
Maison >Java >javaDidacticiel >Analyse de quatre façons d'optimiser les verrous internes dans la machine virtuelle Java
Analyse de quatre façons d'optimiser les verrous internes dans la machine virtuelle Java

- 黄舟original
- 2017-10-13 10:18:431353parcourir
Cet article présente principalement les quatre méthodes d'optimisation de la machine virtuelle Java pour les verrous internes. L'éditeur pense que c'est plutôt bon, je vais donc le partager avec vous maintenant et le donner comme référence. Suivons l'éditeur pour y jeter un œil
Depuis Java 6/Java 7, la machine virtuelle Java a apporté quelques optimisations à l'implémentation des verrous internes. Ces optimisations incluent principalement Lock Elision, Lock Coarsening, Biased Locking et Adaptive Locking. Ces optimisations ne fonctionnent qu'en mode serveur de machine virtuelle Java (c'est-à-dire que lors de l'exécution d'un programme Java, nous devrons peut-être spécifier le paramètre de machine virtuelle Java "-server" sur la ligne de commande pour activer ces optimisations).
1 Lock Elimination
Lock Elision est une optimisation réalisée par le compilateur JIT sur l'implémentation spécifique des verrous internes.
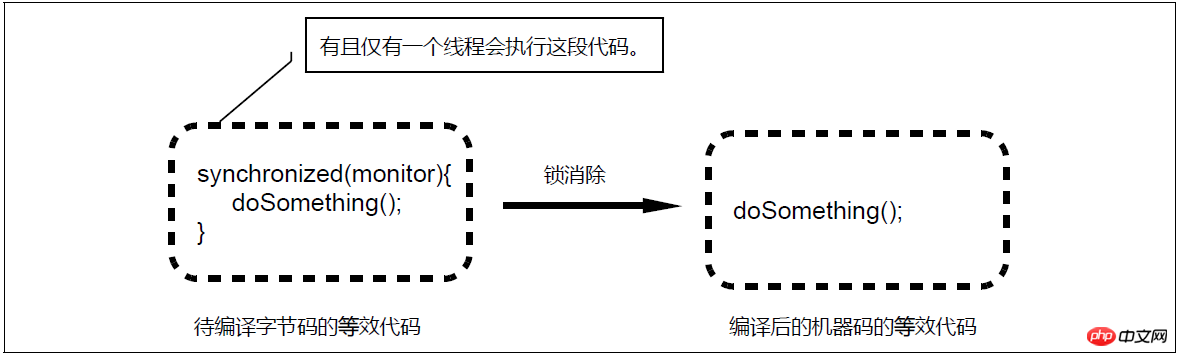
Schéma d'élimination du verrouillage
Lors de la compilation dynamique de blocs synchronisés, le compilateur JIT peut utiliser une méthode appelée technologie d'analyse d'échappement (Escape Analysis) pour déterminer si le verrou L'objet utilisé par le bloc synchronisé n'est accessible que par un seul thread et n'a pas été publié vers d'autres threads. S'il est confirmé que l'objet de verrouillage utilisé par le bloc synchronisé est accessible par un seul thread via cette analyse, alors le compilateur JIT ne générera pas le code machine correspondant à l'application de verrouillage et à la version représentée par synchronisé lors de la compilation du bloc synchronisé, mais uniquement le code machine correspondant au code de section critique d'origine est généré, ce qui donne l'impression que le bytecode compilé dynamiquement ne contient pas les deux instructions de bytecode monitorenter (demander le verrouillage) et monitorexit (libérer le verrouillage), c'est-à-dire éliminer l'utilisation de verrous . Cette optimisation du compilateur est appelée élimination des verrous (Lock Elision), ce qui nous permet d'éliminer complètement la surcharge des verrous dans certaines circonstances.
Bien que certaines classes de la bibliothèque standard Java (telles que StringBuffer) soient thread-safe, dans la pratique, nous ne partageons souvent pas les instances de ces classes entre plusieurs threads. Ces classes s'appuient souvent sur des verrous internes lors de l'implémentation de la sécurité des threads. Par conséquent, ces classes sont des cibles courantes pour les optimisations d’élimination des verrous.
Listing 12-1 Exemple de code pouvant être optimisé pour l'élimination des verrous
public class LockElisionExample {
public static String toJSON(ProductInfo productInfo) {
StringBuffer sbf = new StringBuffer();
sbf.append("{\"productID\":\"").append(productInfo.productID);
sbf.append("\",\"categoryID\":\"").append(productInfo.categoryID);
sbf.append("\",\"rank\":").append(productInfo.rank);
sbf.append(",\"inventory\":").append(productInfo.inventory);
sbf.append('}');
return sbf.toString();
}
}Dans l'exemple ci-dessus, le compilateur JIT compile toJSON Lors de l'appel d'une méthode, la méthode StringBuffer.append/toString qu'elle appelle sera intégrée dans la méthode, ce qui équivaut à copier les instructions dans le corps de la méthode StringBuffer.append/toString dans le corps de la méthode toJSON. L'instance StringBuffer sbf est ici une variable locale, et l'objet référencé par cette variable n'est pas publié sur d'autres threads. Par conséquent, l'objet référencé par sbf n'est accessible que par le thread d'exécution actuel (un thread) de la méthode où se trouve sbf. localisé (méthode toJSON). Par conséquent, le compilateur JIT peut désormais éliminer le verrou interne utilisé par les instructions de la méthode toJSON qui sont copiées à partir du corps de la méthode StringBuffer.append/toString. Dans cet exemple, le verrou utilisé par la méthode StringBuffer.append/toString elle-même ne sera pas libéré, car il peut y avoir d'autres endroits dans le système qui utilisent StringBuffer, et ces codes peuvent partager des instances StringBuffer.
La technologie d'analyse d'échappement sur laquelle repose l'optimisation de l'élimination des verrous est activée par défaut depuis Java SE 6u23, mais l'optimisation de l'élimination des verrous a été introduite dans Java 7.
Comme le montrent les exemples ci-dessus, l'optimisation de l'élimination des verrous peut également nécessiter une optimisation en ligne du compilateur JIT. Le fait qu'une méthode soit intégrée par le compilateur JIT dépend de la popularité de la méthode et de la taille du bytecode correspondant à la méthode (Bytecode Size). Par conséquent, la possibilité d'implémenter l'optimisation de l'élimination des verrous dépend également de la possibilité d'intégrer la méthode synchronisée appelée (ou la méthode avec bloc synchronisé).
L'optimisation de l'élimination des verrous nous indique que nous devons utiliser des verrous lorsque nous devrions utiliser des verrous, et que nous n'avons pas à nous soucier trop de la surcharge des verrous. Les développeurs doivent déterminer si un verrouillage est nécessaire au niveau logique du code. Quant à savoir si un verrou est réellement nécessaire au niveau de l'exécution du code, c'est le compilateur JIT qui décide. L'optimisation de l'élimination des verrous ne signifie pas que les développeurs peuvent utiliser des verrous internes à volonté lors de l'écriture du code (le verrouillage lorsque le verrouillage n'est pas requis), car l'élimination des verrous est une optimisation effectuée par le compilateur JIT plutôt que par javac, et un paragraphe de code ne peut être optimisé que par le compilateur JIT s'il est exécuté assez fréquemment. C'est-à-dire qu'avant l'intervention de l'optimisation du compilateur JIT, tant que le verrou interne est utilisé dans le code source, la surcharge de ce verrou existera. De plus, l'optimisation en ligne, l'analyse d'échappement et l'optimisation de l'élimination des verrous effectuées par le compilateur JIT ont toutes leur propre surcharge.
Sous l'effet de l'élimination du verrou, ThreadLocal est utilisé pour utiliser un objet thread-safe (tel que Random) comme objet spécifique au thread, ce qui évite non seulement les conflits de verrouillage, mais élimine également complètement toutes les erreurs internes. ces objets. Le surcoût du verrou utilisé.
2 Lock grossissement
Lock grossissement (Lock Coarsening/Lock Merging) est une optimisation réalisée par le compilateur JIT sur l'implémentation spécifique des verrous internes.
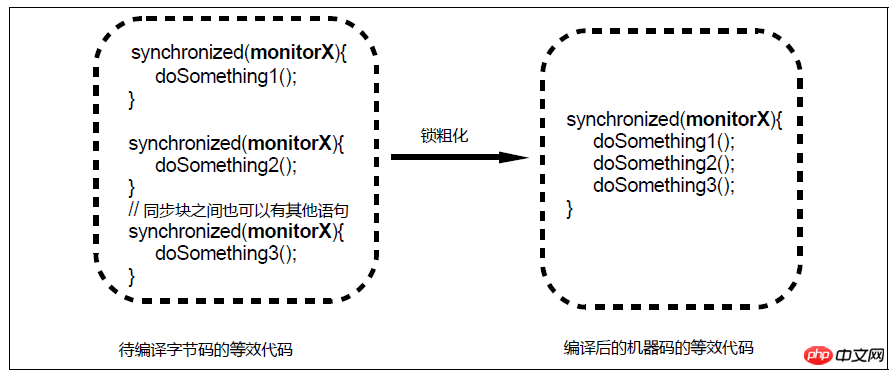
Diagramme de grossissement du verrou
对于相邻的几个同步块,如果这些同步块使用的是同一个锁实例,那么JIT编译器会将这些同步块合并为一个大同步块,从而避免了一个线程反复申请、释放同一个锁所导致的开销。然而,锁粗化可能导致一个线程持续持有一个锁的时间变长,从而使得同步在该锁之上的其他线程在申请锁时的等待时间变长。例如上图中,第1个同步块结束和第2个同步块开始之间的时间间隙中,其他线程本来是有机会获得monitorX的,但是经过锁粗化之后由于临界区的长度变长,这些线程在申请monitorX时所需的等待时间也相应变长了。因此,锁粗化不会被应用到循环体内的相邻同步块。
相邻的两个同步块之间如果存在其他语句,也不一定就会阻碍JIT编译器执行锁粗化优化,这是因为JIT编译器可能在执行锁粗化优化前将这些语句挪到(即指令重排序)后一个同步块的临界区之中(当然,JIT编译器并不会将临界区内的代码挪到临界区之外)。
实际上,我们写的代码中可能很少会出现上图中那种连续的同步块。这种同一个锁实例引导的相邻同步块往往是JIT编译器编译之后形成的。
例如,在下面的例子中
清单12-2 可进行锁粗化优化的示例代码
public class LockCoarseningExample {
private final Random rnd = new Random();
public void simulate() {
int iq1 = randomIQ();
int iq2 = randomIQ();
int iq3 = randomIQ();
act(iq1, iq2, iq3);
}
private void act(int... n) {
// ...
}
// 返回随机的智商值
public int randomIQ() {
// 人类智商的标准差是15,平均值是100
return (int) Math.round(rnd.nextGaussian() * 15 + 100);
}
// ...
}simulate方法连续调用randomIQ方法来生成3个符合正态分布(高斯分布)的随机智商(IQ)。在simulate方法被执行得足够频繁的情况下,JIT编译器可能对该方法执行一系优化:首先,JIT编译器可能将randomIQ方法内联(inline)到simulate方法中,这相当于把randomIQ方法体中的指令复制到simulate方法之中。在此基础上,randomIQ方法中的rnd.nextGaussian()调用也可能被内联,这相当于把Random.nextGaussian()方法体中的指令复制到simulate方法之中。Random.nextGaussian()是一个同步方法,由于Random实例rnd可能被多个线程共享(因为simulate方法可能被多个线程执行),因此JIT编译器无法对Random.nextGaussian()方法本身执行锁消除优化,这使得被内联到simulate方法中的Random.nextGaussian()方法体相当于一个由rnd引导的同步块。经过上述优化之后,JIT编译器便会发现simulate方法中存在3个相邻的由rnd(Random实例)引导的同步块,于是锁粗化优化便“粉墨登场”了。
锁粗化默认是开启的。如果要关闭这个特性,我们可以在Java程序的启动命令行中添加虚拟机参数“-XX:-EliminateLocks”(开启则可以使用虚拟机参数“-XX:+EliminateLocks”)。
3 偏向锁
偏向锁(Biased Locking)是Java虚拟机对锁的实现所做的一种优化。这种优化基于这样的观测结果(Observation):大多数锁并没有被争用(Contented),并且这些锁在其整个生命周期内至多只会被一个线程持有。然而,Java虚拟机在实现monitorenter字节码(申请锁)和monitorexit字节码(释放锁)时需要借助一个原子操作(CAS操作),这个操作代价相对来说比较昂贵。因此,Java虚拟机会为每个对象维护一个偏好(Bias),即一个对象对应的内部锁第1次被一个线程获得,那么这个线程就会被记录为该对象的偏好线程(Biased Thread)。这个线程后续无论是再次申请该锁还是释放该锁,都无须借助原先(指未实施偏向锁优化前)昂贵的原子操作,从而减少了锁的申请与释放的开销。
然而,一个锁没有被争用并不代表仅仅只有一个线程访问该锁,当一个对象的偏好线程以外的其他线程申请该对象的内部锁时,Java虚拟机需要收回(Revoke)该对象对原偏好线程的“偏好”并重新设置该对象的偏好线程。这个偏好收回和重新分配过程的代价也是比较昂贵的,因此如果程序运行过程中存在比较多的锁争用的情况,那么这种偏好收回和重新分配的代价便会被放大。有鉴于此,偏向锁优化只适合于存在相当大一部分锁并没有被争用的系统之中。如果系统中存在大量被争用的锁而没有被争用的锁仅占极小的部分,那么我们可以考虑关闭偏向锁优化。
偏向锁优化默认是开启的。要关闭偏向锁优化,我们可以在Java程序的启动命令行中添加虚拟机参数“-XX:-UseBiasedLocking”(开启偏向锁优化可以使用虚拟机参数“-XX:+UseBiasedLocking”)。
4 适应性锁
适应性锁(Adaptive Locking,也被称为 Adaptive Spinning )是JIT编译器对内部锁实现所做的一种优化。
存在锁争用的情况下,一个线程申请一个锁的时候如果这个锁恰好被其他线程持有,那么这个线程就需要等待该锁被其持有线程释放。实现这种等待的一种保守方法——将这个线程暂停(线程的生命周期状态变为非Runnable状态)。由于暂停线程会导致上下文切换,因此对于一个具体锁实例来说,这种实现策略比较适合于系统中绝大多数线程对该锁的持有时间较长的场景,这样才能够抵消上下文切换的开销。另外一种实现方法就是采用忙等(Busy Wait)。所谓忙等相当于如下代码所示的一个循环体为空的循环语句:
// 当锁被其他线程持有时一直循环
while (lockIsHeldByOtherThread){}可见,忙等是通过反复执行空操作(什么也不做)直到所需的条件成立为止而实现等待的。这种策略的好处是不会导致上下文切换,缺点是比较耗费处理器资源——如果所需的条件在相当长时间内未能成立,那么忙等的循环就会一直被执行。因此,对于一个具体的锁实例来说,忙等策略比较适合于绝大多数线程对该锁的持有时间较短的场景,这样能够避免过多的处理器时间开销。
事实上,Java虚拟机也不是非要在上述两种实现策略之中择其一 ——它可以综合使用上述两种策略。对于一个具体的锁实例,Java虚拟机会根据其运行过程中收集到的信息来判断这个锁是属于被线程持有时间“较长”的还是“较短”的。对于被线程持有时间“较长”的锁,Java虚拟机会选用暂停等待策略;而对于被线程持有时间“较短”的锁,Java虚拟机会选用忙等等待策略。Java虚拟机也可能先采用忙等等待策略,在忙等失败的情况下再采用暂停等待策略。Java虚拟机的这种优化就被称为适应性锁(Adaptive Locking),这种优化同样也需要JIT编译器介入。
适应性锁优化可以是以具体的一个锁实例为基础的。也就是说,Java虚拟机可能对一个锁实例采用忙等等待策略,而对另外一个锁实例采用暂停等待策略。
从适应性锁优化可以看出,内部锁的使用并不一定会导致上下文切换,这就是我们说锁与上下文切换时均说锁“可能”导致上下文切换的原因。

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!