
Maison >développement back-end >tutoriel php >PHP génère du code Morse basé sur du texte
PHP génère du code Morse basé sur du texte

- *文original
- 2017-12-28 15:29:322218parcourir
Récemment rencontré le besoin de générer des fichiers audio en code Morse basés sur le texte saisi. Après quelques recherches infructueuses, j'ai décidé d'écrire mon propre générateur. Cet article présente principalement les informations pertinentes sur la mise en œuvre d'un générateur de code Morse basé sur du texte en PHP. Les amis dans le besoin peuvent s'y référer. J'espère que cela aide tout le monde.
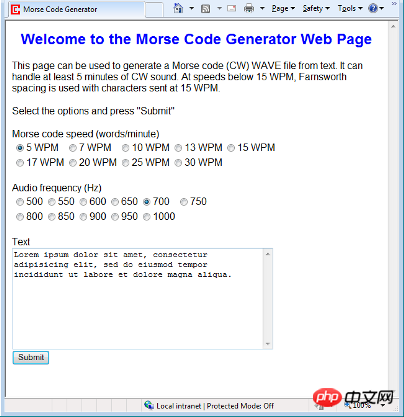
Parce que je souhaite accéder à mes fichiers audio en code Morse via le Web, j'ai décidé d'utiliser PHP comme langage de programmation principal. La capture d'écran ci-dessus montre une page Web commençant à générer du code Morse. Le fichier zip téléchargé contient une page Web pour soumettre du texte et un fichier source PHP pour générer et afficher des fichiers audio. Si vous souhaitez tester le code PHP, vous devez copier la page Web et les fichiers PHP associés sur un serveur compatible PHP.
Pour beaucoup de gens, le code Morse n'est qu'une séquence de « points » et de « tirets » ou une série de bips comme le montrent certains vieux films. Évidemment, ces connaissances ne suffisent pas si l’on souhaite utiliser du code informatique pour générer du code Morse. Cet article présentera les éléments de génération de code Morse, comment générer des fichiers audio au format WAVE et comment utiliser PHP pour convertir le code Morse en fichiers audio.
Code Morse
Le code Morse est une méthode d'encodage de texte. Son avantage est qu’il est facile à coder et peut être facilement décodé par l’oreille humaine. Essentiellement, l'audio (ou la fréquence radio) est activé et désactivé pour former des impulsions audio courtes ou longues, généralement appelées points et tirets, ou « points » et « tirets » dans la terminologie radio. En termes de communications numériques modernes, le code Morse est une forme de saisie par déplacement d'amplitude (ASK).
En code Morse, les caractères (lettres, chiffres, signes de ponctuation et symboles spéciaux) sont codés dans une séquence de « ticks » et de « dahs ». Ainsi, afin de convertir du texte en code Morse, nous devons d’abord déterminer comment représenter « tick » et « dah ». Un choix évident consiste à utiliser 0 pour « tick » et 1 pour « dah », ou vice versa. Malheureusement, le code Morse utilise un système de codage à longueur variable. Nous devons donc également utiliser une séquence de longueur variable ou adopter une méthode pour regrouper les données dans un format de taille fixe commun à la mémoire de l'ordinateur. De plus, il est important de noter que le code Morse ne fait pas de distinction entre les lettres majuscules et minuscules et ne peut pas coder certains symboles spéciaux. Dans notre implémentation, les caractères et symboles non définis seront ignorés.
Dans ce projet, l'utilisation de la mémoire n'est pas une considération particulière. Par conséquent, nous proposons un schéma de codage simple, c'est-à-dire utiliser « 0 » pour représenter chaque « tick » et « 1 » pour représenter chaque « dah », et les placer dans un tableau associatif de chaînes. Le code PHP qui définit la table d'encodage du code Morse est le suivant :
$CWCODE = array ('A'=>'01','B'=>'1000','C'=>'1010','D'=>'100','E'=>'0', 'F'=>'0010','G'=>'110','H'=>'0000','I'=>'00','J'=>'0111', 'K'=>'101','L'=>'0100','M'=>'11','N'=>'10', 'O'=>'111', 'P'=>'0110','Q'=>'1101','R'=>'010','S'=>'000','T'=>'1', 'U'=>'001','V'=>'0001','W'=>'011','X'=>'1001','Y'=>'1011', 'Z'=>'1100', '0'=>'11111','1'=>'01111','2'=>'00111', '3'=>'00011','4'=>'00001','5'=>'00000','6'=>'10000', '7'=>'11000','8'=>'11100','9'=>'11110','.'=>'010101', ','=>'110011','/'=>'10010','-'=>'10001','~'=>'01010', '?'=>'001100','@'=>'00101');
Il est à noter que si vous tenez particulièrement à En termes d'utilisation de la mémoire, le code ci-dessus peut être interprété comme des bits. En ajoutant un bit de départ à chaque code, un modèle de bits peut être formé et chaque caractère peut être stocké dans un octet. Dans le même temps, lors de l'analyse du codage final, les bits à gauche du bit de départ sont supprimés pour obtenir un véritable codage de longueur variable.
Bien que beaucoup de gens ne s'en rendent pas compte, « l'intervalle de temps » est en fait le principal facteur qui définit le code Morse, donc comprendre cela est essentiel pour générer du code Morse. Par conséquent, la première chose que nous devons faire est de définir l'intervalle de temps du code interne du code Morse (c'est-à-dire « tick » et « dah »). Par souci de commodité, nous définissons la durée d'un son « tick » comme une unité de temps dt, et l'intervalle entre « tick » et « dah » est également une unité de temps dt ; nous définissons la longueur d'un « dah » comme 3 ; dt, le caractère ( L'intervalle entre les lettres) est également de 3 dt ; l'intervalle entre les mots de définition (mots) est de 7 dt. Donc, pour résumer, notre tableau d'intervalles de temps ressemble à ceci :

En code Morse, la "vitesse de lecture" d'un son encodé est généralement exprimée en mots/minute ( WPM ) à représenter. Étant donné que les mots anglais ont des longueurs différentes et que les caractères ont un nombre de clics et de clics différent, la conversion de WPM en échantillons numériques (audio) n'est pas aussi simple qu'il y paraît. Dans un système adopté par les organisations internationales, 5 caractères sont utilisés comme longueur moyenne des mots, tandis qu'un chiffre ou un signe de ponctuation est traité comme 2 caractères. De cette façon, un mot moyen fait 50 unités de temps dt. De cette façon, si vous spécifiez WPM, alors notre temps de lecture total est de 50 * unité de temps WPM/minute, et la durée de chaque « tick » (c'est-à-dire une unité de temps dt) est égale à 1,2/WPM secondes. De cette façon, étant donné la durée d’un « tick », la durée des autres éléments peut être facilement calculée.
你可能已经注意到,在上面显示的网页中,对于低于15WPM的选项,我们使用了“Farnsworth spacing”。那么这个“Farnsworth spacing”又是个什么鬼?
当报务员学习用耳朵来解码莫斯代码的时候,他就会意识到,当播放速度变化的时候,字符出现的节奏也会跟着变化。当播放速度低于10WPM的时候,他能够从容的识别“嘀”和“嗒”,并且知道发送的哪个字符。但是当播放速度超过10WPM的时候,报务员的识别就会出错,他识别出来的字符会多于实际的“嘀”和“嗒”。当一个学习的时候习惯低速莫斯代码的人,在处理高速播放代码的时候,就会出现问题。因为节奏变了,他潜意识的识别就会出错。
为了解决这个问题,“Farnsworth spacing”就被发明出来了。本质上来讲,字母和符号的播放速度依然采取高于15WPM的速度,同时,通过在字符之间插入更多的空格,来使整体的播放速度降低。这样,报务员就能够以一个合理的速度和节奏来识别每个字符,一旦所有的字符都学习完毕,就可以增加速度,而接收员只需要加快识别字符的速度就可以了。本质上来说,“Farnsworth spacing”这个技巧解决了节奏变化这个问题,使接收员能够快速学习。
所以,在整个系统中,对于更低的播放速度,都统一成15WPM。相对应的,一个“嘀”的长度是0.08秒,但是字符之间和单词之间的间隔就不再是3个dit或者7个dit,而是进行的调整以适应整体速度。
生成声音
在PHP代码中,一个字符(即前面数组的索引)代表一组由“嘀”、“嗒”和空白间隔组成的莫斯声音。我们用数字采样来组成音频序列,并且将其写入到文件中,同时加上适当的头信息来将其定义成WAVE格式。
生成声音的代码其实相当简单,你可以在项目中PHP文件中找到它们。我发现定义一个“数字振荡器”相当方便。每调用一次osc(),它就会返回一个从正玄波产生的定时采样。运用声音采样和声频规范,生成WAVE格式的音频已经足够了。在产生的正玄波中的-1到+1之间是被移动和调整过的,这样声音的字节数据可以用0到255来表示,同时128表示零振幅。
同时,在生成声音方面我们还要考虑另外一个问题。一般来讲,我们是通过正玄波的开关来生成莫斯代码。但是你直接这样来做的话,就会发现你生成的信号会占用非常大的带宽。所以,通常无线电设备会对其加以修正,以减少带宽占用。
在我们的项目中,也会做这样的修正,只不过是用数字的方式。既然我们已经知道了一个最小声音样本“嘀”的时间长度,那么,可以证明,最小带宽的声幅发生在长度等于“嘀”的正玄波半周期。事实上,我们使用低通滤波器(low pass filter)来过滤音频信号也能达到同样的效果。不过,既然我们已经知道所有的信号字符,我们直接简单的过滤一下每一个字符信号就可以了。
生成“嘀”、“嗒”和空白信号的PHP代码就像下面这样:
while ($dt < $DitTime) {
$x = Osc();
if ($dt < (0.5*$DitTime)) {
// Generate the rising part of a dit and dah up to half the dit-time
$x = $x*sin((M_PI/2.0)*$dt/(0.5*$DitTime));
$ditstr .= chr(floor(120*$x+128));
$dahstr .= chr(floor(120*$x+128));
}
else if ($dt > (0.5*$DitTime)) {
// For a dah, the second part of the dit-time is constant amplitude
$dahstr .= chr(floor(120*$x+128));
// For a dit, the second half decays with a sine shape
$x = $x*sin((M_PI/2.0)*($DitTime-$dt)/(0.5*$DitTime));
$ditstr .= chr(floor(120*$x+128));
}
else {
$ditstr .= chr(floor(120*$x+128));
$dahstr .= chr(floor(120*$x+128));
}
// a space has an amplitude of 0 shifted to 128
$spcstr .= chr(128);
$dt += $sampleDT;
}
// At this point the dit sound has been generated
// For another dit-time unit the dah sound has a constant amplitude
$dt = 0;
while ($dt < $DitTime) {
$x = Osc();
$dahstr .= chr(floor(120*$x+128));
$dt += $sampleDT;
}
// Finally during the 3rd dit-time, the dah sound must be completed
// and decay during the final half dit-time
$dt = 0;
while ($dt < $DitTime) {
$x = Osc();
if ($dt > (0.5*$DitTime)) {
$x = $x*sin((M_PI/2.0)*($DitTime-$dt)/(0.5*$DitTime));
$dahstr .= chr(floor(120*$x+128));
}
else {
$dahstr .= chr(floor(120*$x+128));
}
$dt += $sampleDT;
}WAVE格式的文件
WAVE是一种通用的音频格式。从最简单的形式来看,WAVE文件通过在头部包含一个整数序列来表示指定采样率的音频振幅。关于WAVE文件的详细信息请查看这里Audio File Format Specifications website。对于产生莫斯代码,我们并不需要用到WAVE格式的所有参数选项,仅仅需要一个8位的单声道就可以了,所以,so easy。需要注意的是,多字节数据需要采用低位优先(little-endian)的字节顺序。WAVE文件使用一种由叫做“块(chunks)”的记录组成的RIFF格式。
WAVE文件由一个ASCII标识符RIFF开始,紧跟着一个4字节的“块”,然后是一个包含ASCII字符WAVE的头信息,最后是定义格式的数据和声音数据。
在我们的程序中,第一个“块”包含了一个格式说明符,它由ASCII字符fmt和一个4倍字节的“块”。在这里,由于我使用的是普通脉冲编码调制(plain vanilla PCM)格式,所以每个“块”都是16字节。然后,我们还需要这些数据:声道数、声音采样/秒、平均字节/秒、一个区块(block)对齐指示器、位(bit)/声音采样。另外,由于我们不需要高质量立体声,我们只采用单声道,我们使用 11050采样/秒(标准的CD质量音频的采样率是 44200采样/秒)的采样率来生成声音,并且用8位(bit)保存。
最后,真实的音频数据储存在接下来的“块”中。其中包含ASCII字符data,一个4字节的“块”,最后是由字节序列(因为我们采用的是8位(bit)/采样)组成的真实音频数据。
在程序中,由8位音频振幅序列组成的声音保存在变量$soundstr中。一旦音频数据生成完毕,就可以计算出所有的“块”大小,然后就可以把它们合并在一起写入磁盘文件中。下面的代码展示了如何生成头信息和音频“块”。需要注意的是,$riffstr表示RIFF头,$fmtstr表示“块”格式,$soundstr表示音频数据“块”。
$riffstr = 'RIFF'.$NSizeStr.'WAVE';
$x = SAMPLERATE;
$SampRateStr = '';
for ($i=0; $i<4; $i++) {
$SampRateStr .= chr($x % 256);
$x = floor($x/256);
}
$fmtstr = 'fmt '.chr(16).chr(0).chr(0).chr(0).chr(1).chr(0).chr(1).chr(0)
.$SampRateStr.$SampRateStr.chr(1).chr(0).chr(8).chr(0);
$x = $n;
$NSampStr = '';
for ($i=0; $i<4; $i++) {
$NSampStr .= chr($x % 256);
$x = floor($x/256);
}
$soundstr = 'data'.$NSampStr.$soundstr;总结和评论
我们的文本莫斯代码生成器目前看起来还不错。当然,我们还可以对它做很多的修改和完善,比如使用其他字符集、直接从文件中读取文本、生成压缩音频等等。因为我们这个项目的目的是使其能够在网络上方便的使用,所以我们这个简单的方案,已经达到我们的目的了。
相关推荐:
PHP实现迪菲赫尔曼密钥交换(Diffie–Hellman)算法
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Tous les symboles d'expression dans les expressions régulières (résumé)