
Maison >interface Web >js tutoriel >Une brève introduction à React
Une brève introduction à React

- 小云云original
- 2018-02-28 13:22:481640parcourir
Cet article partage principalement avec vous l'origine et le développement de React. J'espère qu'il pourra vous aider.
L'ère de l'épissage des personnages - 2004
En 2004, Mark Zuckerberg travaillait encore sur la version originale de Facebook dans son dortoir.
Cette année, tout le monde utilise la fonction de concaténation de chaînes de PHP pour développer des sites Web.
$str = '<ul>';
foreach ($talks as $talk) {
$str += '<li>' . $talk->name . '</li>';
}
$str += '</ul>';
Cette méthode de développement de site Web semblait très correcte à l'époque, car peu importe qu'il s'agisse de développement back-end ou de développement front-end, ou même sans aucune expérience en développement, vous pouvez utiliser cette méthode pour créer un grand site Web.
Le seul inconvénient est que cette méthode de développement peut facilement provoquer une injection XSS et d'autres problèmes de sécurité. Si $talk->name contient du code malveillant et qu'aucune mesure de protection n'est prise, l'attaquant peut injecter du code JS arbitraire. Cela a donné naissance à la règle de sécurité « ne jamais faire confiance aux entrées de l'utilisateur ».
Le moyen le plus simple de résoudre ce problème est de échapper (Échapper) à toute entrée de l'utilisateur. Cependant, cela entraîne également d'autres problèmes. Si la chaîne est échappée plusieurs fois, le nombre d'anti-évasion doit également être le même, sinon le contenu original ne sera pas obtenu. Si vous échappez accidentellement à la balise HTML (Markup), la balise HTML sera affichée directement à l'utilisateur, ce qui entraînera une mauvaise expérience utilisateur.
Ère XHP - 2010
En 2010, afin de coder plus efficacement et d'éviter les erreurs d'échappement des balises HTML, Facebook a développé XHP. XHP est une extension de syntaxe de PHP, qui permet aux développeurs d'utiliser des balises HTML directement dans PHP au lieu d'utiliser des chaînes.
$content = <ul />;
foreach ($talks as $talk) {
$content->appendChild(<li>{$talk->name}</li>);
}
Dans ce cas, toutes les balises HTML utilisent une syntaxe différente de celle de PHP, et nous pouvons facilement distinguer celles qui doivent être échappées et celles qui ne le sont pas.
Peu de temps après, les ingénieurs de Facebook ont découvert qu'ils pouvaient également créer des balises personnalisées et que la combinaison de balises personnalisées aiderait à créer de grandes applications.
Et c'est exactement une implémentation des concepts de Web sémantique et de composants Web.
$content = <talk:list />;
foreach ($talks as $talk) {
$content->appendChild(<talk talk={$talk} />);
}
Après cela, Facebook a essayé de nouvelles méthodes techniques en JS pour réduire le délai entre le client et le serveur. Tels que les bibliothèques DOM multi-navigateurs et la liaison de données, mais ni l'une ni l'autre n'est idéale.
JSX - 2013
Attendez 2013, et soudain un jour, l'ingénieur front-end Jordan Walke propose une idée audacieuse à son manager : migrer les fonctions étendues de XHP vers JS. Au début, tout le monde pensait qu'il était fou parce que c'était incompatible avec le framework JS pour lequel tout le monde était optimiste à l'époque. Mais il a fini par convaincre son manager de lui donner six mois pour tester l’idée. Je dois dire ici que la bonne philosophie de gestion de l’ingénierie de Facebook est admirable et mérite d’être apprise.
Pièce jointe : Lee Byron parle de la culture des ingénieurs de Facebook : pourquoi investir dans les outils
Afin de migrer les fonctions étendues de XHP vers JS, la première tâche est d'avoir besoin d'une extension pour permettre à JS de prend en charge la syntaxe XML. L'extension s'appelle JSX. À cette époque, avec l’essor de Node.js, Facebook existait déjà une pratique considérable en matière d’ingénierie pour convertir JS. La mise en œuvre de JSX a donc été un jeu d’enfant et n’a pris qu’environ une semaine.
const content = (
<TalkList>
{ talks.map(talk => <Talk talk={talk} />)}
</TalkList>
);
React
Depuis, la longue marche de React a commencé, et de plus grandes difficultés sont encore à venir. Parmi eux, le plus délicat est de savoir comment reproduire le mécanisme de mise à jour en PHP.
En PHP, chaque fois que les données changent, il vous suffit de passer à une nouvelle page rendue par PHP.
Du point de vue d'un développeur, développer des applications de cette manière est très simple, car il n'a pas besoin de se soucier des changements, et tout est synchronisé lorsque les données utilisateur sur l'interface changent.
Tant qu'il y a un changement de données, la page entière sera restituée.
Bien que simple et grossière, l'inconvénient de cette méthode est également particulièrement important, c'est-à-dire qu'elle est très lente.
« Il faut avoir raison avant d'être bon » signifie que pour vérifier la faisabilité du plan de migration, les développeurs doivent rapidement implémenter une version utilisable, quels que soient les problèmes de performances du moment.
DOM
Inspiré par PHP, le moyen le plus simple d'implémenter le re-rendu en JS est : lorsqu'un contenu change, reconstruisez l'intégralité du DOM, puis remplacez l'ancien DOM. avec le nouveau DOM.
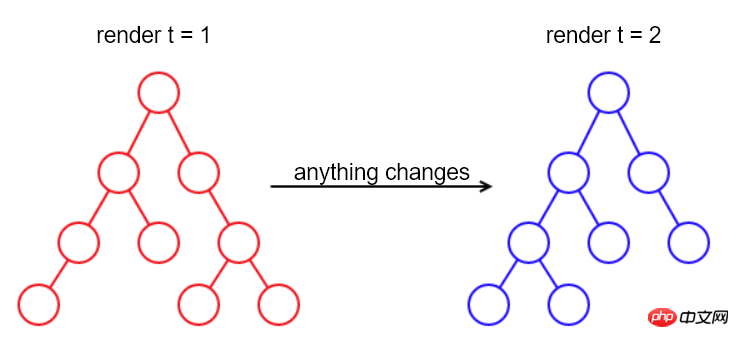
Cette méthode peut fonctionner, mais elle ne convient pas dans certains scénarios.
Par exemple, il perdra l'élément et le curseur actuellement ciblés, ainsi que la sélection de texte et la position de défilement de la page, qui sont l'état actuel de la page.
En d'autres termes, un nœud DOM est un qui contient un état.
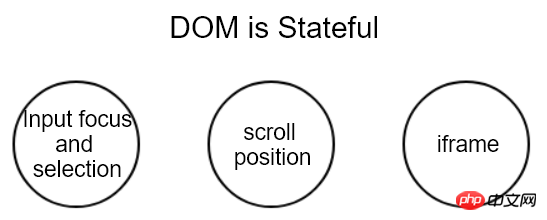
Puisqu'il contient de l'état, ne suffirait-il pas d'enregistrer l'état de l'ancien DOM puis de le restaurer sur le nouveau DOM ?
Mais malheureusement, cette méthode est non seulement compliquée à mettre en œuvre mais ne peut pas non plus couvrir toutes les situations.
Lors du défilement de la page sur un ordinateur OSX, il y aura une certaine inertie de défilement. Cependant, JS ne fournit pas d'API correspondante pour lire ou écrire l'inertie de défilement.
Pour les pages contenant iframe, la situation est plus compliquée. S'il provient d'un autre domaine, les restrictions de la politique de sécurité du navigateur ne nous permettront pas du tout de visualiser le contenu qu'il contient, et encore moins de le restaurer.
On peut donc voir que le DOM a non seulement un état, il contient également un état caché et inaccessible.
Puisque restaurer l’État ne fonctionne pas, trouvons un autre moyen de le contourner.
Pour les nœuds DOM inchangés, laissez-les tels quels et créez et remplacez uniquement les nœuds DOM modifiés.
Cette méthode implémente le nœud DOM reuse (Réutilisation).
À ce stade, tant que vous pouvez identifierquels nœuds ont changé, vous pouvez alors mettre à jour le DOM. La question devient donc comment comparer les différences entre deux DOM.
Diff
En parlant de différences de comparaison, je pense que tout le monde peut immédiatement penser au Version Control (Version Control). Son principe est très simple. Enregistrez plusieurs instantanés de code, puis utilisez l'algorithme diff pour comparer les deux instantanés avant et après, générant ainsi une série de modifications telles que « supprimer 5 lignes », « ajouter 3 lignes », « remplacer des mots ». , etc. ; via Appliquez cette série de modifications à l’instantané de code précédent pour obtenir l’instantané de code suivant.
Et c'est exactement ce dont React a besoin, sauf qu'il fonctionne avec le DOM au lieu des fichiers texte.
Pas étonnant que quelqu'un ait dit : « J'ai tendance à considérer React comme un Contrôle de version pour le DOM ».
DOM est une structure arborescente, donc l'algorithme de comparaison doit être basé sur la structure arborescente. La complexité de l'algorithme de comparaison de structure arborescente complète actuellement connu est O (n ^ 3).
S'il y a 10 000 nœuds DOM dans la page, ce nombre peut paraître énorme, mais il n'est pas inimaginable. Pour calculer l’ordre de grandeur de cette complexité, nous supposons également que nous pouvons effectuer une seule opération de comparaison en un seul cycle CPU (bien que cela soit impossible) et que le CPU est cadencé à 1 GHz. Dans ce cas, le temps que prend le différentiel est le suivant :
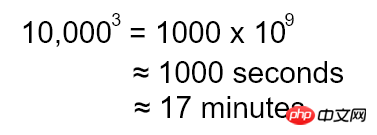
Une durée complète de 17 minutes, ce qui est inimaginable !
Bien que la phase de vérification ne prenne pas en compte les problèmes de performances pour le moment, nous pouvons quand même comprendre brièvement comment l'algorithme est implémenté.
Pièce jointe : algorithme complet d'implémentation de comparaison d'arbre.
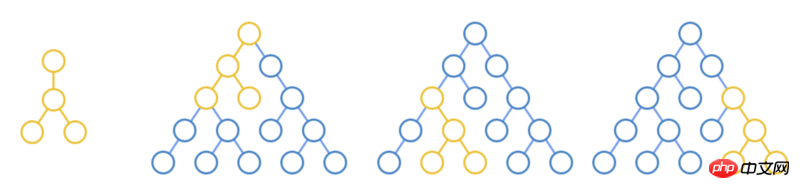
Comparez chaque nœud du nouvel arbre avec chaque nœud de l'ancien arbre
-
Si les nœuds parents sont les mêmes, continuez à boucler et à comparer les sous-arbres
Dans l'arborescence ci-dessus, basée sur le principe des opérations minimales, vous pouvez trouver trois comparaisons de boucles imbriquées .
Mais si vous y réfléchissez bien, dans les applications Web, il existe très peu de scénarios dans lesquels vous déplacez un élément vers un autre endroit. Un exemple pourrait être de glisser-déposer un élément vers un autre endroit, mais ce n'est pas courant.
Le seul scénario courant consiste à déplacer des éléments entre des sous-éléments, comme l'ajout, la suppression et le déplacement d'éléments dans une liste. Dans ce cas, vous ne pouvez comparer que les nœuds de même niveau .
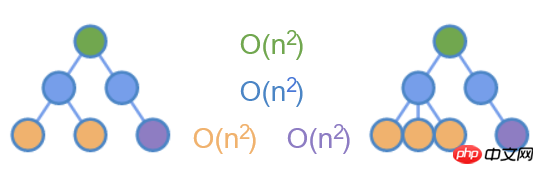
Comme le montre la figure ci-dessus, effectuez uniquement des différences sur les nœuds de la même couleur, ce qui réduit la complexité temporelle à O(n^2) .
clé

Un autre problème est introduit pour la comparaison d'éléments similaires.
Lorsque les noms d'éléments d'un même niveau sont différents, ils peuvent être directement identifiés comme des inadéquations lorsqu'ils sont identiques, ce n'est pas si simple ;
Supposons que sous un certain nœud, trois <input /> aient été rendus la dernière fois, puis deux aient été rendus la prochaine fois. Quel sera le résultat de la différence à ce moment-là ?
Le résultat le plus intuitif est de conserver les deux premiers inchangés et de supprimer le troisième.
Bien sûr, vous pouvez également supprimer le premier tout en conservant les deux derniers.
Si cela ne vous dérange pas, vous pouvez supprimer les trois anciens et ajouter deux nouveaux éléments.
Cela montre que pour les nœuds portant le même nom d'étiquette, nous n'avons pas suffisamment d'informations pour comparer les différences avant et après.

Et si vous ajoutiez les attributs de l'élément ? Par exemple, value, si les noms de balises et les attributs value sont identiques deux fois avant et après, alors les éléments sont considérés comme correspondant et aucune modification n'est nécessaire. Mais la réalité est que cela ne fonctionne pas, car la valeur change toujours lorsque l'utilisateur entre, ce qui entraînera le remplacement constant de l'élément, lui faisant perdre le focus, ce qui est pire, tous les éléments HTML n'ont pas cet attribut ; .

那使用所有元素都有的 id 属性呢?这是可以的,如上图,我们可以容易的识别出前后 DOM 的差异。考虑表单情况,表单模型的输入通常跟 id 关联,但如果使用 AJAX 来提交表单的话,我们通常不会给 input 设置 id 属性。因此,更好的办法是引入一个新的属性名称,专门用来辅助 diff 算法。这个属性最终确定为 key 。这也是为什么在 React 中使用列表时会要求给子元素设置 key 属性的原因。
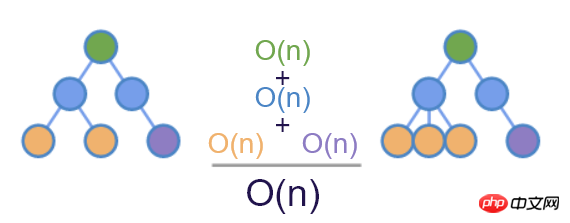
结合 key ,再加上哈希表,diff 算法最终实现了 O(n) 的最优复杂度。
至此,可以看到从 XHP 迁移到 JS 的方案可行的。接下来就可以针对各个环节进行逐步优化。
附:详细的 diff 理解:不可思议的 react diff 。
持续优化
Virtual DOM
前面说到,React 其实实现了对 DOM 节点的版本控制。
做过 JS 应用优化的人可能都知道,DOM 是复杂的,对它的操作(尤其是查询和创建)是非常慢非常耗费资源的。看下面的例子,仅创建一个空白的 p,其实例属性就达到 231 个。
// Chrome v63
const p = document.createElement('p');
let m = 0;
for (let k in p) {
m++;
}
console.log(m); // 231
之所以有这么多属性,是因为 DOM 节点被用于浏览器渲染管道的很多过程中。
浏览器首先根据 CSS 规则查找匹配的节点,这个过程会缓存很多元信息,例如它维护着一个对应 DOM 节点的 id 映射表。
然后,根据样式计算节点布局,这里又会缓存位置和屏幕定位信息,以及其他很多的元信息,浏览器会尽量避免重新计算布局,所以这些数据都会被缓存。
可以看出,整个渲染过程会耗费大量的内存和 CPU 资源。
现在回过头来想想 React ,其实它只在 diff 算法中用到了 DOM 节点,而且只用到了标签名称和部分属性。
如果用更轻量级的 JS 对象来代替复杂的 DOM 节点,然后把对 DOM 的 diff 操作转移到 JS 对象,就可以避免大量对 DOM 的查询操作。这种方式称为 Virtual DOM 。
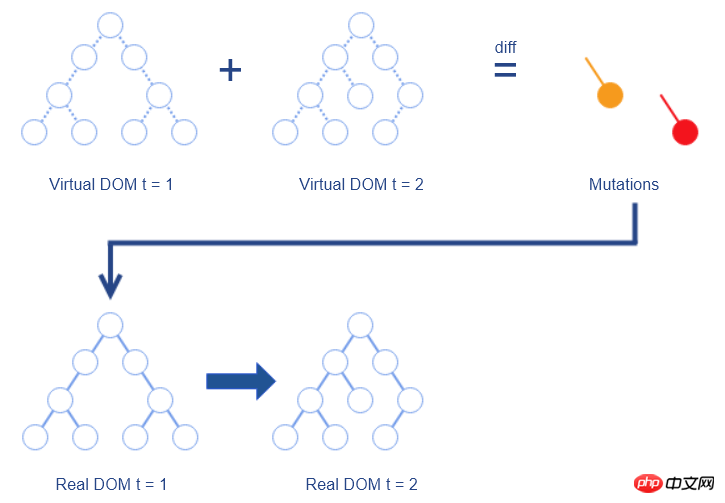
其过程如下:
维护一个使用 JS 对象表示的 Virtual DOM,与真实 DOM 一一对应
对前后两个 Virtual DOM 做 diff ,生成变更(Mutation)
把变更应用于真实 DOM,生成最新的真实 DOM
可以看出,因为要把变更应用到真实 DOM 上,所以还是避免不了要直接操作 DOM ,但是 React 的 diff 算法会把 DOM 改动次数降到最低。
至此,React 的两大优化:diff 算法和 Virtual DOM ,均已完成。再加上 XHP 时代尝试的数据绑定,已经算是一个可用版本了。
这个时候 Facebook 做了个重大的决定,那就是把 React 开源!
React 的开源可谓是一石激起千层浪,社区开发者都被这种全新的 Web 开发方式所吸引,React 因此迅速占领了 JS 开源库的榜首。
很多大公司也把 React 应用到生产环境,同时也有大批社区开发者为 React 贡献了代码。
接下来要说的两大优化就是来自于开源社区。
批处理(Batching)
著名浏览器厂商 Opera 把重排和重绘(Reflow and Repaint)列为影响页面性能的三大原因之一。
我们说 DOM 是很慢的,除了前面说到的它的复杂和庞大,还有另一个原因就是重排和重绘。
当 DOM 被修改后,浏览器必须更新元素的位置和真实像素;
当尝试从 DOM 读取属性时,为了保证读取的值是正确的,浏览器也会触发重排和重绘。
因此,反复的“读取、修改、读取、修改...”操作,将会触发大量的重排和重绘。
另外,由于浏览器本身对 DOM 操作进行了优化,比如把两次很近的“修改”操作合并成一个“修改”操作。
所以如果把“读取、修改、读取、修改...”重新排列为“读取、读取...”和“修改、修改...”,会有助于减小重排和重绘的次数。但是这种刻意的、手动的级联写法是不安全的。
与此同时,常规的 JS 写法又很容易触发重排和重绘。
在减小重排和重绘的道路上,React 陷入了尴尬的处境。
En fin de compte, le contributeur de la communauté Ben Alpert a utilisé le traitement par lots pour sauver cette situation embarrassante.
Dans React, les développeurs indiquent à React que le composant actuel va changer en appelant la méthode setState du composant.
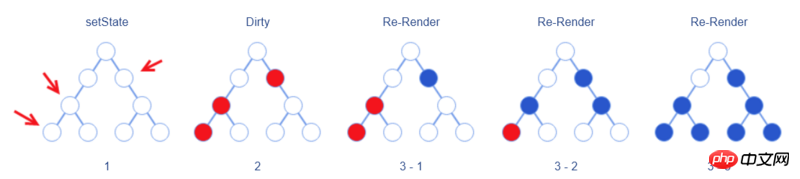
L'approche de Ben Alpert consiste à ne pas synchroniser les modifications apportées au DOM virtuel immédiatement lors de l'appel de setState, mais uniquement à marquer l'élément correspondant comme " en attente de la marque "Mise à jour". Si setState est appelé plusieurs fois dans le composant, la même opération de marquage sera effectuée.
Une fois l'événement d'initialisation complètement diffusé, le processus de re-rendu (Re-Render) de haut en bas commence. Cela garantit que React ne restitue l'élément qu'une seule fois.
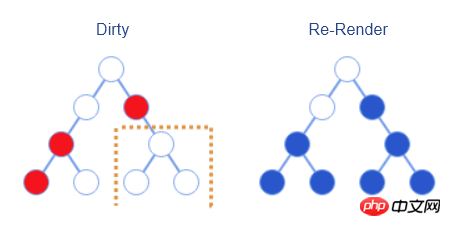
Deux points doivent être notés ici :
Le re-rendu ici fait référence à la synchronisation des
setStatemodifications avec le DOM virtuel seulement après que l'opération de comparaison soit effectuée ; pour générer les vrais changements DOM.Différent du "re-rendu de tout le DOM" mentionné ci-dessus, le vrai re-rendu ne restitue que l'élément marqué et ses sous-éléments, c'est-à-dire uniquement le bleu L'élément dans l'image ci-dessus est Les éléments représentés par des cercles colorés seront restitués
Cela rappelle également aux développeurs que doit conserver les composants avec état aussi près que possible des nœuds feuilles , ce qui peut réduire le nombre de nouveaux rendus.
Élagage
À mesure que l'application grandit, React gère de plus en plus d'états de composants, ce qui signifie que la portée du nouveau rendu deviendra également de plus en plus grande.
En observant attentivement le processus de traitement par lots ci-dessus, vous pouvez constater que les trois éléments dans le coin inférieur droit du DOM virtuel n'ont pas réellement changé, mais parce que le changement de leurs nœuds parents a également provoqué leur nouveau rendu, ça ne sert à rien de faire plus d'opération.
Pour cette situation, React lui-même a déjà pris cela en considération et fournit l'interface bool shouldComponentUpdate(nextProps, nextState) pour cela. Les développeurs peuvent implémenter manuellement cette interface pour comparer l'état et les propriétés avant et après afin de déterminer si un nouveau rendu est nécessaire. Dans ce cas, le nouveau rendu devient le processus illustré dans la figure ci-dessous.
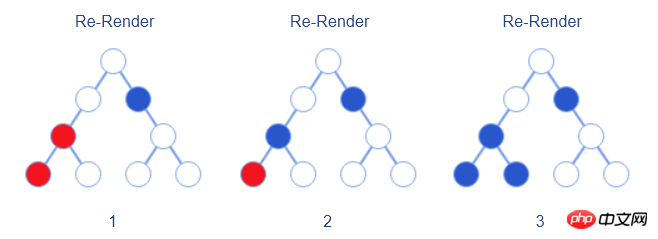
À cette époque, bien que React fournisse l'interface shouldComponentUpdate, il ne fournissait pas d'implémentation par défaut (les développeurs devaient toujours le faire). il faut le faire manuellement pour obtenir l’effet souhaité.
La raison est qu'en JS, nous utilisons généralement des objets pour enregistrer l'état, et lors de la modification de l'état, nous modifions directement l'objet d'état. En d’autres termes, deux états différents avant et après modification pointent vers le même objet, donc lorsqu’on compare directement si deux objets ont changé, ils sont identiques, même si l’état a changé.
À cet égard, David Nolen a proposé une solution basée sur une structure de données immuable.
Cette solution s'inspire de ClojureScript, où la plupart des valeurs sont immuables. En d'autres termes, lorsqu'une valeur doit être mise à jour, le programme ne modifie pas la valeur d'origine, mais crée une nouvelle valeur basée sur la valeur d'origine, puis utilise la nouvelle valeur pour l'affectation.
David a utilisé ClojureScript pour écrire une solution de structure de données immuable pour React : Om, qui fournit une implémentation par défaut pour shouldComponentUpdate.
Cependant, comme les structures de données immuables n'étaient pas largement acceptées par les ingénieurs Web, cette fonctionnalité n'a pas été intégrée à React à cette époque.
Malheureusement, pour l'instant, shouldComponentUpdate ne fournit toujours pas d'implémentation par défaut.
Mais David a ouvert une bonne direction de recherche pour les développeurs.
Si vous souhaitez vraiment utiliser des structures de données immuables pour améliorer les performances de React, vous pouvez vous référer à Facebook Immutable.js, qui est de la même école que React. C'est un bon partenaire de React !
Conclusion
L'optimisation de React se poursuit. Par exemple, la fibre est nouvellement introduite dans React 16. Il s'agit d'une reconstruction de l'algorithme de base, c'est-à-dire de la méthode et du timing de détection. les modifications sont repensées, permettant au processus de rendu d'être effectué par segments plutôt que d'un seul coup.
En raison du manque d'espace, cet article ne présentera pas la fibre en profondeur. Ceux qui sont intéressés peuvent se référer à Qu'est-ce que React Fiber.
Recommandations associées :
Explication détaillée du cycle de vie des composants React
Explication détaillée des composants contrôlés et des composants non contrôlés de React
Un exemple d'écriture d'un composant de pagination à l'aide de React
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Une analyse approfondie du composant de groupe de liste Bootstrap
- Explication détaillée du currying de la fonction JavaScript
- Exemple complet de génération de mot de passe JS et de détection de force (avec téléchargement du code source de démonstration)
- Angularjs intègre l'interface utilisateur WeChat (weui)
- Comment basculer rapidement entre le chinois traditionnel et le chinois simplifié avec JavaScript et l'astuce permettant aux sites Web de prendre en charge le basculement entre les compétences en chinois simplifié et traditionnel_javascript