
Maison >interface Web >js tutoriel >Connaissance de la séparation front-end et back-end et des services pratiques de niveau intermédiaire nodejs
Connaissance de la séparation front-end et back-end et des services pratiques de niveau intermédiaire nodejs
- 一个新手original
- 2017-10-25 13:01:533062parcourir
1. Contexte
Suite de ce qui précède, discutant brièvement de la séparation et de la pratique du front-end et du back-end (1) Nous utilisons un serveur fictif pour créer notre propre service de simulation de données front-end. le processus de développement front-end et back-end, il nous suffit de définir des spécifications d'interface permettant à chacun de mener à bien ses tâches de développement respectives. Lors du débogage conjoint, effectuez simplement le débogage conjoint des données conformément aux spécifications de développement précédemment définies. Les fonctions du front-end et du back-end sont plus claires :
| 后端 | 前端 |
|---|---|
| 提供数据 | 接收数据,返回数据 |
| 处理业务逻辑 | 处理渲染逻辑 |
| Server-side MVC架构 | Client-side MV* 架构 |
| 代码跑在服务器上 | 代码跑在浏览器上 |
La séparation ici est nette et la division du travail est claire. Tout semble bien aller, mais... nous pouvons facilement trouver le problème :
Modélisez-le côté client. est le traitement du modèle côté serveur
La vue côté client et côté serveur sont différents niveaux de choses
Contrôleur côté client et Le contrôleur côté serveur a sa propre
route côté client, mais le côté serveur peut ne pas avoir
qui c'est-à-dire que le côté serveur et les responsabilités de chaque couche du client se chevauchent, et chacun fait ce qu'il veut, ce qui rend difficile l'unification des choses spécifiques à faire. Et cela peut s'accompagner de certains problèmes de performances. La manifestation la plus spécifique est nos applications SPA couramment utilisées :
Rendu, les valeurs sont toutes faites sur le client, il y a des problèmes de performances
obligatoire En attendant que les ressources soient disponibles avant de continuer, il y aura un bref écran blanc et clignotant
L'expérience sur les appareils mobiles à bas débit est extrêmement mauvaise
Le rendu est entièrement côté client, les modèles ne peuvent pas être réutilisés et la mise en œuvre du référencement est gênante
Ensuite, la quantité de notre code devient de plus en plus grande, et nous devons vérifier de plus en plus de formulaires. Parfois, la soumission frontale doit vérifier le formulaire une fois.
Le serveur doit être vérifié pour garantir la fiabilité des données ; le routage frontal peut ne pas exister sur le serveur... et ainsi de suite, une série de problèmes de réutilisation. Notre reconstruction précédente pourrait donc nécessiter une réflexion plus approfondie.
2. Commencer le refactoring
Avant de commencer à refactoriser, nous devons diviser les frontières front-end et back-end, c'est-à-dire ce qui appartient à la catégorie front-end et quoi appartient à la catégorie back-end. La division front-end et back-end la plus traditionnelle peut être comme ceci :
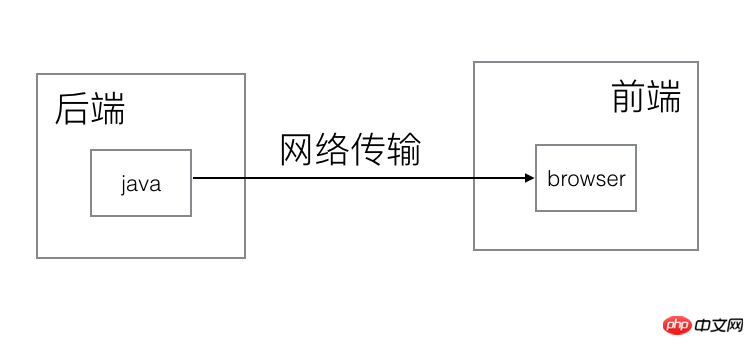
Alors la question se pose : le câblage de notre division front-end et back-end est divisé selon les responsabilités professionnelles Front-end et back-end ou front-end et back-end divisés selon l'environnement matériel ? Depuis que nous utilisons nodejs, nous pouvons redéfinir les catégories front-end et back-end en termes de fonctions de travail :
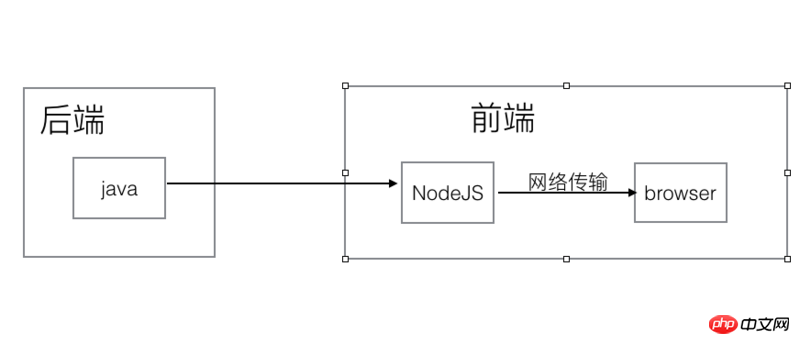
Comme vous pouvez le constater, il existe plus de front-ends ici qu'avant nodejs, c'est-à-dire que nous avons construit un service nodejs comme couche intermédiaire entre le front-end et le back-end !
Pourquoi choisissons-nous nodejs comme couche intermédiaire ? Parce que nous plaçons la couche intermédiaire dans la catégorie front-end, pour les amis du front-end, nodejs est toujours js après tout, donc d'un point de vue grammatical, il ne devrait y avoir aucun problème à le replier. Deuxièmement, le coût de transfert de développement est également faible, et il n'est pas nécessaire de changer la logique et la syntaxe du langage d'avant en arrière :
Le front-end est familier avec le langage, et le coût d'apprentissage est faible
Les deux sont en JS et peuvent être réutilisés sur le front et le backend
Convient pour : événementiel , E/S non bloquantes
Convient aux entreprises à forte intensité d'E/S
La vitesse d'exécution n'est pas mauvaise non plus
Bon, après avoir dit tant de choses à l'avance, que peut nous apporter cette couche intermédiaire ? Il faut savoir que le coût de développement lié à l'introduction de nodejs est également très élevé. Tout d'abord, il s'agit d'une couche supplémentaire de services, sans parler de bien d'autres, rien qu'en termes de temps de transmission, il y a une couche supplémentaire de temps de transmission ! Étudions quels scénarios d'application nodejs peuvent nous apporter et qui présentent plus d'avantages que d'inconvénients.
3. Commençons le parcours de la couche intermédiaire
Après avoir présenté nodejs, redivisons les fonctions front-end et back-end :
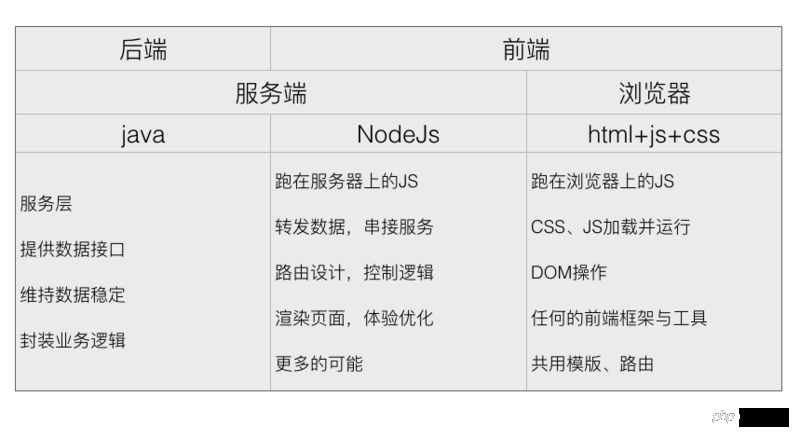
C'est l'idée principale des nodejs de couche intermédiaire. Jetons un coup d'œil aux scénarios commerciaux courants :
1. Réparation de la fiabilité des données d'interface
Parfois. Le serveur nous renvoie Les données peuvent ne pas être la structure souhaitée par le front-end.Toutes les données d'affichage utilisées sont fournies par le back-end via une interface asynchrone (AJAX/JSONP), et le front-end ne fait que les afficher. Cependant, le backend fournit souvent une logique de données backend, et le frontend doit également traiter cette logique de données. Par exemple, lorsque je développe une fonction, je rencontre parfois ce problème :
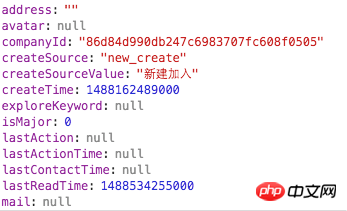
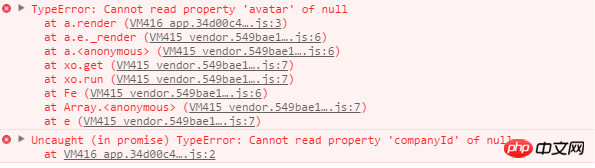
Un certain champ renvoyé par le serveur est nul ou la structure de données renvoyée par le serveur est trop profonde. Le front-end doit continuellement écrire un tel code pour déterminer si la structure de données renvoie réellement la bonne chose, plutôt que nulle ou indéfinie :
if (params.items && params.items.type && ...) {
// todo
}Dans ce cas, notre front-end ne devrait pas vérifier à plusieurs reprises le format des données, et cela ne devrait pas être ce que js côté navigateur doit faire. Nous pouvons effectuer un transfert d'interface dans la couche intermédiaire et effectuer un traitement des données pendant le processus de transfert. Pas besoin de vous soucier du retour des données :
router.get('/buyer/product/detail', (req, res, next) => {
httpRequest.get('/buyer/product/detail', (data) => {
// todo 处理数据
res.send(data);
})
})2. 页面性能优化 和 SEO
有点时候我们做单页面应用,经常会碰到首屏加载性能问题,这个时候如果我们接了中间层nodejs的话,那么我们可以把首屏渲染的任务交给nodejs去做,次屏的渲染依然走之前的浏览器渲染。(前端换页,浏览器端渲染,直接输入网址,服务器渲染)服务端渲染对页面进行拼接直出html字符串,可以大幅提高首屏渲染的时间,减少用户的等待时间。这种形式应用最广的比如 Vue 的服务端渲染,里面也有相关的介绍。
其次对于单页面的SEO优化也是很好地处理方式,由于目前的ajax并不被搜索百度等搜索引擎支持,所以如果想要得到爬虫的支持,那么服务端渲染也是一种解决方法。(PS:如果觉得服务端渲染太麻烦,我这里还有一篇介绍处理SEO的另一种思路处理 Vue 单页面 Meta SEO的另一种思路可以参考)
3. 淘宝常见的需求解决方案
需求:在淘宝,单日四亿PV,页面数据来自各个不同接口,为了不影响体验,先产生页面框架后,在发起多个异步请求取数据更新页面,这些多出来的请求带来的影响不小,尤其在无线端。
解决方案:在NodeJS端使用 Bigpiper 技术,合并请求,降低负担,分批输出,不影响体验。同时可以拆分大接口为独立小接口,并发请求。串行 => 并行,大幅缩短请求时间。
![]()
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Une analyse approfondie du composant de groupe de liste Bootstrap
- Explication détaillée du currying de la fonction JavaScript
- Exemple complet de génération de mot de passe JS et de détection de force (avec téléchargement du code source de démonstration)
- Angularjs intègre l'interface utilisateur WeChat (weui)
- Comment basculer rapidement entre le chinois traditionnel et le chinois simplifié avec JavaScript et l'astuce permettant aux sites Web de prendre en charge le basculement entre les compétences en chinois simplifié et traditionnel_javascript