
Maison >développement back-end >Tutoriel Python >Comment utiliser Haystack avec Django en python : un exemple du framework de recherche en texte intégral
Comment utiliser Haystack avec Django en python : un exemple du framework de recherche en texte intégral

- 黄舟original
- 2017-10-03 06:00:562220parcourir
L'éditeur suivant vous proposera un article sur l'utilisation de haystack avec python django : framework de recherche en texte intégral (explication avec exemples). L'éditeur le trouve plutôt bon, je vais donc le partager avec vous maintenant et le donner comme référence pour tout le monde. Suivons l'éditeur pour y jeter un œil
botte de foin : un cadre pour la récupération de texte intégral
whoosh : écrit en pur Python Moteur de recherche en texte intégral
jieba : un package gratuit de segmentation de mots chinois
Première installation de ces trois packages
pip install django-haystack
pip install whoosh
pip install jieba
1 Modifier le fichier settings.py. et installez l'application haystack ,
2. Configurez le moteur de recherche dans le fichier settings.py
HAYSTACK_CONNECTIONS = {
'default': {
# 使用whoosh引擎
'ENGINE': 'haystack.backends.whoosh_cn_backend.WhooshEngine',
# 索引文件路径
'PATH': os.path.join(BASE_DIR, 'whoosh_index'),
}
}
# 当添加、修改、删除数据时,自动生成索引
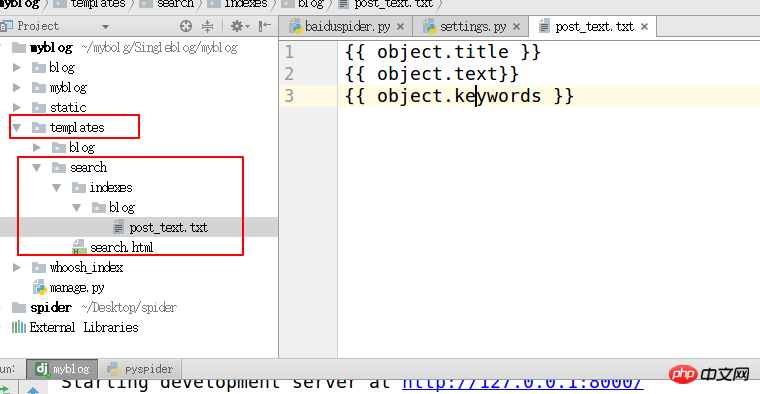
HAYSTACK_SIGNAL_PROCESSOR = 'haystack.signals.RealtimeSignalProcessor'3. blog/" dans le répertoire des templates "Créez un fichier blog_text.txt sous le nom de l'application de blog dans le répertoire
#Spécifiez l'attribut de l'index
{{ object.title }}
{{ object.text}}
{{ object .keywords }}
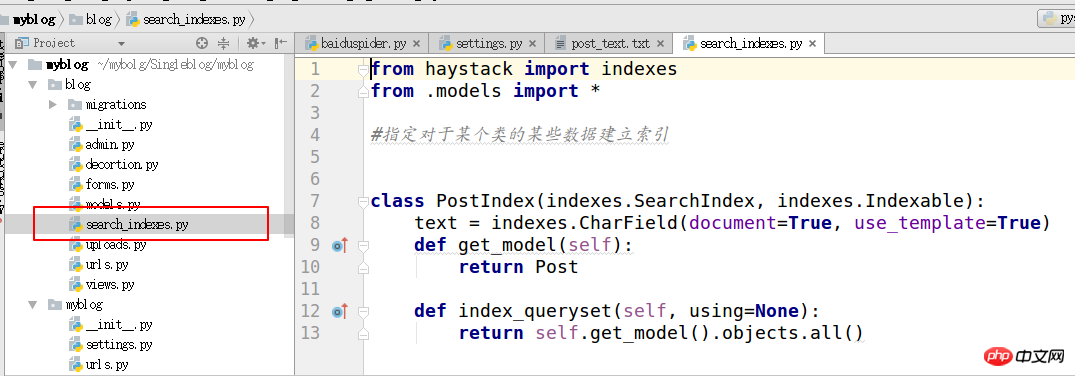
4. Créer des index de recherche
from haystack import indexes from models import Post #指定对于某个类的某些数据建立索引 class GoodsInfoIndex(indexes.SearchIndex, indexes.Indexable): text = indexes.CharField(document=True, use_template=True) def get_model(self): return Post #搜索的模型类 def index_queryset(self, using=None): return self.get_model().objects.all()
 sous l'application qui doit être recherchée
sous l'application qui doit être recherchée
5.
1. Modifier le fichier de botte de foin
2. le répertoire haystack sous l'environnement virtuel py_django. Ce répertoire est différent selon l'environnement python que vous utilisez, les chemins sont également différents.
3. site-packages/haystack/backends/ Créez un fichier nommé ChineseAnalyzer.py et écrivez le code suivant pour la segmentation des mots chinois
import jieba
from whoosh.analysis import Tokenizer, Token
class ChineseTokenizer(Tokenizer):
def __call__(self, value, positions=False, chars=False,
keeporiginal=False, removestops=True,
start_pos=0, start_char=0, mode='', **kwargs):
t = Token(positions, chars, removestops=removestops, mode=mode,
**kwargs)
seglist = jieba.cut(value, cut_all=True)
for w in seglist:
t.original = t.text = w
t.boost = 1.0
if positions:
t.pos = start_pos + value.find(w)
if chars:
t.startchar = start_char + value.find(w)
t.endchar = start_char + value.find(w) + len(w)
yield t
def ChineseAnalyzer():
return ChineseTokenizer() 6.
1. Copiez le fichier whoosh_backend.py et remplacez-le par le nom suivant
whoosh_cn_backend.py
Importez le module de segmentation de mots chinois dans le fichier copié. fichier
de .ChineseAnalyzer import ChineseAnalyzer
2. Changez la classe d'analyse de mots en chinois
Recherchez analyseur=StemmingAnalyzer() et remplacez-la par analyseur=ChineseAnalyzer()
7. La dernière étape consiste à créer les données d'index initiales
python manage.py reconstruction_index
8 Créer un modèle de recherche dans templates/indexes/ Créer un modèle search.html
Résultats de recherche Pour la pagination, le contexte transmis par la vue au modèle est le suivant requête : mots-clés de rechercheclass GoodsSearchView(SearchView): def get_context_data(self, *args, **kwargs): context = super().get_context_data(*args, **kwargs) context['iscart']=1 context['qwjs']=2 return contextAjoutez cette URL au fichier urls de l'application. Utilisez la classe comme méthode d'affichage .as_view().
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!