
Maison >interface Web >js tutoriel >Définir l'expiration des cookies pour qu'ils se mettent automatiquement à jour et obtiennent automatiquement
Définir l'expiration des cookies pour qu'ils se mettent automatiquement à jour et obtiennent automatiquement
- php中世界最好的语言original
- 2018-03-17 10:15:223785parcourir
Cette fois, je vais vous présenter quelles sont les précautions pour définir l'expiration des cookies, la mise à jour automatique et l'acquisition automatique, et la configuration de l'expiration des cookies, de la mise à jour automatique et de l'acquisition automatique. Ce qui suit est un cas pratique, voyons. jetez un oeil.
Cet article met en œuvre l'acquisition automatique des cookies et la mise à jour automatique des cookies lorsqu'ils expirent.
De nombreuses informations sur les sites de réseaux sociaux nécessitent une connexion pour les obtenir. Prenez Weibo comme exemple. Sans vous connecter, vous ne pouvez voir que les dix principales publications Weibo des grands Vs. Pour rester connecté, les cookies sont requis. Prenons l'exemple de la connexion à www.weibo.cn :
Saisie dans Chrome : http://login.weibo.cn/login/
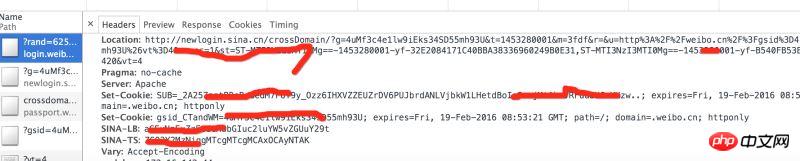
Contrôle d'analyse Lorsque la demande d'en-tête de la station est renvoyée, vous verrez plusieurs ensembles de cookies renvoyés par weibo.cn.
Étapes de mise en œuvre :
1. Utilisez Selenium pour vous connecter automatiquement afin d'obtenir des cookies et de les enregistrer dans un fichier
2. Lisez le cookie, comparez la période de validité du cookie, et s'il expire, effectuez à nouveau l'étape 1 3 Lorsque vous demandez d'autres pages Web, remplissez le cookie pour conserver le statut de connexion. 1. Obtenez des cookies en ligneUtilisez Selenium + PhantomJS pour simuler la connexion au navigateur et obtenir des cookies Il existe généralement plusieurs cookies et les cookies sont stockés un par un ; Fichier de suffixe .weibo.def get_cookie_from_network():
from selenium import webdriver
url_login = 'http://login.weibo.cn/login/'
driver = webdriver.PhantomJS()
driver.get(url_login)
driver.find_element_by_xpath('//input[@type="text"]').send_keys('your_weibo_accout') # 改成你的微博账号
driver.find_element_by_xpath('//input[@type="password"]').send_keys('your_weibo_password') # 改成你的微博密码
driver.find_element_by_xpath('//input[@type="submit"]').click() # 点击登录
# 获得 cookie信息
cookie_list = driver.get_cookies()
print cookie_list
cookie_dict = {}
for cookie in cookie_list:
#写入文件
f = open(cookie['name']+'.weibo','w')
pickle.dump(cookie, f)
f.close()
if cookie.has_key('name') and cookie.has_key('value'):
cookie_dict[cookie['name']] = cookie['value']
return cookie_dict2. Obtenez des cookies à partir de fichiers Parcourez les fichiers se terminant par .weibo, c'est-à-dire les fichiers cookies, à partir du répertoire actuel. Utilisez pickle pour le décompresser dans un dict, comparez la valeur d'expiration avec l'heure actuelle et renvoyez vide s'il expire
def get_cookie_from_cache():
cookie_dict = {}
for parent, dirnames, filenames in os.walk('./'):
for filename in filenames:
if filename.endswith('.weibo'):
print filename
with open(self.dir_temp + filename, 'r') as f:
d = pickle.load(f)
if d.has_key('name') and d.has_key('value') and d.has_key('expiry'):
expiry_date = int(d['expiry'])
if expiry_date > (int)(time.time()):
cookie_dict[d['name']] = d['value']
else:
return {}
return cookie_dict3 Si le cookie mis en cache expire, récupérez à nouveau le cookie du réseau
def get_cookie(): cookie_dict = get_cookie_from_cache() if not cookie_dict: cookie_dict = get_cookie_from_network() return cookie_dict. 🎜>4. Utilisez des cookies pour demander d'autres pages d'accueil Weibo
def get_weibo_list(self, user_id):
import requests
from bs4 import BeautifulSoup as bs
cookdic = get_cookie()
url = 'http://weibo.cn/stocknews88'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.57 Safari/537.36'}
timeout = 5
r = requests.get(url, headers=headers, cookies=cookdic,timeout=timeout)
soup = bs(r.text, 'lxml')
...
# 用BeautifulSoup 解析网页
...
Je pense que vous maîtrisez la méthode après avoir lu le cas dans cet article. Pour des informations plus intéressantes, veuillez prêter attention à. d'autres articles connexes sur le site PHP chinois ! Lecture recommandée : React Native utilise la récupération pour télécharger des images
Comment réduire la taille des fichiers empaquetés par Webpack après compression
Utiliser l'importation et exiger le package JS
Effet spécial de la barre de navigation étoilée
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Une analyse approfondie du composant de groupe de liste Bootstrap
- Explication détaillée du currying de la fonction JavaScript
- Exemple complet de génération de mot de passe JS et de détection de force (avec téléchargement du code source de démonstration)
- Angularjs intègre l'interface utilisateur WeChat (weui)
- Comment basculer rapidement entre le chinois traditionnel et le chinois simplifié avec JavaScript et l'astuce permettant aux sites Web de prendre en charge le basculement entre les compétences en chinois simplifié et traditionnel_javascript