
Maison >Java >javaDidacticiel >Introduction à la méthode d'implémentation du robot d'exploration Web Java dans Hadoop
Introduction à la méthode d'implémentation du robot d'exploration Web Java dans Hadoop

- 黄舟original
- 2017-09-26 09:14:542805parcourir
L'éditeur suivant vous proposera un article sur l'implémentation du robot d'exploration Web Java dans Hadoop (exemple d'explication). L'éditeur le trouve plutôt bon, je vais donc le partager avec vous maintenant et le donner comme référence pour tout le monde. Suivons l'éditeur et jetons un coup d'œil
La mise en œuvre de ce web crawler sera liée au big data. Sur la base des deux articles précédents sur la mise en œuvre de robots d'exploration Web dans Java et sur la mise en œuvre de robots d'exploration Web dans heritrix, cette fois, nous devons effectuer une collecte complète de données, un téléchargement de données, une analyse de données, une lecture des résultats des données et une visualisation des données.
Vous devez utiliser
Cygwin : un environnement de simulation de type UNIX fonctionnant sur la plate-forme Windows, rechercher et télécharger directement en ligne, et l'installer
Hadoop : Configurez l'environnement Hadoop et implémentez un système de fichiers distribué (Hadoop Distributed File System), appelé HDFS, qui est utilisé pour télécharger et enregistrer directement les données collectées sur HDFS, puis les analyser avec MapReduce;
Eclipse : écrire du code, vous devez importer le package jar hadoop pour créer un projet MapReduce ; Jsoup : package jar d'analyse HTML, qui peut mieux analyser le code source d'une page Web lorsqu'il est combiné avec des expressions régulières ; 🎜>----- >
Répertoire :
1. >2. Configuration Hadoop Huang Jing
3. Construction de l'environnement de développement Eclipse
4. )
-------->
1. Installer et configurer Cygwin
Téléchargez le fichier d'installation de Cygwin depuis le site officiel, adresse : https ://cygwin.com/install.htmlAprès le téléchargement et l'exécution, entrez dans l'interface d'installation.
Téléchargez le package d'extension directement depuis le miroir réseau lors de l'installation. Vous devez au moins sélectionner le package de support ssh et ssl
Après l'installation, entrez dans l'interface de la console cygwin,
exécutez la commande ssh-host-config, installez SSH Entrée : non, oui, ntsec, non, non Remarque : sous win7, il doit être modifié en oui, oui, ntsec , non, oui, entrez le mot de passe et confirmez-le. Après avoir terminé les étapes , un service Cygwin sshd sera configuré dans le système d'exploitation Windows et le service pourra être démarré.Ensuite, configurez la connexion ssh sans mot de passe
Réexécutez cygwin. 
Modifiez le fichier hadoop-env.sh et ajoutez le paramètre d'emplacement JAVA_HOME du répertoire d'installation du JDK.
Remarque sur l'image :Program Files est abrégé en PROGRA~1
# The java implementation to use. Required. export JAVA_HOME=/cygdrive/c/Java/jdk1.7.0_67
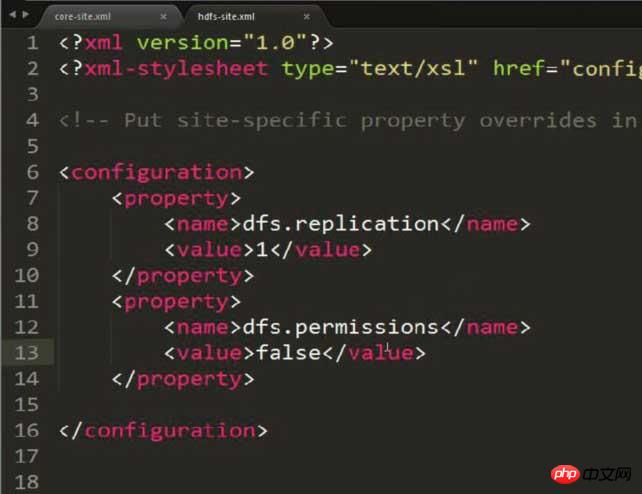
Modifiez hdfs-site.xml et définissez la copie de stockage sur 1 (car la configuration est pseudo-distribuée)

Remarque : Cette image Une propriété supplémentaire a été ajoutée pour résoudre d'éventuels problèmes d'autorisation ! ! !
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>
HDFS : système de fichiers distribué Hadoop Vous pouvez dynamiquement des fichiers ou des dossiers CRUD via des commandes dans HDFS
Notez que des autorisations peuvent apparaître Le problème doit être évité en configurant le contenu suivant dans hdfs-site.xml :<property> <name>dfs.permissions</name> <value>false</value> </property>
<configuration> <property> <name>mapred.job.tracker</name> <value>localhost:9001</value> </property> </configuration>Après avoir configuré le contenu ci-dessus , entrez le répertoire hadoop
<configuration> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> </configuration>
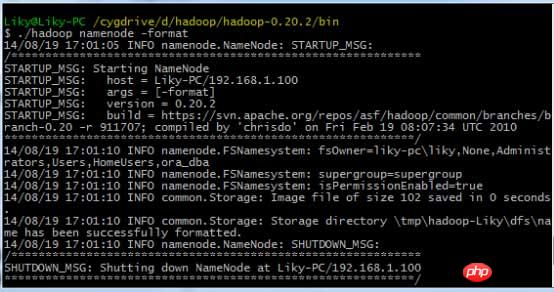
dans Cygwin, formatez le système de fichiers HDFS dans le répertoire bin (doit être formaté avant la première utilisation), puis entrez la commande de démarrage :

3. Configuration de l'environnement de développement Eclipse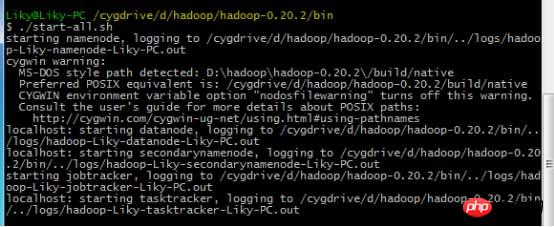
Le la méthode de configuration générale est donnée dans le blog que j'ai écrit sur le déploiement Big Data [2] HDFS et la lecture et l'écriture de fichiers (y compris la configuration Eclipse Hadoop). Cependant, il doit être amélioré à ce stade.
Copiez le package de support hadoop-eclipse-plugin.jar dans hadoop dans le répertoire des plugins d'Eclipse pour ajouter le support Hadoop à Eclipse.Après avoir démarré Eclipse, passez à l'interface MapReduce.
在windows工具选项选择showviews的others里面查找map/reduce locations。
在Map/Reduce Locations窗口中建立一个Hadoop Location,以便与Hadoop进行关联。

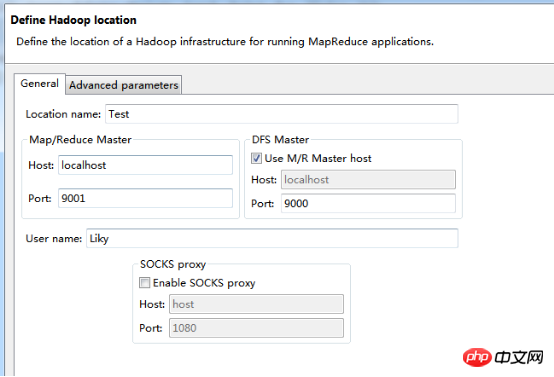
注意:此处的两个端口应为你配置hadoop的时候设置的端口!!!
完成后会建立好一个Hadoop Location
在左侧的DFS Location中,还可以看到HDFS中的各个目录
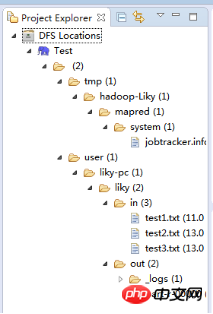
并且你可以在其目录下自由创建文件夹来存取数据。
下面你就可以创建mapreduce项目了,方法同正常创建一样。
4、网络数据爬取
现在我们通过编写一段程序,来将爬取的新闻内容的有效信息保存到HDFS中。
此时就有了两种网络爬虫的方法:
其一就是利用heritrix工具获取的数据;
其一就是java代码结合jsoup编写的网络爬虫。
方法一的信息保存到HDFS:
直接读取生成的本地文件,用jsoup解析html,此时需要将jsoup的jar包导入到项目中。
package org.liky.sina.save;
//这里用到了JSoup开发包,该包可以很简单的提取到HTML中的有效信息
import java.io.File;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class SinaNewsData {
private static Configuration conf = new Configuration();
private static FileSystem fs;
private static Path path;
private static int count = 0;
public static void main(String[] args) {
parseAllFile(new File(
"E:/heritrix-1.12.1/jobs/sina_news_job_02-20170814013255352/mirror/"));
}
public static void parseAllFile(File file) {
// 判断类型
if (file.isDirectory()) {
// 文件夹
File[] allFile = file.listFiles();
if (allFile != null) {
for (File f : allFile) {
parseAllFile(f);
}
}
} else {
// 文件
if (file.getName().endsWith(".html")
|| file.getName().endsWith(".shtml")) {
parseContent(file.getAbsolutePath());
}
}
}
public static void parseContent(String filePath) {
try {
//用jsoup的方法读取文件路径
Document doc = Jsoup.parse(new File(filePath), "utf-8");
//读取标题
String title = doc.title();
Elements descElem = doc.getElementsByAttributeValue("name",
"description");
Element descE = descElem.first();
// 读取内容
String content = descE.attr("content");
if (title != null && content != null) {
//通过Path来保存数据到HDFS中
path = new Path("hdfs://localhost:9000/input/"
+ System.currentTimeMillis() + ".txt");
fs = path.getFileSystem(conf);
// 建立输出流对象
FSDataOutputStream os = fs.create(path);
// 使用os完成输出
os.writeChars(title + "\r\n" + content);
os.close();
count++;
System.out.println("已经完成" + count + " 个!");
}
} catch (Exception e) {
e.printStackTrace();
}
}
}Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!