 'GBK,UTF-8,ASCII');
Récupérer le html du site Web Pour obtenir l'url de l'article, l'étape suivante est. Pour faire correspondre toutes les balises a sous la page Web, ce qui nécessite l'utilisation d'expressions régulières, après de nombreux tests, nous avons finalement obtenu une expression régulière relativement fiable. Quelle que soit la complexité de la structure sous la balise a, nous ne la laisserons pas faire. allez-y tant qu'il s'agit d'une balise : (l'étape la plus critique)
[php] view plain copy $pattern = '|<a[^>]*>(.*)</a>|isU'; preg_match_all($pattern, $html, $matches);
Le résultat de la correspondance est dans $matches, qui est probablement un groupe d'éléments multidimensionnels comme celui-ci
[js] view plain copy
array(2) {
[0]=>
array(*) {
[0]=>
string(*) "完整的a标签"
.
.
.
}
[1]=>
array(*) {
[0]=>
string(*) "与上面下标相对应的a标签中的内容"
}
} Tant que vous pouvez obtenir ces données, tout le reste est complètement opérationnel. Vous pouvez parcourir ce groupe d'éléments pour trouver votre Si vous voulez la balise a, alors obtenez les attributs correspondants de la balise a. Vous pouvez le faire comme bon vous semble. voulez. Voici une classe recommandée pour vous faciliter l'utilisation de la balise a :
[php] view plain copy
$dom = new DOMDocument();
@$dom->loadHTML($a);//$a是上面得到的一些a标签
$url = new DOMXPath($dom);
$hrefs = $url->evaluate('//a');
for ($i = 0; $i < $hrefs->length; $i++) {
$href = $hrefs->item($i);
$url = $href->getAttribute('href'); //这里获取a标签的href属性
}Bien sûr, ce n'est qu'une façon, vous pouvez également utiliser des expressions régulières pour faire correspondre les informations souhaitées. et jouez de nouveaux tours avec les données.
得到并匹配得出你想要的结果,下一步当然就是传回前端将他们显示出来啦,把接口写好,然后前端用js获取数据,用jquery动态添加内容显示出来:
[php] view plain copy
var website_url = '你的接口地址';
$.getJSON(website_url,function(data){
if(data){
if(data.text == ''){
$('#article_url').html('<p><p>暂无该文章链接</p></p>');
return;
}
var string = '';
var list = data.text;
for (var j in list) {
var content = list[j].url_content;
for (var i in content) {
if (content[i].title != '') {
string += '<p class="item">' +
'<em>[<a href="http://' + list[j].website.web_url + '" target="_blank">' + list[j].website.web_name + '</a>]</em>' +
'<a href=" ' + content[i].url + '" target="_blank" class="web_url">' + content[i].title + '</a>' +
'</p>';
}
}
}
$('#article_url').html(string);
});上最终效果图:
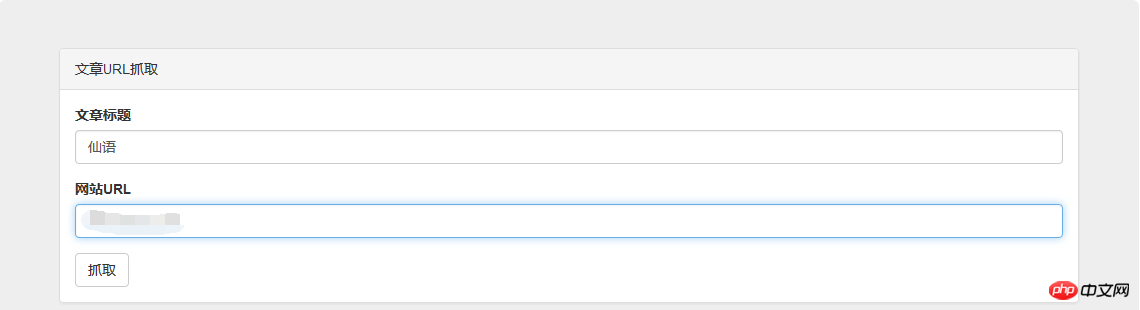

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Tous les symboles d'expression dans les expressions régulières (résumé)