
Maison >développement back-end >tutoriel php >Tests simples et partage d'utilisation de php-ml
Tests simples et partage d'utilisation de php-ml

- 小云云original
- 2018-02-07 10:24:272803parcourir
php-ml est une bibliothèque d'apprentissage automatique écrite en PHP. Bien que nous sachions que Python ou C++ fournissent davantage de bibliothèques d'apprentissage automatique, en fait, la plupart d'entre elles sont légèrement compliquées et la configuration rend de nombreux novices désespérés. Cet article vous apporte principalement une méthode simple de test et d'utilisation de la bibliothèque PHP de machine learning php-ml. L'éditeur le trouve plutôt bon, je vais donc le partager avec vous maintenant et le donner comme référence pour tout le monde. Suivons l'éditeur pour y jeter un œil, j'espère que cela pourra aider tout le monde.
Bien que la bibliothèque d'apprentissage automatique php-ml ne dispose pas d'algorithmes particulièrement avancés, elle possède les algorithmes d'apprentissage automatique, de classification et autres les plus élémentaires. Notre petite entreprise peut effectuer des analyses de données simples, des prédictions, etc. . Dans nos projets, nous devons rechercher la rentabilité et non une efficacité et une précision excessives. Certains algorithmes et bibliothèques semblent très puissants, mais si nous envisageons une mise en ligne rapide et que notre personnel technique n'a aucune expérience en apprentissage automatique, un code et une configuration complexes ralentiront en fait notre projet. Et si nous créons une application simple d'apprentissage automatique, alors le coût d'apprentissage pour l'étude de bibliothèques et d'algorithmes complexes est évidemment un peu élevé. De plus, si le projet rencontre des problèmes étranges, pouvons-nous les résoudre ? Que dois-je faire si mes besoins changent ? Je pense que tout le monde a vécu cette expérience : pendant que je travaillais, le programme a soudainement signalé une erreur, et je n'ai pas pu en comprendre la raison. J'ai cherché sur Google ou Baidu et j'ai trouvé une seule question qui remplissait les conditions. Elle a été posée cinq ou dix. il y a des années, puis aucune réponse. . .
Il est donc nécessaire de choisir la méthode la plus simple, la plus efficace et la plus rentable. La vitesse de php-ml n'est pas lente (passage rapide à php7), et la précision est également bonne. Après tout, les algorithmes sont les mêmes et php est basé sur c. Ce que les blogueurs n'aiment pas le plus, c'est comparer les performances et la portée des applications entre Python, Java et PHP. Si vous voulez vraiment des performances, veuillez développer en C. Si vous souhaitez vraiment approfondir le champ d'application, veuillez utiliser C ou même assembly. . .
Tout d'abord, si nous voulons utiliser cette bibliothèque, nous devons d'abord la télécharger. Ce fichier de bibliothèque peut être téléchargé depuis github (https://github.com/php-ai/php-ml). Bien entendu, il est plus recommandé d'utiliser composer pour télécharger la bibliothèque et la configurer automatiquement.
Après le téléchargement, nous pouvons jeter un œil à la documentation de cette bibliothèque. Les documents sont tous des exemples simples. Nous pouvons créer nous-mêmes un fichier et l'essayer. Tous sont faciles à comprendre. Ensuite, testons-le sur des données réelles. L'un des ensembles de données est l'ensemble de données sur les étamines d'Iris, et l'autre est dû à la perte d'enregistrements, donc je ne sais pas de quoi il s'agit. . .
Les données sur les étamines d'iris comportent trois catégories différentes :
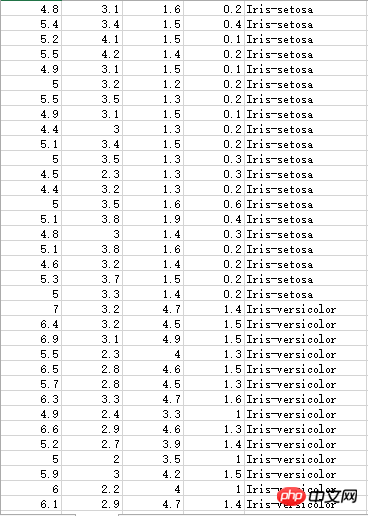
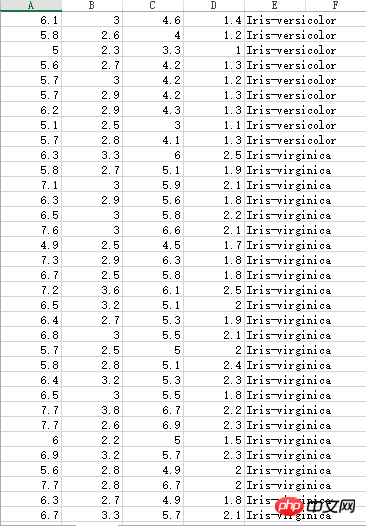
Ensemble de données inconnu, le point décimal est marqué comme une virgule, donc lors du calcul, il est toujours nécessaire à traiter :

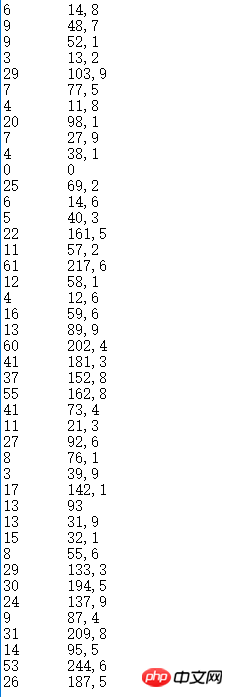
Traitons d'abord de l'ensemble de données inconnu. Premièrement, le nom de fichier de notre ensemble de données inconnu est data.txt. Cet ensemble de données peut d’abord être dessiné dans un graphique linéaire xy. Par conséquent, nous dessinons d’abord les données originales dans un graphique linéaire. Comme l'axe des x est relativement long, il suffit de voir sa forme approximative :
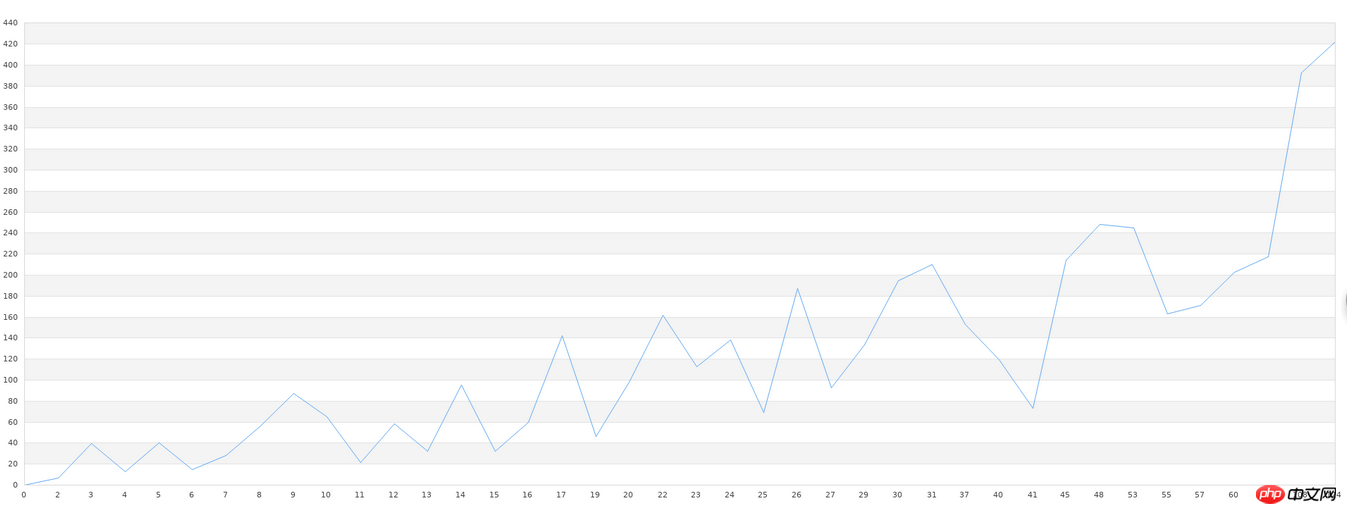
Drawing utilise la bibliothèque jpgraph de php, le code est le suivant :
<?php
include_once './src/jpgraph.php';
include_once './src/jpgraph_line.php';
$g = new Graph(1920,1080);//jpgraph的绘制操作
$g->SetScale("textint");
$g->title->Set('data');
//文件的处理
$file = fopen('data.txt','r');
$labels = array();
while(!feof($file)){
$data = explode(' ',fgets($file));
$data[1] = str_replace(',','.',$data[1]);//数据处理,将数据中的逗号修正为小数点
$labels[(int)$data[0]] = (float)$data[1];//这里将数据以键值的方式存入数组,方便我们根据键来排序
}
ksort($labels);//按键的大小排序
$x = array();//x轴的表示数据
$y = array();//y轴的表示数据
foreach($labels as $key=>$value){
array_push($x,$key);
array_push($y,$value);
}
$linePlot = new LinePlot($y);
$g->xaxis->SetTickLabels($x);
$linePlot->SetLegend('data');
$g->Add($linePlot);
$g->Stroke();
Maintenant que nous avons cette image originale à titre de comparaison, étudions ensuite. Nous utilisons LeastSquars en php-ml pour l'apprentissage. Le résultat de notre test doit être enregistré dans un fichier afin que nous puissions établir un tableau de comparaison. Le code d'apprentissage est le suivant :
<?php
require 'vendor/autoload.php';
use Phpml\Regression\LeastSquares;
use Phpml\ModelManager;
$file = fopen('data.txt','r');
$samples = array();
$labels = array();
$i = 0;
while(!feof($file)){
$data = explode(' ',fgets($file));
$samples[$i][0] = (int)$data[0];
$data[1] = str_replace(',','.',$data[1]);
$labels[$i] = (float)$data[1];
$i ++;
}
fclose($file);
$regression = new LeastSquares();
$regression->train($samples,$labels);
//这个a数组是根据我们对原数据处理后的x值给出的,做测试用。
$a = [0,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,20,22,23,24,25,26,27,29,30,31,37,40,41,45,48,53,55,57,60,61,108,124];
for($i = 0; $i < count($a); $i ++){
file_put_contents("putput.txt",($regression->predict([$a[$i]]))."\n",FILE_APPEND); //以追加的方式存入文件
}
Après cela, nous lisons les données stockées dans le fichier, dessinons un graphique et collons d'abord le rendu final :
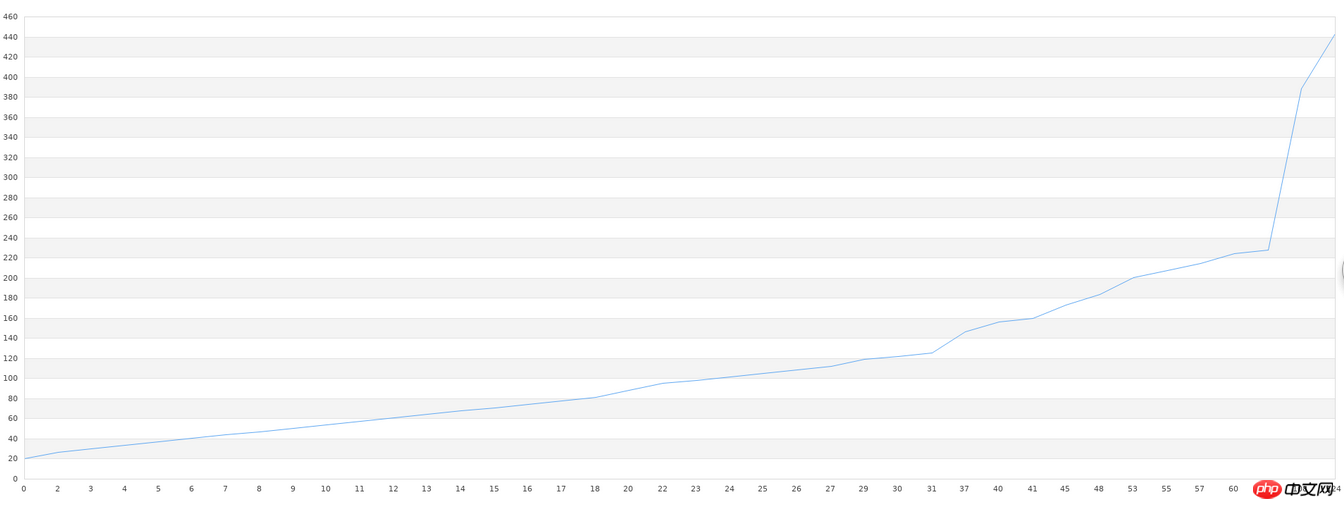
Le code est le suivant :
<?php
include_once './src/jpgraph.php';
include_once './src/jpgraph_line.php';
$g = new Graph(1920,1080);
$g->SetScale("textint");
$g->title->Set('data');
$file = fopen('putput.txt','r');
$y = array();
$i = 0;
while(!feof($file)){
$y[$i] = (float)(fgets($file));
$i ++;
}
$x = [0,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,20,22,23,24,25,26,27,29,30,31,37,40,41,45,48,53,55,57,60,61,108,124];
$linePlot = new LinePlot($y);
$g->xaxis->SetTickLabels($x);
$linePlot->SetLegend('data');
$g->Add($linePlot);
$g->Stroke();
On constate que l'écart graphique est encore relativement important, notamment dans les parties avec des graphismes plus irréguliers. Cependant, il s’agit après tout de 40 ensembles de données, et nous pouvons voir que les tendances graphiques générales sont cohérentes. Lorsque les bibliothèques générales effectuent ce type d’apprentissage, la précision est très faible lorsque la quantité de données est faible. Pour atteindre une précision relativement élevée, une grande quantité de données est nécessaire, et plus de 10 000 éléments de données sont nécessaires. Si cette exigence en matière de données ne peut être satisfaite, alors toute bibliothèque que nous utilisons sera vaine. Par conséquent, dans la pratique de l'apprentissage automatique, la vraie difficulté ne réside pas dans des problèmes techniques tels qu'une faible précision et une configuration complexe, mais dans un volume de données insuffisant ou dans une qualité trop faible (trop de données inutiles dans un ensemble de données). Avant de faire du machine learning, un prétraitement des données est également nécessaire.
Ensuite, testons les données sur les étamines. Il existe trois catégories au total Depuis que nous avons téléchargé des données CSV, nous pouvons utiliser la méthode officielle d'exploitation des fichiers CSV fournie par php-ml. Il s'agit d'un problème de classification, nous choisissons donc l'algorithme SVC fourni par la bibliothèque pour la classification. Nous nommons le fichier des données du pistil Iris.csv, et le code est le suivant :
<?php require 'vendor/autoload.php'; use Phpml\Classification\SVC; use Phpml\SupportVectorMachine\Kernel; use Phpml\Dataset\CsvDataset; $dataset = new CsvDataset('Iris.csv' , 4, false); $classifier = new SVC(Kernel::LINEAR,$cost = 1000); $classifier->train($dataset->getSamples(),$dataset->getTargets()); echo $classifier->predict([$argv[1],$argv[2],$argv[3],$argv[4]]);//$argv是命令行参数,调试这种程序使用命令行较方便
是不是很简单?短短12行代码就搞定了。接下来,我们来测试一下。根据我们上面贴出的图,当我们输入5 3.3 1.4 0.2的时候,输出应该是Iris-setosa。我们看一下:

看,至少我们输入一个原来就有的数据,得到了正确的结果。但是,我们输入原数据集中没有的数据呢?我们来测试两组:
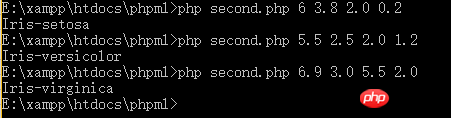
由我们之前贴出的两张图的数据看,我们输入的数据在数据集中并不存在,但分类按照我们初步的观察来看,是合理的。
所以,这个机器学习库对于大多数的人来说,都是够用的。而大多数鄙视这个库鄙视那个库,大谈性能的人,基本上也不是什么大牛。真正的大牛已经忙着捞钱去了,或者正在做学术研究等等。我们更多的应该是掌握算法,了解其中的道理和玄机,而不是夸夸其谈。当然,这个库并不建议用在大型项目上,只推荐小型项目或者个人项目等。
jpgraph只依赖GD库,所以下载引用之后就可以使用,大量的代码都放在了绘制图形和初期的数据处理上。由于库的出色封装,学习代码并不复杂。需要所有代码或者测试数据集的小伙伴可以留言或者私信等,我提供完整的代码,解压即用。
相关推荐:
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Tous les symboles d'expression dans les expressions régulières (résumé)