
Maison >base de données >tutoriel mysql >Aperçu détaillé des statistiques MySQL
Aperçu détaillé des statistiques MySQL
- php中世界最好的语言original
- 2018-03-05 16:12:542655parcourir
Cet article fournit un aperçu complet des points de connaissance pertinents des informations statistiques MySQL à travers l'introduction du concept d'informations statistiques et des avantages des informations statistiques MYSQL. J'espère qu'il pourra aider les amis dans le besoin.
MySQL passera par le processus d'analyse SQL et d'optimisation des requêtes lors de l'exécution de SQL. L'analyseur décompose SQL en structures de données et les transmet aux étapes suivantes. L'optimiseur de requêtes trouve la meilleure solution pour exécuter les requêtes SQL. et génère un plan d'exécution. L'optimiseur de requêtes détermine comment SQL est exécuté, en s'appuyant sur les statistiques de la base de données. Ci-dessous, nous présentons le contenu pertinent des statistiques innodb dans MySQL 5.7.
Le stockage des statistiques MySQL est divisé en deux types, les statistiques non persistantes et persistantes.
1. Informations statistiques non persistantes
Les informations statistiques non persistantes sont stockées en mémoire Si la base de données est redémarrée, les informations statistiques seront perdues. Il existe deux manières de définir des statistiques non persistantes :
| ||||||||||||||
|
2 Paramètres de la table CREATE/ALTER, STATS_PERSISTENT=0 | ||||||||||||||
1 Exécuter ANALYZE TABLE | ||||||||||||||
2 Lorsque innodb_stats_on_metadata=ON, exécutez SHOW TABLE STATUS, SHOW INDEX, interrogez TABLES sous INFORMATION_SCHEMA, STATISTICS | ||||||||||||||
3 Lorsque la fonction --auto-rehash est activée, utilisez le client MySQL pour vous connecter
|
||||||||||||||
4 Table pour la première fois Ouvert | ||||||||||||||
| ||||||||||||||
innodb_index_stats | |
database_name |
数据库名 |
table_name |
表名 |
index_name |
索引名 |
last_update |
统计信息最后一次更新时间 |
stat_name |
统计信息名 |
stat_value |
统计信息的值 |
sample_size |
采样大小 |
stat_description |
类型说明 |
| 1 INNODB_STATS_AUTO_RECALC=ON, 10% des données du tableau sont modifiées |
| 2 Ajouter un nouvel index |
| innodb_table_stats | |
| database_name | Nom de la base de données |
| nom_table | Nom de la table |
| last_update | Heure de la dernière mise à jour des statistiques |
| n_rows | Le nombre de lignes dans le tableau |
| clustered_index_size | Le nombre de pages dans l'index clusterisé |
| sum_of_other_index_sizes | Autres pages d'index Nombre de |
| innodb_index_stats | |
| database_name | Nom de la base de données td> |
| nom_table | Nom de la table |
| index_name | Nom de l'index |
| last_update | Heure de la dernière mise à jour des statistiques |
| nom_stat | Nom des statistiques | tr>
| La valeur des informations statistiques | |
| sample_size | Taille d'échantillonnage |
| stat_description | Description du type td> |
Pour mieux comprendre innodb_index_stats, créez un tableau de test pour explication :
CREATE TABLE t1 ( a INT, b INT, c INT, d INT, e INT, f INT, PRIMARY KEY (a, b), KEY i1 (c, d), UNIQUE KEY i2uniq (e, f) ) ENGINE=INNODB;
Écrivez les données comme suit :
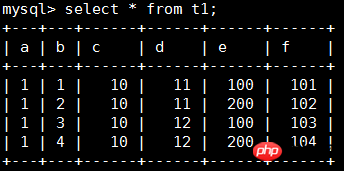
Pour afficher les informations statistiques de la table t1, vous devez vous concentrer sur les champs stat_name et stat_value
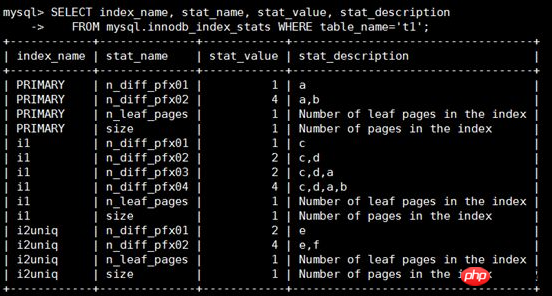
Quand tat_name=size: stat_value indique le nombre de pages indexées
Quand stat_name=n_leaf_pages : stat_value représente le nombre de nœuds feuilles
Quand stat_name=n_diff_pfxNN : stat_value représente le nombre de valeurs uniques sur le champ d'index Voici un. explication détaillée :
1. n_diff_pfx01 représente le nombre après le distinct de la première colonne de l'index. Par exemple, la colonne a de PRIMARY n'a qu'une seule valeur 1, donc lorsque index_name='PRIMARY' et stat_name=' n_diff_pfx01', stat_value=1.
2. n_diff_pfx02 représente le nombre après la distincte des deux premières colonnes de l'index. Par exemple, les colonnes e et f de i2uniq ont 4 valeurs, donc quand index_name='i2uniq' et stat_name='n_diff_pfx02. ', valeur_stat=4.
3. Pour les index non uniques, l'index de clé primaire sera ajouté après les colonnes d'origine, telles que index_name='i1' et stat_name='n_diff_pfx03', et la colonne de clé primaire a sera ajoutée après les colonnes d'index d'origine c et d, (le résultat distinct de c, d, a) est 2.
Comprendre la signification spécifique de stat_name et stat_value peut nous aider à déterminer pourquoi un index approprié n'est pas utilisé lors de l'exécution de SQL. Par exemple, la stat_value d'un certain index n_diff_pfxNN est beaucoup plus petite que la valeur réelle de l'optimiseur de requête. considère l’indice comme sélectif. S’il est mauvais, cela peut conduire à utiliser un mauvais indice.
3. Gestion des informations statistiques inexactes
Nous avons vérifié le plan d'exécution et constaté que l'index correct n'a pas été utilisé. Si cela est dû à une grande différence dans les informations statistiques dans innodb_index_stats, cela peut être le cas. être traité des manières suivantes :
1. Mettre à jour manuellement les informations statistiques. Notez que des verrous de lecture seront ajoutés lors de l'exécution :
ANALYZETABLE TABLE_NAME;
2. les informations sont toujours inexactes après la mise à jour, pensez à en ajouter d'autres. La page de données d'échantillonnage de table peut être modifiée de deux manières :
a) Variable globale INNODB_STATS_PERSISTENT_SAMPLE_PAGES, la valeur par défaut est 20
b) Une seule ; table peut spécifier l'échantillonnage de la table :
ALTER TABLE TABLE_NAME STATS_SAMPLE_PAGES=40;
Après le test, la valeur maximale de STATS_SAMPLE_PAGES est ici de 65535. Si elle dépasse, une erreur sera signalée.
Actuellement, MySQL ne fournit pas de fonction d'histogramme. Dans certains cas (comme une distribution inégale des données), la simple mise à jour des informations statistiques ne permet pas nécessairement d'obtenir un plan d'exécution précis. Les index ne peuvent être spécifiés que via des indices d'index. La nouvelle version 8.0 ajoutera une fonction d'histogramme, attendons avec impatience que MySQL devienne de plus en plus puissant !
Recommandations associées :
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!