
Maison >développement back-end >Tutoriel Python >Implémentation de l'algorithme K-means en Python
Implémentation de l'algorithme K-means en Python

- 小云云original
- 2017-12-06 10:28:102042parcourir
K-means est un algorithme couramment utilisé dans l'apprentissage automatique. Il s'agit d'un algorithme d'apprentissage non supervisé. Il est souvent utilisé pour le regroupement de données. Il vous suffit de spécifier le nombre de clusters pour qu'il agrège automatiquement les données en plusieurs catégories. la similarité des données dans le même cluster est élevée et la similarité des données dans différents clusters est faible.
L'algorithme K-MEANS est un algorithme qui saisit le nombre de clusters k et une base de données contenant n objets de données, et génère k clusters qui répondent au critère de variance minimale. L'algorithme k-means accepte une quantité d'entrée k ; puis divise n objets de données en k clusters de sorte que les clusters obtenus satisfont : la similarité des objets dans le même cluster est plus élevée et la similarité des objets dans différents clusters est plus petite. Cet article vous présentera l'implémentation de l'algorithme K-means en Python.
Idée de base
Trouver de manière itérative un schéma de partitionnement pour k clusters, de sorte que la valeur moyenne de ces k clusters soit utilisée pour représenter les types d'échantillons correspondants dans leur ensemble. l'erreur est la plus petite.
k clusters ont les caractéristiques suivantes : chaque cluster lui-même est aussi compact que possible, et chaque cluster est aussi séparé que possible.
La base de l'algorithme k-means est le critère de la somme d'erreur minimale des carrés Avantages et inconvénients des K-menas :
Avantages :
Principe simple
Vitesse rapide
Bonne évolutivité pour les grands ensembles de données
Inconvénients :
Besoin de être spécifié Le nombre de clusters K
est sensible aux valeurs aberrantes
est sensible aux valeurs initiales
Le processus de clustering des K-moyennes
it Le processus de clustering est similaire à l'algorithme de descente de gradient. Une fonction de coût est établie et la valeur de la fonction de coût devient de plus en plus petite au fil des itérations
Sélectionner de manière appropriée les centres initiaux des classes c Dans la k-ième itération, pour tout échantillon, trouvez la distance aux centres c et classez l'échantillon dans la classe du centre avec la distance la plus courte
Utilisez des méthodes telles que la moyenne pour mettre à jour la valeur centrale de ; la classe;
Pour tous les centres de cluster c, si la valeur reste inchangée après la mise à jour en utilisant la méthode d'itération de (2) (3), l'itération se termine, sinon l'itération continue.
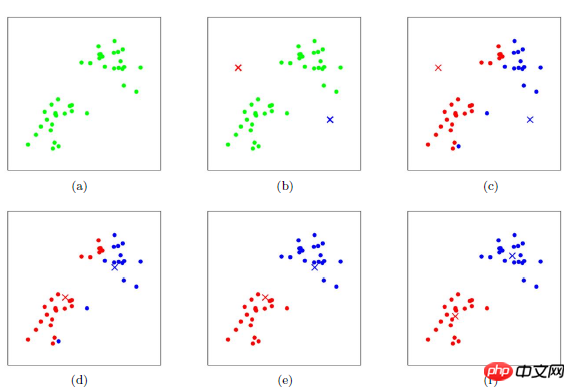
Exemple de K-means montrant
sklearn.cluster.KMeans( n_clusters=8, init='k-means++', n_init=10, max_iter=300, tol=0.0001, precompute_distances='auto', verbose=0, random_state=None, copy_x=True, n_jobs=1, algorithm='auto' ) n_clusters: 簇的个数,即你想聚成几类 init: 初始簇中心的获取方法 n_init: 获取初始簇中心的更迭次数,为了弥补初始质心的影响,算法默认会初始10个质心,实现算法,然后返回最好的结果。 max_iter: 最大迭代次数(因为kmeans算法的实现需要迭代) tol: 容忍度,即kmeans运行准则收敛的条件 precompute_distances:是否需要提前计算距离,这个参数会在空间和时间之间做权衡,如果是True 会把整个距离矩阵都放到内存中,auto 会默认在数据样本大于featurs*samples 的数量大于12e6 的时候False,False 时核心实现的方法是利用Cpython 来实现的 verbose: 冗长模式(不太懂是啥意思,反正一般不去改默认值) random_state: 随机生成簇中心的状态条件。 copy_x: 对是否修改数据的一个标记,如果True,即复制了就不会修改数据。bool 在scikit-learn 很多接口中都会有这个参数的,就是是否对输入数据继续copy 操作,以便不修改用户的输入数据。这个要理解Python 的内存机制才会比较清楚。 n_jobs: 并行设置 algorithm: kmeans的实现算法,有:'auto', ‘full', ‘elkan', 其中 ‘full'表示用EM方式实现 虽然有很多参数,但是都已经给出了默认值。所以我们一般不需要去传入这些参数,参数的。可以根据实际需要来调用。
from sklearn.cluster import KMeans from sklearn.externals import joblib from sklearn import cluster import numpy as np # 生成10*3的矩阵 data = np.random.rand(10,3) print data # 聚类为4类 estimator=KMeans(n_clusters=4) # fit_predict表示拟合+预测,也可以分开写 res=estimator.fit_predict(data) # 预测类别标签结果 lable_pred=estimator.labels_ # 各个类别的聚类中心值 centroids=estimator.cluster_centers_ # 聚类中心均值向量的总和 inertia=estimator.inertia_ print lable_pred print centroids print inertia 代码执行结果 [0 2 1 0 2 2 0 3 2 0] [[ 0.3028348 0.25183096 0.62493622] [ 0.88481287 0.70891813 0.79463764] [ 0.66821961 0.54817207 0.30197415] [ 0.11629904 0.85684903 0.7088385 ]] 0.570794546829
from sklearn.cluster import KMeans
from sklearn.externals import joblib
from sklearn import cluster
import numpy as np
import matplotlib.pyplot as plt
data = np.random.rand(100,2)
estimator=KMeans(n_clusters=3)
res=estimator.fit_predict(data)
lable_pred=estimator.labels_
centroids=estimator.cluster_centers_
inertia=estimator.inertia_
#print res
print lable_pred
print centroids
print inertia
for i in range(len(data)):
if int(lable_pred[i])==0:
plt.scatter(data[i][0],data[i][1],color='red')
if int(lable_pred[i])==1:
plt.scatter(data[i][0],data[i][1],color='black')
if int(lable_pred[i])==2:
plt.scatter(data[i][0],data[i][1],color='blue')
plt.show()
Pour des millions de données, le temps d'ajustement est toujours acceptable. On voit que l'efficacité est toujours bonne. la préservation du modèle est similaire à d'autres modèles d'algorithmes d'apprentissage automatique. Enregistrez quelque chose comme
| 数据规模 | 消耗时间 | 数据维度 |
|---|---|---|
| 10000条 | 4s | 50维 |
| 100000条 | 30s | 50维 |
| 1000000条 | 4'13s | 50维 |
Le contenu ci-dessus est l'implémentation de l'algorithme K-means en Python, j'espère. cela peut aider tout le monde.
from sklearn.externals import joblib joblib.dump(km,"model/km_model.m")Utilisez l'algorithme de clustering k-means pour identifier la couleur principale de l'image
Utilisez l'algorithme de clustering k-means pour identifier l'image Tutoriel Main Color_PHP
Image Compréhension de l'algorithme K-Means
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!