
Maison >développement back-end >Tutoriel Python >Python3 implémente un robot d'exploration pour capturer l'analyse des commentaires populaires sur NetEase Cloud Music (photo)
Python3 implémente un robot d'exploration pour capturer l'analyse des commentaires populaires sur NetEase Cloud Music (photo)

- 黄舟original
- 2017-10-09 10:25:352280parcourir
Cet article vous présente principalement les informations pertinentes sur le robot d'exploration pratique de Python3 pour capturer les critiques les plus intéressantes sur la musique NetEase Cloud. L'article le présente de manière très détaillée à travers un exemple de code. Il a une certaine valeur d'apprentissage de référence pour les études ou le travail de chacun. , veuillez suivre l'éditeur pour apprendre ensemble.
Avant-propos
Je viens de commencer avec Python Crawler, et je n'ai pas écrit Python depuis environ un demi-mois, et j'ai presque oublié à ce sujet. J'allais donc écrire un robot d'exploration simple pour m'entraîner. Je pensais que les meilleures fonctionnalités de NetEase Cloud Music étaient ses recommandations précises de chansons et ses critiques d'utilisateurs uniques. J'ai donc écrit cette méthode pour capturer les critiques les plus intéressantes dans la liste de chansons populaires de NetEase Cloud Music. reptile. Je viens également de commencer l'exploration. Si vous avez des commentaires ou des questions, n'hésitez pas à les soulever. Progressons ensemble.
Fin de bêtises~ Jetons un coup d'œil à l'introduction détaillée.
Notre objectif est d'explorer les commentaires populaires de toutes les chansons dans le classement des chansons les plus populaires dans NetEase Cloud.
Cela peut non seulement réduire la charge de travail que nous devons explorer, mais également enregistrer des commentaires de haute qualité.
Analyse de la mise en œuvre
Tout d'abord, nous ouvrons la version Web de NetEase Cloud, comme indiqué dans la figure :
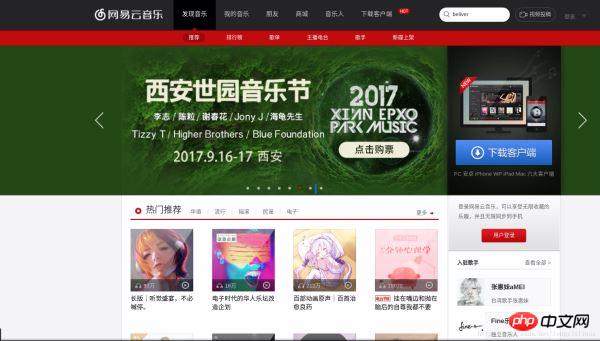
Cliquez sur la liste de classement, puis cliquez sur la liste des chansons chaudes de Cloud Music à gauche, comme indiqué sur l'image :
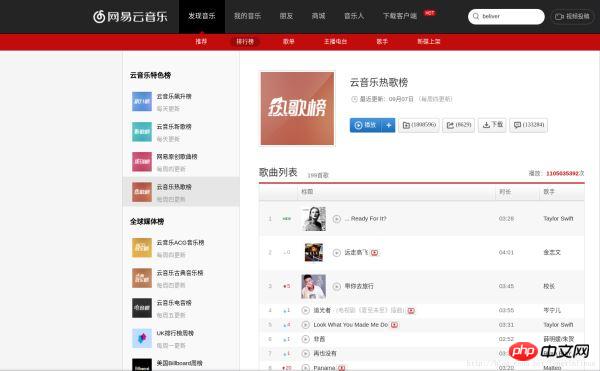
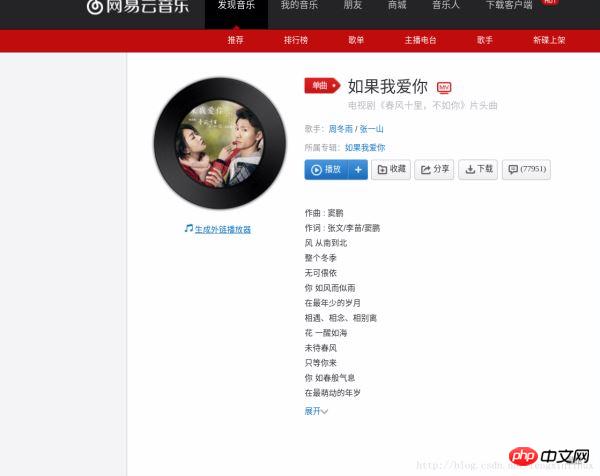
Ouvrons d'abord une chanson au hasard et découvrons comment récupérer la méthode spécifiée. La méthode de critiques de chansons populaires est celle indiquée sur l'image. J'ai choisi une chanson que j'aime récemment comme exemple :
<.>
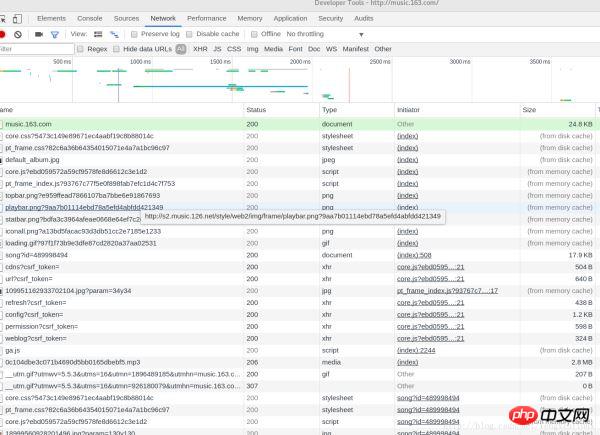
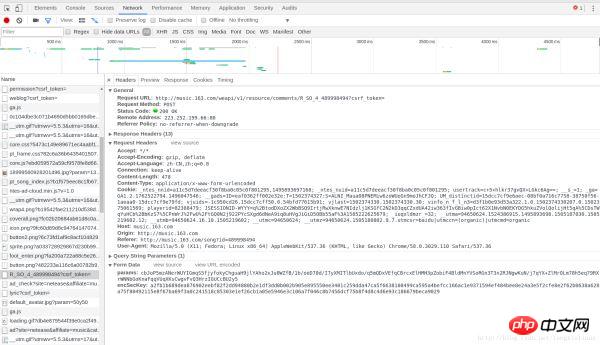
Une critique de chanson contenant cette chanson a été trouvée dans la requête POST. Envoyons cette capture d'écran de bloc afin que nous puissions le voir plus clairement : R_SO_4_489998494?csrf_token=

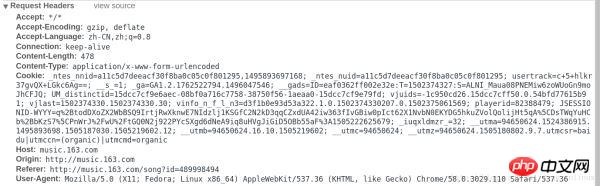

Regardons à nouveau les données du formulaire soumis. Nous constaterons que deux données doivent être renseignées dans le formulaire, nommées params et encSecKey. Ce qui suit est une grande chaîne de caractères. Si vous modifiez quelques chansons, vous constaterez que les paramètres et encSecKey de chaque chanson sont différents. Par conséquent, ces deux données peuvent avoir été cryptées par un algorithme spécifique.
Les données relatives aux commentaires renvoyées par le serveur sont au format json, qui contiennent des informations très riches (telles que des informations sur le commentateur, la date du commentaire, le nombre de likes, le contenu du commentaire, etc.), parmi lesquelles hotComments est notre Il y a un total de 15 commentaires populaires que nous recherchons, comme le montre l'image :
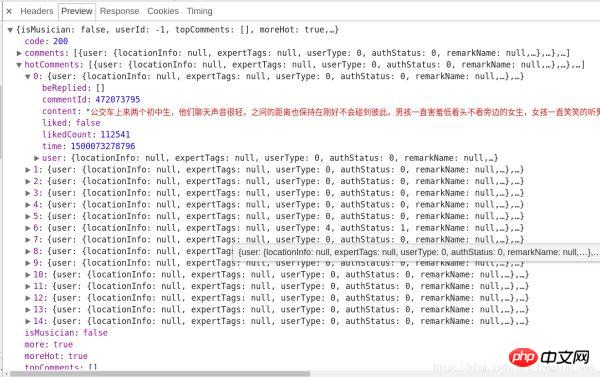
À ce stade, nous avons déterminé la direction, c'est-à-dire que nous il suffit de déterminer les deux paramètres params et encSecKey Just value. Mais ces deux paramètres sont chiffrés grâce à un algorithme spécifique, que faire ? J'ai trouvé un modèle, http://music.163.com/weapi/v1/resource/comments/R_SO_4_489998494?csrf_token= Le numéro après R_SO_4_ est la valeur d'identification de cette chanson, et pour différentes chansons, la valeur param et encSecKey, si vous passez ces deux valeurs de paramètres d'une chanson telle que A à la chanson B, alors pour un même nombre de pages, ce paramètre est universel, c'est-à-dire les deux valeurs de paramètres de la première page de A sont transmis au morceau B. Pour les deux paramètres de n'importe quel autre morceau, vous pouvez obtenir les commentaires sur la première page du morceau correspondant. Il en va de même pour la deuxième page, la troisième page, etc.
Et en fait, nous n'avons besoin que d'obtenir les 15 commentaires populaires sur la première page, il nous suffit donc de trouver une chanson et d'ajouter les paramètres et encSecKey dans la requête sur la première page de la chanson Copier ces deux valeurs de paramètres et vous pouvez les utiliser.
Concernant la façon de décrypter ces deux paramètres, il existe en fait une réponse sur le puissant Zhihu. Les amis intéressés peuvent entrer et jeter un œil (https://www.zhihu.com/question). / 36081767), il nous suffit d'utiliser notre méthode paresseuse pour remplir les exigences ici, xixi.
Jusqu'à présent, nous avons analysé comment capturer les commentaires populaires de NetEase Cloud Music. Analysons comment obtenir les informations de toutes les chansons de la liste des chansons populaires de Cloud Music.
Nous devons obtenir les noms des chansons et les valeurs d'identification correspondantes de toutes les chansons de la liste des chansons populaires de Cloud Music.
Semblable aux étapes d'analyse ci-dessus, nous entrons d'abord l'URL de la liste de chansons populaires, comme indiqué dans l'image :
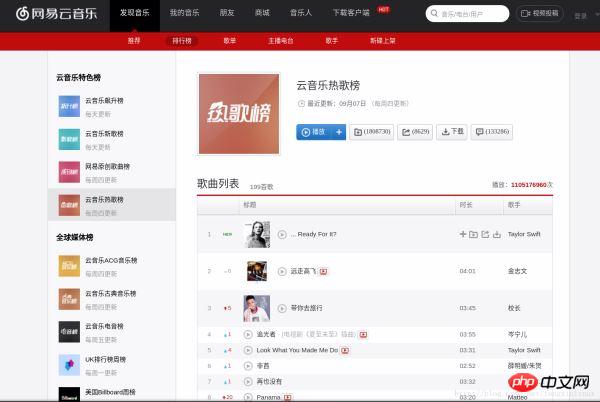
Appuyez sur F12 pour accéder au WEB workbench , comme indiqué dans l'image :
Nous avons trouvé toutes les informations sur les chansons de cette liste dans une requête GET nommée toplist?id=3778678.
Les informations correspondant à la requête sont telles qu'indiquées dans la figure :
Prévisualisons les résultats renvoyés par la requête, comme indiqué dans la figure :
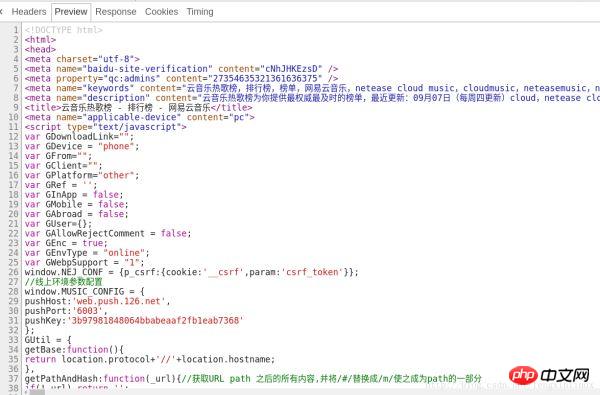
Nous avons trouvé le code contenant les informations sur la chanson à la ligne 524 du code, comme le montre la figure :
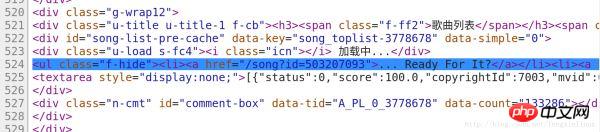
Par conséquent, il nous suffit d'ajouter le code de demande à , de filtrer les codes contenant des informations.
Ici, nous utilisons des expressions régulières pour le filtrage des données.
En observant les caractéristiques, nous pouvons extraire les informations sur la chanson dont nous avons besoin grâce à deux filtres d'expressions régulières.
Pour la première expression régulière, nous avons extrait la 525ème ligne de code de tous les codes renvoyés par la requête.
La première expression régulière est la suivante :
<ul class="f-hide"> <li> <a href="/song\?id=\d*?" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >.*</a> </li> </ul>
La deuxième expression régulière nous extrayons les informations sur la chanson dont nous avons besoin à la ligne 524, nous avons besoin de la chanson Le titre et l'identifiant de la chanson , l'expression régulière correspondante est la suivante :
Obtenez le titre de la chanson :
<li><a href="/song\?id=\d*?" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >(.*?)</a></li>
Obtenez l'identifiant de la chanson :
<li><a href="/song\?id=(\d*?)" rel="external nofollow" rel="external nofollow" >.*?</a></li>
à À ce stade , nous avons analysé l'ensemble du processus. Regardons le code pour voir les détails spécifiques ~~
Le code est le suivant :
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import re
import urllib.request
import urllib.error
import urllib.parse
import json
def get_all_hotSong(): #获取热歌榜所有歌曲名称和id
url='http://music.163.com/discover/toplist?id=3778678' #网易云云音乐热歌榜url
html=urllib.request.urlopen(url).read().decode('utf8') #打开url
html=str(html) #转换成str
pat1=r'<ul class="f-hide"><li><a href="/song\?id=\d*?">.*</a></li></ul>' #进行第一次筛选的正则表达式
result=re.compile(pat1).findall(html) #用正则表达式进行筛选
result=result[0] #获取tuple的第一个元素
pat2=r'<li><a href="/song\?id=\d*?">(.*?)</a></li>' #进行歌名筛选的正则表达式
pat3=r'<li><a href="/song\?id=(\d*?)">.*?</a></li>' #进行歌ID筛选的正则表达式
hot_song_name=re.compile(pat2).findall(result) #获取所有热门歌曲名称
hot_song_id=re.compile(pat3).findall(result) #获取所有热门歌曲对应的Id
return hot_song_name,hot_song_id
def get_hotComments(hot_song_name,hot_song_id):
url='http://music.163.com/weapi/v1/resource/comments/R_SO_4_' + hot_song_id + '?csrf_token=' #歌评url
header={ #请求头部
'User-Agent':'Mozilla/5.0 (X11; Fedora; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
#post请求表单数据
data={'params':'zC7fzWBKxxsm6TZ3PiRjd056g9iGHtbtc8vjTpBXshKIboaPnUyAXKze+KNi9QiEz/IieyRnZfNztp7yvTFyBXOlVQP/JdYNZw2+GRQDg7grOR2ZjroqoOU2z0TNhy+qDHKSV8ZXOnxUF93w3DA51ADDQHB0IngL+v6N8KthdVZeZBe0d3EsUFS8ZJltNRUJ','encSecKey':'4801507e42c326dfc6b50539395a4fe417594f7cf122cf3d061d1447372ba3aa804541a8ae3b3811c081eb0f2b71827850af59af411a10a1795f7a16a5189d163bc9f67b3d1907f5e6fac652f7ef66e5a1f12d6949be851fcf4f39a0c2379580a040dc53b306d5c807bf313cc0e8f39bf7d35de691c497cda1d436b808549acc'}
postdata=urllib.parse.urlencode(data).encode('utf8') #进行编码
request=urllib.request.Request(url,headers=header,data=postdata)
reponse=urllib.request.urlopen(request).read().decode('utf8')
json_dict=json.loads(reponse) #获取json
hot_commit=json_dict['hotComments'] #获取json中的热门评论
num=0
fhandle=open('./song_comments','a') #写入文件
fhandle.write(hot_song_name+':'+'\n')
for item in hot_commit:
num+=1
fhandle.write(str(num)+'.'+item['content']+'\n')
fhandle.write('\n==============================================\n\n')
fhandle.close()
hot_song_name,hot_song_id=get_all_hotSong() #获取热歌榜所有歌曲名称和id
num=0
while num < len(hot_song_name): #保存所有热歌榜中的热评
print('正在抓取第%d首歌曲热评...'%(num+1))
get_hotComments(hot_song_name[num],hot_song_id[num])
print('第%d首歌曲热评抓取成功'%(num+1))
num+=1Les résultats de l'exécution du code sont les suivants :
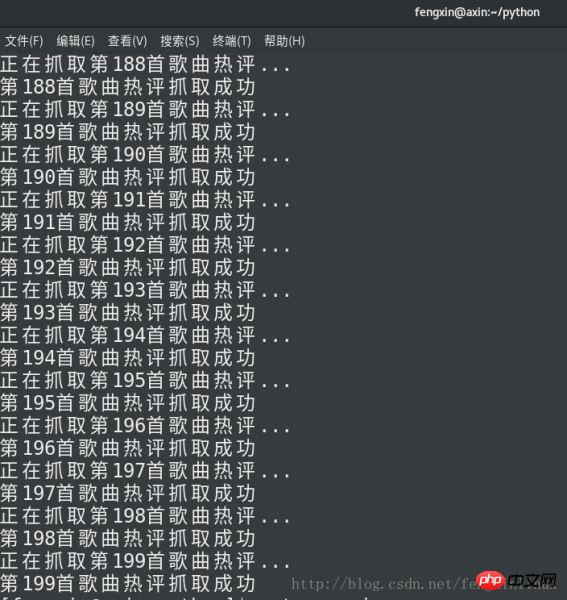
Comparez les critiques de la chanson "If I Love You" sur la page Web avec les chansons que nous avons enregistrées. Commentaires :
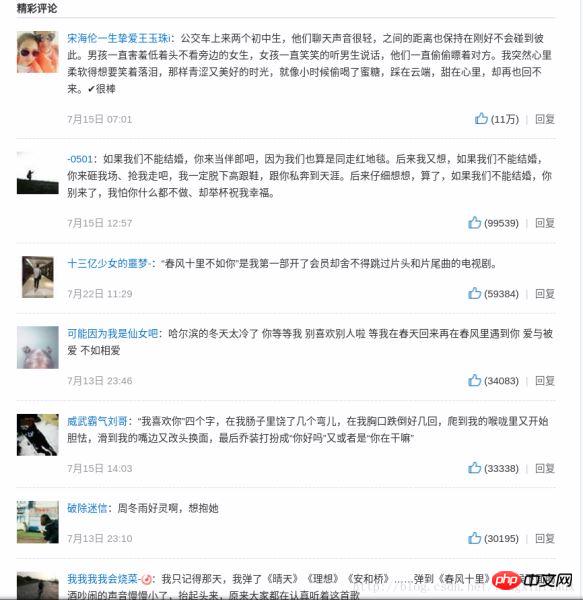

Informations correctes~
Résumé
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!