
Maison >Java >javaDidacticiel >Exemple d'analyse du diagramme DICOM d'analyse Java pour obtenir des données hexadécimales
Exemple d'analyse du diagramme DICOM d'analyse Java pour obtenir des données hexadécimales

- 黄舟original
- 2017-10-18 09:51:161856parcourir
DICOM signifie Medical Digital Imaging and Communication. Il s'agit d'une norme internationale pour les images médicales et les informations associées (ISO 12052). L'article suivant vous présente principalement des informations pertinentes sur la façon d'obtenir des données hexadécimales en utilisant Java pour analyser les diagrammes DICOM. . L'article le présente en détail à travers un exemple de code. Les amis dans le besoin peuvent s'y référer.
Avant-propos
Dans un projet récent, JAVA était nécessaire pour analyser les images DICOM qui sont largement utilisées en médecine radiologique, en imagerie cardiovasculaire et en radiothérapie. équipements de diagnostic et de traitement (rayons X, tomodensitométrie, IRM, échographie, etc.), et est de plus en plus largement utilisé dans d'autres domaines médicaux tels que l'ophtalmologie et la dentisterie. Certains problèmes rencontrés lors de la mise en œuvre seront enregistrés ci-dessous.
Trouvez d'abord un fichier *.dcm. Ouvrez-le avec l'éditeur et vous verrez l'interface suivante. L'éditeur que j'utilise est UltraEdit
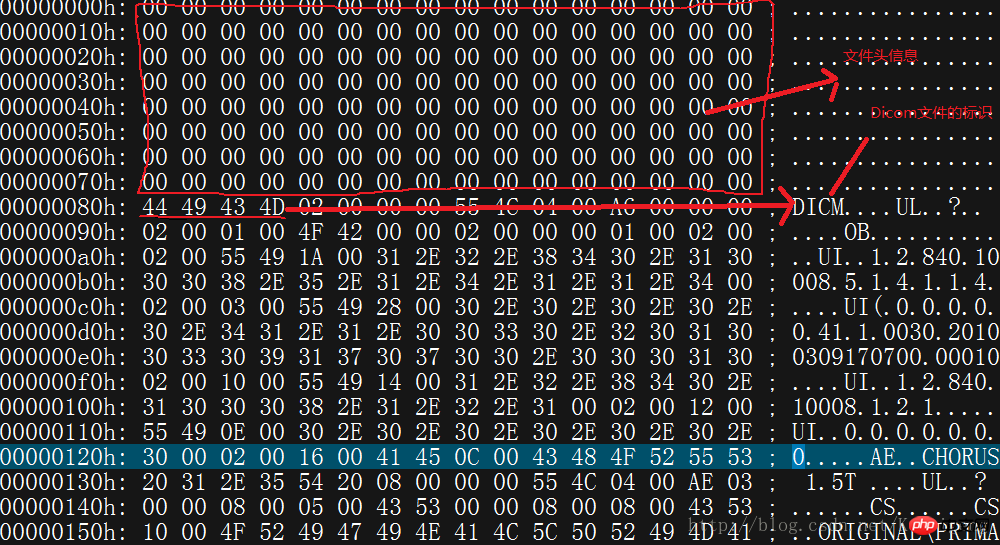
Le texte rouge marqué est l'annotation du bytecode. Les 8 premières lignes de code sont les informations d'en-tête du fichier et sont généralement inutiles. . Les quatre nombres hexadécimaux « 44,49,43,4D » commençant sur la neuvième ligne sont importants. L'explication du code ASCll est DICM. Indique qu'il s'agit d'un fichier DICOM. Si ces quatre nombres hexadécimaux sont perdus ou endommagés, l'image DICOM ne peut pas être ouverte.
Ce qui suit utilise Java pour lire ces nombres hexadécimaux
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
public class My_DICOM {
static FileInputStream input;
static byte[] b;
public static void main(String[] args) {
try {
File file = new File("G:/zzz.dcm");
input = new FileInputStream(file);
b = new byte[(int) file.length()];
input.read(b);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
init();
}
public static void init(){
System.out.println("b.length="+b.length);
for (int i =0;i<10000;i++) {
System.out.print(Integer.toHexString(b[i]));
if (i%16==15) {
System.out.println();
}else{
System.out.print(", ");
}
}
}
} (car le fichier est trop grand et contient 130 000 octets, donc à des fins de démonstration, il ne boucle que 10 000 fois.)
Le code ci-dessus est très courant, qui consiste à lire le flux de fichiers dans un tableau d'octets intermédiaire. . Utilisez Integer.toHexString(b[i]) pour le convertir en hexadécimal.
Un problème surgit.
Après l'exécution :
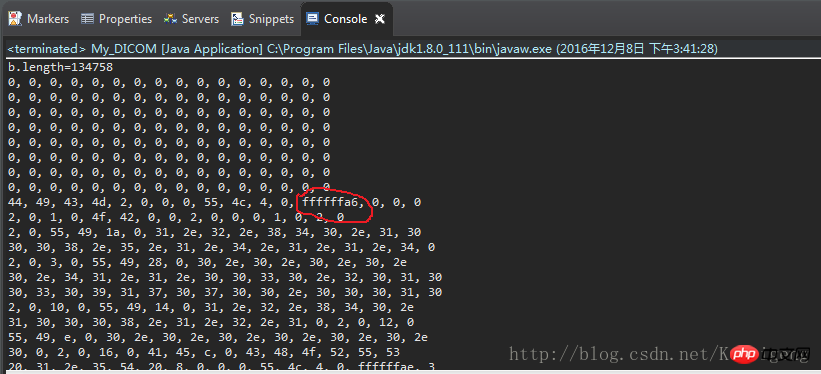
Par rapport à la liste hexadécimale ouverte par l'éditeur ci-dessus, le texte rouge devrait être a6, mais il n'est pas ffffffa6 est imprimé.
Trouver le problème
L'emplacement du mauvais octet est 140. L'impression de system.out.pritln(b[140]); donne -90. Pourquoi -90 ?.
Reculer vers a6 et le convertir en décimal devrait être 166.
D'accord, j'ai trouvé le problème. 166+90=256 Ce n'est pas une coïncidence. Un problème négligé est que la valeur maximale du tableau d'octets n'est que de 127. Par conséquent, lorsque le tableau lu dans le fichier est supérieur à 127, une erreur se produira lors de la lecture du tableau d'octets.
Solution
public static void init(){
System.out.println("b.length="+b.length);
for (int i =0;i<10000;i++) {
if (b[i]<0) {
int temp=b[i]+256;
System.out.print(Integer.toHexString(temp));
}else{
System.out.print(Integer.toHexString(b[i]));
}
if (i%16==15) {
System.out.println();
}else{
System.out.print(", ");
}
}
}Résumé
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!