
Maison >développement back-end >Tutoriel Python >Une brève introduction à Python NLP
Une brève introduction à Python NLP

- 小云云original
- 2017-12-26 09:16:242568parcourir
Cet article présente principalement le tutoriel d'introduction à Python NLP, au traitement du langage naturel (NLP) Python et à l'utilisation de la bibliothèque NLTK de Python. NLTK est la boîte à outils de traitement du langage naturel de Python. Il s'agit de la bibliothèque Python la plus couramment utilisée dans le domaine du PNL. L’éditeur le trouve plutôt bien, alors j’aimerais le partager avec vous maintenant et le donner comme référence pour tout le monde. Suivons l'éditeur pour y jeter un œil, j'espère que cela pourra aider tout le monde.
Qu'est-ce que la PNL ?
En termes simples, le traitement du langage naturel (NLP) est le développement d'applications ou de services capables de comprendre le langage humain.
Voici quelques exemples d'applications pratiques du traitement du langage naturel (NLP), tels que la reconnaissance vocale, la traduction vocale, la compréhension de phrases complètes, la compréhension des synonymes de mots correspondants et la génération de phrases et de paragraphes complets grammaticalement corrects.
Ce n’est pas tout ce que la PNL peut faire.
Mise en œuvre du NLP
Moteurs de recherche : tels que Google, Yahoo, etc. Le moteur de recherche Google sait que vous êtes un passionné de technologie, il affiche donc des résultats liés à la technologie
Flux social : comme le fil d'actualité Facebook ; Si l'algorithme du fil d'actualité sait que vos intérêts sont le traitement du langage naturel, il affichera des publicités et des publications pertinentes.
Moteur vocal : comme Siri d’Apple.
Filtrage anti-spam : tel que le filtre anti-spam de Google. Différent du filtrage anti-spam ordinaire, il détermine si un e-mail est du spam en comprenant la signification profonde du contenu de l'e-mail.
Bibliothèque NLP
Voici quelques bibliothèques de traitement du langage naturel (NLP) open source :
Boîte à outils en langage naturel ( NLTK );
Apache OpenNLP;
Suite Stanford NLP;
Bibliothèque Gate NLP
Parmi eux, le Natural Language Toolkit (NLTK) est la bibliothèque de traitement du langage naturel (NLP) la plus populaire. Elle est écrite en Python et bénéficie d'un très fort soutien communautaire.
NLTK est également facile à utiliser, en fait, il s'agit de la bibliothèque de traitement du langage naturel (NLP) la plus simple.
Dans ce tutoriel NLP, nous utiliserons la bibliothèque Python NLTK.
Installer NLTK
Si vous utilisez Windows/Linux/Mac, vous pouvez utiliser pip pour installer NLTK :
pip install nltk
Ouvrez le terminal python et importez NLTK pour vérifier si NLTK est correctement installé :
import nltk
Si tout se passe bien, il signifie que vous avez installé la bibliothèque NLTK avec succès. Après avoir installé NLTK pour la première fois, vous devez installer le package d'extension NLTK en exécutant le code suivant :
import nltk nltk.download()
Cela fera apparaître le téléchargement de NLTK. fenêtre pour sélectionner les packages à installer :
Vous pouvez installer tous les packages sans aucun problème car ils sont de petite taille.
Utilisation de Python Tokenize text
Tout d'abord, nous allons explorer le contenu d'une page Web, puis analyser le texte pour comprendre le contenu de la page.
Nous utiliserons le module urllib pour explorer les pages Web :
import urllib.request response = urllib.request.urlopen('http://php.net/') html = response.read() print (html)
Comme vous pouvez le voir sur les résultats imprimés, les résultats contiennent beaucoup ont besoin de balises HTML propres.
Ensuite, le module BeautifulSoup nettoie le texte comme ceci :
from bs4 import BeautifulSoup import urllib.request response = urllib.request.urlopen('http://php.net/') html = response.read() soup = BeautifulSoup(html,"html5lib") # 这需要安装html5lib模块 text = soup.get_text(strip=True) print (text)
Maintenant, nous obtenons un texte propre.
Étape suivante, convertissez le texte en jetons, comme ceci :
from bs4 import BeautifulSoup import urllib.request response = urllib.request.urlopen('http://php.net/') html = response.read() soup = BeautifulSoup(html,"html5lib") text = soup.get_text(strip=True) tokens = text.split() print (tokens)
Compter la fréquence des mots
Le texte a été traité. Utilisez maintenant Python NLTK pour compter la distribution de fréquence des jetons.
peut être obtenu en appelant la méthode FreqDist() dans NLTK :
from bs4 import BeautifulSoup import urllib.request import nltk response = urllib.request.urlopen('http://php.net/') html = response.read() soup = BeautifulSoup(html,"html5lib") text = soup.get_text(strip=True) tokens = text.split() freq = nltk.FreqDist(tokens) for key,val in freq.items(): print (str(key) + ':' + str(val))
Si vous recherchez les résultats de sortie, vous pouvez trouver les jetons les plus courants sont PHP.
Vous pouvez appeler la fonction plot pour créer un graphique de distribution de fréquence :
freq.plot(20, cumulative=False) # 需要安装matplotlib库
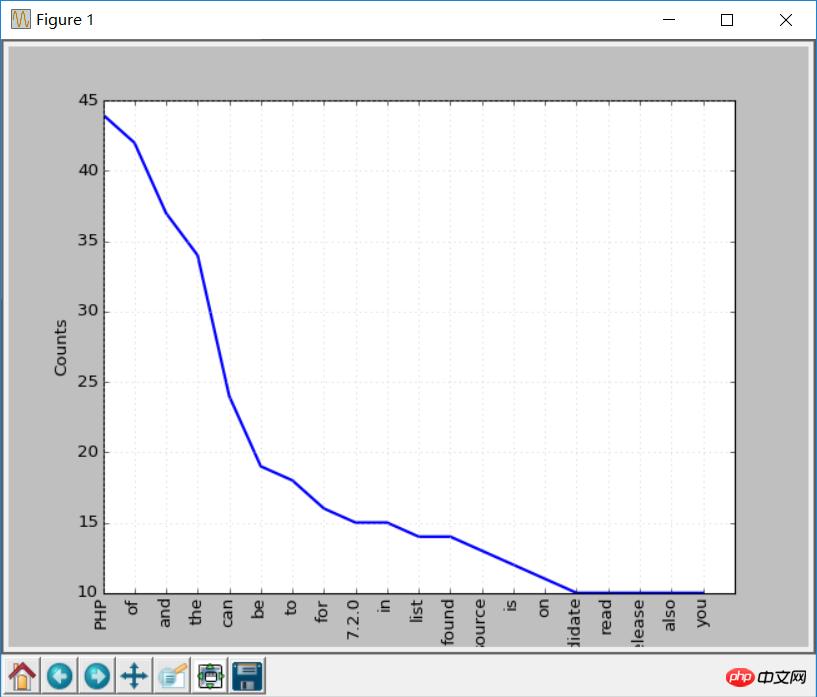
Ces mots ci-dessus. Par exemple, of, a, an, etc., ces mots sont des mots vides.
En général, les mots vides doivent être supprimés pour éviter qu'ils n'affectent les résultats de l'analyse.
Gestion des mots vides
NLTK est livré avec des listes de mots vides dans de nombreuses langues. Si vous obtenez des mots vides en anglais :
from nltk.corpus import stopwords stopwords.words('english')
Maintenant, modifiez le code pour effacer certains jetons invalides avant de dessiner :
clean_tokens = list()
sr = stopwords.words('english')
for token in tokens:
if token not in sr:
clean_tokens.append(token) Le code final devrait ressembler à ceci :
from bs4 import BeautifulSoup
import urllib.request
import nltk
from nltk.corpus import stopwords
response = urllib.request.urlopen('http://php.net/')
html = response.read()
soup = BeautifulSoup(html,"html5lib")
text = soup.get_text(strip=True)
tokens = text.split()
clean_tokens = list()
sr = stopwords.words('english')
for token in tokens:
if not token in sr:
clean_tokens.append(token)
freq = nltk.FreqDist(clean_tokens)
for key,val in freq.items():
print (str(key) + ':' + str(val)) Maintenant, refaites le tableau de fréquence des mots, l'effet sera meilleur qu'avant, car les mots vides ont été éliminés :
freq.plot(20,cumulative=False)
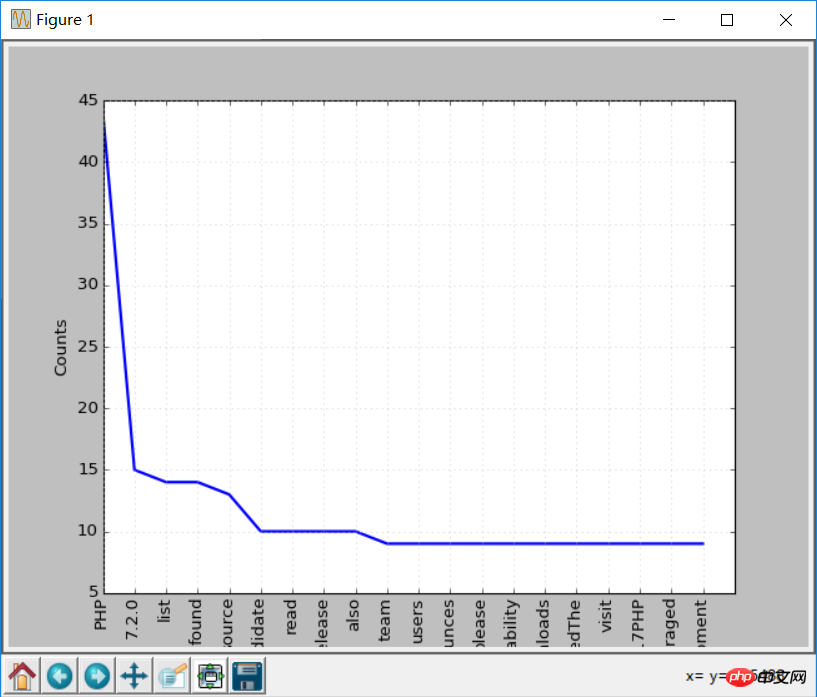
Utilisation du texte NLTK Tokenize
Avant d'utiliser la méthode split divise le texte en jetons. Nous utilisons maintenant NLTK pour tokeniser le texte.
Le texte ne peut pas être traité sans tokenisation, il est donc très important de tokeniser le texte. Le processus de tokenisation consiste à diviser de grandes parties en parties plus petites.
你可以将段落tokenize成句子,将句子tokenize成单个词,NLTK分别提供了句子tokenizer和单词tokenizer。
假如有这样这段文本:
Hello Adam, how are you? I hope everything is going well. Today is a good day, see you dude.
使用句子tokenizer将文本tokenize成句子:
from nltk.tokenize import sent_tokenize mytext = "Hello Adam, how are you? I hope everything is going well. Today is a good day, see you dude." print(sent_tokenize(mytext))
输出如下:
['Hello Adam, how are you?', 'I hope everything is going well.', 'Today is a good day, see you dude.']
这是你可能会想,这也太简单了,不需要使用NLTK的tokenizer都可以,直接使用正则表达式来拆分句子就行,因为每个句子都有标点和空格。
那么再来看下面的文本:
Hello Mr. Adam, how are you? I hope everything is going well. Today is a good day, see you dude.
这样如果使用标点符号拆分,Hello Mr将会被认为是一个句子,如果使用NLTK:
from nltk.tokenize import sent_tokenize mytext = "Hello Mr. Adam, how are you? I hope everything is going well. Today is a good day, see you dude." print(sent_tokenize(mytext))
输出如下:
['Hello Mr. Adam, how are you?', 'I hope everything is going well.', 'Today is a good day, see you dude.']
这才是正确的拆分。
接下来试试单词tokenizer:
from nltk.tokenize import word_tokenize mytext = "Hello Mr. Adam, how are you? I hope everything is going well. Today is a good day, see you dude." print(word_tokenize(mytext))
输出如下:
['Hello', 'Mr.', 'Adam', ',', 'how', 'are', 'you', '?', 'I', 'hope', 'everything', 'is', 'going', 'well', '.', 'Today', 'is', 'a', 'good', 'day', ',', 'see', 'you', 'dude', '.']
Mr.这个词也没有被分开。NLTK使用的是punkt模块的PunktSentenceTokenizer,它是NLTK.tokenize的一部分。而且这个tokenizer经过训练,可以适用于多种语言。
非英文Tokenize
Tokenize时可以指定语言:
from nltk.tokenize import sent_tokenize mytext = "Bonjour M. Adam, comment allez-vous? J'espère que tout va bien. Aujourd'hui est un bon jour." print(sent_tokenize(mytext,"french"))
输出结果如下:
['Bonjour M. Adam, comment allez-vous?', "J'espère que tout va bien.", "Aujourd'hui est un bon jour."]
同义词处理
使用nltk.download()安装界面,其中一个包是WordNet。
WordNet是一个为自然语言处理而建立的数据库。它包括一些同义词组和一些简短的定义。
您可以这样获取某个给定单词的定义和示例:
from nltk.corpus import wordnet
syn = wordnet.synsets("pain")
print(syn[0].definition())
print(syn[0].examples())输出结果是:
a symptom of some physical hurt or disorder
['the patient developed severe pain and distension']
WordNet包含了很多定义:
from nltk.corpus import wordnet
syn = wordnet.synsets("NLP")
print(syn[0].definition())
syn = wordnet.synsets("Python")
print(syn[0].definition())结果如下:
the branch of information science that deals with natural language information
large Old World boas
可以像这样使用WordNet来获取同义词:
from nltk.corpus import wordnet
synonyms = []
for syn in wordnet.synsets('Computer'):
for lemma in syn.lemmas():
synonyms.append(lemma.name())
print(synonyms)输出:
['computer', 'computing_machine', 'computing_device', 'data_processor', 'electronic_computer', 'information_processing_system', 'calculator', 'reckoner', 'figurer', 'estimator', 'computer']
反义词处理
也可以用同样的方法得到反义词:
from nltk.corpus import wordnet
antonyms = []
for syn in wordnet.synsets("small"):
for l in syn.lemmas():
if l.antonyms():
antonyms.append(l.antonyms()[0].name())
print(antonyms)输出:
['large', 'big', 'big']
词干提取
语言形态学和信息检索里,词干提取是去除词缀得到词根的过程,例如working的词干为work。
搜索引擎在索引页面时就会使用这种技术,所以很多人为相同的单词写出不同的版本。
有很多种算法可以避免这种情况,最常见的是波特词干算法。NLTK有一个名为PorterStemmer的类,就是这个算法的实现:
from nltk.stem import PorterStemmer stemmer = PorterStemmer() print(stemmer.stem('working')) print(stemmer.stem('worked'))
输出结果是:
work
work
还有其他的一些词干提取算法,比如 Lancaster词干算法。
非英文词干提取
除了英文之外,SnowballStemmer还支持13种语言。
支持的语言:
from nltk.stem import SnowballStemmer print(SnowballStemmer.languages) 'danish', 'dutch', 'english', 'finnish', 'french', 'german', 'hungarian', 'italian', 'norwegian', 'porter', 'portuguese', 'romanian', 'russian', 'spanish', 'swedish'
你可以使用SnowballStemmer类的stem函数来提取像这样的非英文单词:
from nltk.stem import SnowballStemmer
french_stemmer = SnowballStemmer('french')
print(french_stemmer.stem("French word"))单词变体还原
单词变体还原类似于词干,但不同的是,变体还原的结果是一个真实的单词。不同于词干,当你试图提取某些词时,它会产生类似的词:
from nltk.stem import PorterStemmer stemmer = PorterStemmer() print(stemmer.stem('increases'))
结果:
increas
现在,如果用NLTK的WordNet来对同一个单词进行变体还原,才是正确的结果:
from nltk.stem import WordNetLemmatizer lemmatizer = WordNetLemmatizer() print(lemmatizer.lemmatize('increases'))
结果:
increase
结果可能会是一个同义词或同一个意思的不同单词。
有时候将一个单词做变体还原时,总是得到相同的词。
这是因为语言的默认部分是名词。要得到动词,可以这样指定:
from nltk.stem import WordNetLemmatizer lemmatizer = WordNetLemmatizer() print(lemmatizer.lemmatize('playing', pos="v"))
结果:
play
实际上,这也是一种很好的文本压缩方式,最终得到文本只有原先的50%到60%。
结果还可以是动词(v)、名词(n)、形容词(a)或副词(r):
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
print(lemmatizer.lemmatize('playing', pos="v"))
print(lemmatizer.lemmatize('playing', pos="n"))
print(lemmatizer.lemmatize('playing', pos="a"))
print(lemmatizer.lemmatize('playing', pos="r"))输出:
play
playing
playing
playing
词干和变体的区别
通过下面例子来观察:
from nltk.stem import WordNetLemmatizer from nltk.stem import PorterStemmer stemmer = PorterStemmer() lemmatizer = WordNetLemmatizer() print(stemmer.stem('stones')) print(stemmer.stem('speaking')) print(stemmer.stem('bedroom')) print(stemmer.stem('jokes')) print(stemmer.stem('lisa')) print(stemmer.stem('purple')) print('----------------------') print(lemmatizer.lemmatize('stones')) print(lemmatizer.lemmatize('speaking')) print(lemmatizer.lemmatize('bedroom')) print(lemmatizer.lemmatize('jokes')) print(lemmatizer.lemmatize('lisa')) print(lemmatizer.lemmatize('purple'))
输出:
stone
speak
bedroom
joke
lisa
purpl
---------------------
stone
speaking
bedroom
joke
lisa
purple
词干提取不会考虑语境,这也是为什么词干提取比变体还原快且准确度低的原因。
个人认为,变体还原比词干提取更好。单词变体还原返回一个真实的单词,即使它不是同一个单词,也是同义词,但至少它是一个真实存在的单词。
如果你只关心速度,不在意准确度,这时你可以选用词干提取。
在此NLP教程中讨论的所有步骤都只是文本预处理。在以后的文章中,将会使用Python NLTK来实现文本分析。
相关推荐:
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!