
Maison >base de données >tutoriel mysql >Explication détaillée des transactions Mysql et du traitement de la cohérence des données
Explication détaillée des transactions Mysql et du traitement de la cohérence des données

- 小云云original
- 2017-12-18 15:39:251758parcourir
Dans cet article, nous partagerons avec vous une explication détaillée des transactions Mysql et du traitement de la cohérence des données. Au travail, nous rencontrons souvent de tels problèmes. Lorsque nous interrogeons l'inventaire disponible et nous préparons à le modifier, d'autres utilisateurs peuvent avoir modifié les données d'inventaire. En conséquence, les données d'inventaire que nous interrogeons auront des problèmes. les données. Examinons les solutions ci-dessous.
Dans InnoDB de MySQL, le niveau d'isolement Tansaction par défaut est REPEATABLE READ (lisible)
Si vous souhaitez METTRE À JOUR le même formulaire après SELECT, il est préférable d'utiliser SELECT ... UPDATE.
Par exemple :
Supposons qu'il y ait une quantité dans le formulaire de produits pour stocker la quantité de marchandises. Avant d'établir la commande, il faut déterminer si la quantité de marchandises est suffisante (. quantité>0), puis la quantité est La quantité est mise à jour à 1. Le code est le suivant :
SELECT quantity FROM products WHERE id=3; UPDATE products SET quantity = 1 WHERE id=3;
Pourquoi est-ce dangereux ?
Il se peut qu'il n'y ait pas de problème dans un petit nombre de cas, mais une grande quantité d'accès aux données sera "certainement" causer des problèmes. Si nous devons déduire l'inventaire lorsque la quantité est > 0, supposons que la quantité lue par le programme dans la première ligne SELECT est 2. Il semble que le nombre soit correct, mais lorsque MySQL se prépare à UPDATE, quelqu'un a peut-être déjà déduit l'inventaire. . Il est devenu 0, mais le programme ne le savait pas et a continué la MISE À JOUR qui était erronée. Par conséquent, un mécanisme de transaction doit être utilisé pour garantir que les données lues et soumises sont correctes.
Nous pouvons donc le tester comme ceci dans MySQL. Le code est le suivant :
SET AUTOCOMMIT=0; BEGIN WORK; SELECT quantity FROM products WHERE id=3 FOR UPDATE;
À ce stade, les données avec id=3 dans les données des produits sont verrouillées (Note 3). ), et les autres transactions doivent attendre cela
SELECT * FROM products WHERE id=3 FOR UPDATE
ne peuvent être exécutées qu'après la soumission de la transaction. Cela garantit que les nombres lus par quantité dans les autres transactions sont corrects.
UPDATE products SET quantity = '1' WHERE id=3 ; COMMIT WORK;
Le commit est écrit dans la base de données et les produits sont déverrouillés.
Remarque 1 : BEGIN/COMMIT est le point de début et de fin de la transaction. Vous pouvez utiliser plus de deux fenêtres de commande MySQL pour observer de manière interactive l'état de verrouillage.
Remarque 2 : Pendant la transaction, seuls SELECT ... FOR UPDATE ou LOCK IN SHARE MODE avec les mêmes données attendront la fin des autres transactions avant de s'exécuter. Généralement, SELECT... ne sera pas affecté par cela.
Remarque 3 : étant donné qu'InnoDB utilise par défaut le verrouillage au niveau des lignes, veuillez vous référer à cet article pour le verrouillage des colonnes de données.
Remarque 4 : essayez de ne pas utiliser la commande LOCK TABLES dans les formulaires InnoDB. Si vous devez l'utiliser, veuillez d'abord lire les instructions officielles sur l'utilisation de LOCK TABLES dans InnoDB pour éviter les blocages fréquents dans le système.
Utilisation plus avancée
Si nous devons d'abord interroger puis mettre à jour les données, il est préférable d'utiliser l'instruction comme celle-ci :
UPDATE products SET quantity = '1' WHERE id=3 AND quantity > 0;
De cette façon, il n'est pas nécessaire d'ajouter des éléments à gérer.
mysql gère une concurrence élevée et empêche la survente des stocks
J'ai vu un très bon article et je le transmets par la présente pour en savoir plus.
Aujourd'hui, M. Wang nous a donné une autre leçon. En fait, M. Wang a déjà mentionné le problème de MySQL gérant une concurrence élevée et empêchant les stocks survendus l'année dernière, mais c'est dommage que même si tout le monde a écouté à l'époque ; Je comprends, mais dans le développement réel, je n'ai toujours pas conscience de cet aspect. Aujourd'hui, je vais mettre au clair une partie de ma compréhension sur cette question et j'espère qu'il y aura davantage de cours comme celui-ci à l'avenir.
Tout d'abord, décrivons le problème de la survente des stocks : en général, les sites de commerce électronique seront confrontés à des activités telles que les achats groupés, les ventes flash et les offres spéciales. Une caractéristique commune de ces activités est une augmentation des visites et des ventes en ligne. ventes. Des milliers, voire des dizaines de milliers de personnes se précipitent pour acheter un produit. Cependant, en tant que produit actif, les stocks sont définitivement très limités. Comment contrôler les stocks pour éviter les surachats et les pertes inutiles est un casse-tête pour de nombreux programmeurs de sites de commerce électronique. C'est aussi le problème le plus fondamental.
D'un point de vue technique, beaucoup de gens penseront certainement aux transactions, mais les transactions sont une condition nécessaire pour contrôler les stocks survendus, mais ce n'est pas une condition nécessaire et suffisante.
Exemple :
Inventaire total : 4 articles
Demandeur : a, 1 article b, 2 articles c, 3 articles
Le programme est le suivant :
beginTranse(开启事务)
try{
$result = $dbca->query('select amount from s_store where postID = 12345');
if(result->amount > 0){
//quantity为请求减掉的库存数量
$dbca->query('update s_store set amount = amount - quantity where postID = 12345');
}
}catch($e Exception){
rollBack(回滚)
}
commit(提交事务)
Le code ci-dessus est le code que nous écrivons habituellement pour contrôler l'inventaire. La plupart des gens l'écriront comme ça. Il semble qu'il n'y ait pas de gros problème, mais en fait il cache d'énormes failles. L'accès à la base de données est en fait un accès aux fichiers du disque. Les tables de la base de données sont en fait des fichiers enregistrés sur le disque, et même un fichier contient plusieurs tables. Par exemple, en raison d'une concurrence élevée, trois utilisateurs a, b et c ont actuellement saisi cette transaction. À ce moment, un verrou partagé sera généré, donc lors de la sélection, les quantités d'inventaire trouvées par ces trois utilisateurs sont toutes de 4. , et notez également que les résultats trouvés par mysql innodb sont contrôlés par la version avant que les autres utilisateurs ne mettent à jour et ne valident (c'est-à-dire avant qu'une nouvelle version ne soit générée), les résultats trouvés par l'utilisateur actuel sont toujours la même version
Ensuite, mettez à jour, si ces trois utilisateurs arrivent à la mise à jour en même temps, l'instruction de mise à jour sérialisera la concurrence à ce moment-là, c'est-à-dire triera les trois utilisateurs qui arrivent en même temps, les exécutera un par un et générera des Verrouillage, avant que l'instruction de mise à jour actuelle ne soit validée, les autres utilisateurs attendent l'exécution. Après la validation, une nouvelle version est générée après l'exécution, l'inventaire doit être négatif. Mais selon la description ci-dessus, si l'on modifie le code, le phénomène de surachat ne se produira pas. Le code est le suivant :beginTranse(开启事务)
try{
//quantity为请求减掉的库存数量
$dbca->query('update s_store set amount = amount - quantity where postID = 12345');
$result = $dbca->query('select amount from s_store where postID = 12345');
if(result->amount < 0){
throw new Exception('库存不足');
}
}catch($e Exception){
rollBack(回滚)
}
commit(提交事务)De plus, une méthode plus concise : .
beginTranse(开启事务)
try{
//quantity为请求减掉的库存数量
$dbca->query('update s_store set amount = amount - quantity where amount>=quantity and postID = 12345');
}catch($e Exception){
rollBack(回滚)
}
commit(提交事务)
=====================================================================================
1、在秒杀的情况下,肯定不能如此高频率的去读写数据库,会严重造成性能问题的
必须使用缓存,将需要秒杀的商品放入缓存中,并使用锁来处理其并发情况。当接到用户秒杀提交订单的情况下,先将商品数量递减(加锁/解锁)后再进行其他方面的处理,处理失败在将数据递增1(加锁/解锁),否则表示交易成功。
当商品数量递减到0时,表示商品秒杀完毕,拒绝其他用户的请求。
2、这个肯定不能直接操作数据库的,会挂的。直接读库写库对数据库压力太大,要用缓存。
把你要卖出的商品比如10个商品放到缓存中;然后在memcache里设置一个计数器来记录请求数,这个请求书你可以以你要秒杀卖出的商品数为基数,比如你想卖出10个商品,只允许100个请求进来。那当计数器达到100的时候,后面进来的就显示秒杀结束,这样可以减轻你的服务器的压力。然后根据这100个请求,先付款的先得后付款的提示商品以秒杀完。
3、首先,多用户并发修改同一条记录时,肯定是后提交的用户将覆盖掉前者提交的结果了。
这个直接可以使用加锁机制去解决,乐观锁或者悲观锁。乐观锁:,就是在数据库设计一个版本号的字段,每次修改都使其+1,这样在提交时比对提交前的版本号就知道是不是并发提交了,但是有个缺点就是只能是应用中控制,如果有跨应用修改同一条数据乐观锁就没办法了,这个时候可以考虑悲观锁。
悲观锁:,就是直接在数据库层面将数据锁死,类似于oralce中使用select xxxxx from xxxx where xx=xx for update,这样其他线程将无法提交数据。
除了加锁的方式也可以使用接收锁定的方式,思路是在数据库中设计一个状态标识位,用户在对数据进行修改前,将状态标识位标识为正在编辑的状态,这样其他用户要编辑此条记录时系统将发现有其他用户正在编辑,则拒绝其编辑的请求,类似于你在操作系统中某文件正在执行,然后你要修改该文件时,系统会提醒你该文件不可编辑或删除。
4、不建议在数据库层面加锁,建议通过服务端的内存锁(锁主键)。当某个用户要修改某个id的数据时,把要修改的id存入memcache,若其他用户触发修改此id的数据时,读到memcache有这个id的值时,就阻止那个用户修改。
5、实际应用中,并不是让mysql去直面大并发读写,会借助“外力”,比如缓存、利用主从库实现读写分离、分表、使用队列写入等方法来降低并发读写。
悲观锁和乐观锁
首先,多用户并发修改同一条记录时,肯定是后提交的用户将覆盖掉前者提交的结果了。这个直接可以使用加锁机制去解决,乐观锁或者悲观锁。
悲观锁(Pessimistic Lock), 顾名思义,就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会block直到它拿到锁。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。
乐观锁(Optimistic Lock), 顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库如果提供类似于write_condition机制的其实都是提供的乐观锁。
两种锁各有优缺点,不能单纯的定义哪个好于哪个。乐观锁比较适合数据修改比较少,读取比较频繁的场景,即使出现了少量的冲突,这样也省去了大量的锁的开销,故而提高了系统的吞吐量。但是如果经常发生冲突(写数据比较多的情况下),上层应用不不断的retry,这样反而降低了性能,对于这种情况使用悲观锁就更合适。
实战
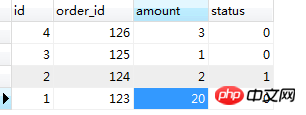
对这个表的 amount 进行修改,开两个命令行窗口
第一个窗口A;
SET AUTOCOMMIT=0; BEGIN WORK; SELECT * FROM order_tbl WHERE order_id='124' FOR UPDATE;
第二个窗口B:
# 更新订单ID 124 的库存数量 UPDATE `order_tbl` SET amount = 1 WHERE order_id = 124;
我们可以看到窗口A加了事物,锁住了这条数据,窗口B执行时会出现这样的问题:
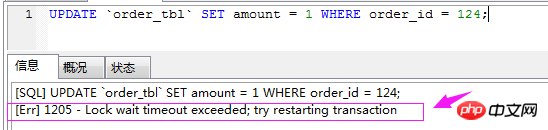
第一个窗口完整的提交事物:
SET AUTOCOMMIT=0; BEGIN WORK; SELECT * FROM order_tbl WHERE order_id='124' FOR UPDATE; UPDATE `order_tbl` SET amount = 10 WHERE order_id = 124; COMMIT WORK;
相关推荐:
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!