
Maison >développement back-end >Tutoriel Python >Analyser plusieurs façons dont Python analyse XML
Analyser plusieurs façons dont Python analyse XML
- 巴扎黑original
- 2017-09-19 10:20:272686parcourir
Quand j'ai appris PYTHON pour la première fois, je savais seulement qu'il existait deux méthodes d'analyse, DOM et SAX, mais leur efficacité n'était pas idéale. En raison du grand nombre de fichiers à traiter, ces deux méthodes prenaient trop de temps. consommatrice et inacceptable.
Après une recherche sur Internet, j'ai découvert qu'ElementTree, qui est actuellement largement utilisé et relativement efficace, est également un algorithme recommandé par de nombreuses personnes, j'ai donc utilisé cet algorithme pour la mesure et la comparaison réelles. ElementTree en comprend également deux. implémentations, l'une est Normal ElementTree (ET), l'autre est ElementTree.iterparse (ET_iter).
Cet article effectuera une comparaison horizontale des quatre méthodes de DOM, SAX, ET et ET_iter, et évaluera l'efficacité de chaque algorithme en comparant le temps nécessaire pour traiter les mêmes fichiers.
Dans le programme, les quatre méthodes d'analyse sont écrites sous forme de fonctions et appelées séparément dans le programme principal pour évaluer leur efficacité d'analyse.
L'exemple de contenu de fichier XML décompressé est :
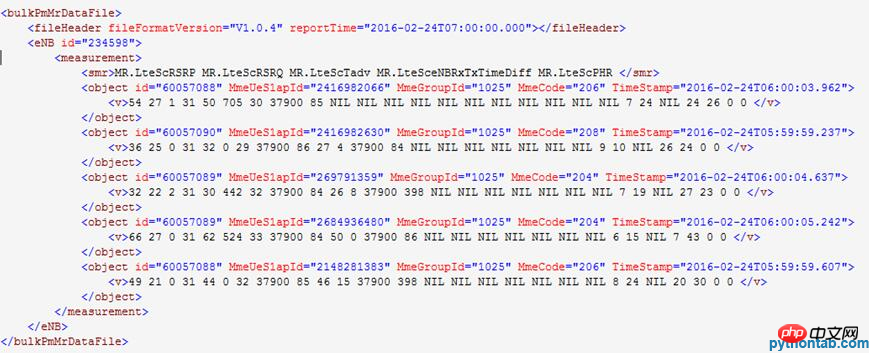
La fonction principale du programme appelant le code de pièce est :
print("文件计数:%d/%d." % (gz_cnt,paser_num))
str_s,cnt = dom_parser(gz)
#str_s,cnt = sax_parser(gz)
#str_s,cnt = ET_parser(gz)
#str_s,cnt = ET_parser_iter(gz)
output.write(str_s)
vs_cnt += cntDans la version initiale Dans l'appel de fonction, la fonction renvoie deux valeurs, mais lors de la réception de la valeur de l'appel de fonction, elle est appelée avec deux variables séparément, ce qui entraîne l'exécution de chaque fonction deux fois. Elle a ensuite été modifiée pour appeler deux variables à la fois pour recevoir la valeur de retour. , ce qui a réduit les appels invalides.
1. Analyse DOM
Code de définition de fonction :
def dom_parser(gz):
import gzip,cStringIO
import xml.dom.minidom
vs_cnt = 0
str_s = ''
file_io = cStringIO.StringIO()
xm = gzip.open(gz,'rb')
print("已读入:%s.\n解析中:" % (os.path.abspath(gz)))
doc = xml.dom.minidom.parseString(xm.read())
bulkPmMrDataFile = doc.documentElement
#读入子元素
enbs = bulkPmMrDataFile.getElementsByTagName("eNB")
measurements = enbs[0].getElementsByTagName("measurement")
objects = measurements[0].getElementsByTagName("object")
#写入csv文件
for object in objects:
vs = object.getElementsByTagName("v")
vs_cnt += len(vs)
for v in vs:
file_io.write(enbs[0].getAttribute("id")+' '+object.getAttribute("id")+' '+\
object.getAttribute("MmeUeS1apId")+' '+object.getAttribute("MmeGroupId")+' '+object.getAttribute("MmeCode")+' '+\
object.getAttribute("TimeStamp")+' '+v.childNodes[0].data+'\n') #获取文本值
str_s = (((file_io.getvalue().replace(' \n','\r\n')).replace(' ',',')).replace('T',' ')).replace('NIL','')
xm.close()
file_io.close()
return (str_s,vs_cnt)Résultat de l'exécution du programme :
*********** ** **************************************
Le traitement du programme démarre .
Le répertoire d'entrée est : /tmcdata/mro2csv/input31/.
Le répertoire de sortie est : /tmcdata/mro2csv/output31/.
Le nombre de fichiers .gz dans le répertoire d'entrée est : 12, 12 d'entre eux seront traités cette fois.
********************************************* **** ******
Nombre de fichiers : 1/12.
Lire dans : /tmcdata/mro2csv/input31/TD-LTE_MRO_NSN_OMC_234598_20160224060000.xml.gz.
Analyse :
Nombre de fichiers : 2/12.
Lire dans :/tmcdata/mro2csv/input31/TD-LTE_MRO_NSN_OMC_233798_20160224060000.xml.gz.
Analyse :
Nombre de fichiers : 3/12.
Lire dans : /tmcdata/mro2csv/input31/TD-LTE_MRO_NSN_OMC_123798_20160224060000.xml.gz.
Analyse :
…………………………………………
Nombre de fichiers : 12/12.
Lire dans : /tmcdata/mro2csv/input31/TD- LTE_MRO_NSN_OMC_235598_20160224060000. xml.gz.
Analyse :
Nombre de lignes VS : 177849, durée d'exécution : 107,077867, lignes traitées par seconde : 1660.
Écrit à : /tmcdata/mro2csv/output31/mro_0001.csv.
********************************************* **** ******
Le traitement du programme se termine.
Étant donné que l'analyse DOM nécessite de lire l'intégralité du fichier en mémoire et d'établir une arborescence, sa consommation de mémoire et sa consommation de temps sont relativement élevées, mais son avantage est que la logique est simple et qu'il n'y a pas besoin de définir un rappel fonction facile à mettre en œuvre.
2. Analyse SAX
Code de définition de la fonction :
def sax_parser(gz):
import os,gzip,cStringIO
from xml.parsers.expat import ParserCreate
#变量声明
d_eNB = {}
d_obj = {}
s = ''
global flag
flag = False
file_io = cStringIO.StringIO()
#Sax解析类
class DefaultSaxHandler(object):
#处理开始标签
def start_element(self, name, attrs):
global d_eNB
global d_obj
global vs_cnt
if name == 'eNB':
d_eNB = attrs
elif name == 'object':
d_obj = attrs
elif name == 'v':
file_io.write(d_eNB['id']+' '+ d_obj['id']+' '+d_obj['MmeUeS1apId']+' '+d_obj['MmeGroupId']+' '+d_obj['MmeCode']+' '+d_obj['TimeStamp']+' ')
vs_cnt += 1
else:
pass
#处理中间文本
def char_data(self, text):
global d_eNB
global d_obj
global flag
if text[0:1].isnumeric():
file_io.write(text)
elif text[0:17] == 'MR.LteScPlrULQci1':
flag = True
#print(text,flag)
else:
pass
#处理结束标签
def end_element(self, name):
global d_eNB
global d_obj
if name == 'v':
file_io.write('\n')
else:
pass
#Sax解析调用
handler = DefaultSaxHandler()
parser = ParserCreate()
parser.StartElementHandler = handler.start_element
parser.EndElementHandler = handler.end_element
parser.CharacterDataHandler = handler.char_data
vs_cnt = 0
str_s = ''
xm = gzip.open(gz,'rb')
print("已读入:%s.\n解析中:" % (os.path.abspath(gz)))
for line in xm.readlines():
parser.Parse(line) #解析xml文件内容
if flag:
break
str_s = file_io.getvalue().replace(' \n','\r\n').replace(' ',',').replace('T',' ').replace('NIL','') #写入解析后内容
xm.close()
file_io.close()
return (str_s,vs_cnt)Résultat de l'exécution du programme :
*********** ** **************************************
Le traitement du programme démarre .
Le répertoire d'entrée est : /tmcdata/mro2csv/input31/.
Le répertoire de sortie est : /tmcdata/mro2csv/output31/.
Le nombre de fichiers .gz dans le répertoire d'entrée est : 12, 12 d'entre eux seront traités cette fois.
********************************************* **** ******
Nombre de fichiers : 1/12.
Lire dans : /tmcdata/mro2csv/input31/TD-LTE_MRO_NSN_OMC_234598_20160224060000.xml.gz.
Analyse :
Nombre de fichiers : 2/12.
Lire dans :/tmcdata/mro2csv/input31/TD-LTE_MRO_NSN_OMC_233798_20160224060000.xml.gz.
Analyse :
Nombre de fichiers : 3/12.
Lire dans : /tmcdata/mro2csv/input31/TD-LTE_MRO_NSN_OMC_123798_20160224060000.xml.gz.
Analyse :
........................................
Nombre de fichiers : 12/12.
Lire dans : /tmcdata/mro2csv/input31/TD-LTE_MRO_NSN_OMC_235598_20160224060000.xml.gz.
Analyse :
Nombre de lignes VS : 177849, durée d'exécution : 14,386779, lignes traitées par seconde : 12361.
Écrit à : /tmcdata/mro2csv/output31/mro_0001.csv.
********************************************* **** ******
Le traitement du programme se termine.
L'analyse SAX a une durée d'exécution nettement plus courte que l'analyse DOM. Étant donné que SAX utilise l'analyse ligne par ligne, elle prend moins de mémoire pour traiter des fichiers plus volumineux. Par conséquent, l'analyse SAX est une méthode d'analyse actuellement utilisée. plus fréquemment. L'inconvénient est que vous devez implémenter la fonction de rappel vous-même et que la logique est relativement complexe.
3. Analyse ET
Code de définition de fonction :
def ET_parser(gz):
import os,gzip,cStringIO
import xml.etree.cElementTree as ET
vs_cnt = 0
str_s = ''
file_io = cStringIO.StringIO()
xm = gzip.open(gz,'rb')
print("已读入:%s.\n解析中:" % (os.path.abspath(gz)))
tree = ET.ElementTree(file=xm)
root = tree.getroot()
for elem in root[1][0].findall('object'):
for v in elem.findall('v'):
file_io.write(root[1].attrib['id']+' '+elem.attrib['TimeStamp']+' '+elem.attrib['MmeCode']+' '+\
elem.attrib['id']+' '+ elem.attrib['MmeUeS1apId']+' '+ elem.attrib['MmeGroupId']+' '+ v.text+'\n')
vs_cnt += 1
str_s = file_io.getvalue().replace(' \n','\r\n').replace(' ',',').replace('T',' ').replace('NIL','') #写入解析后内容
xm.close()
file_io.close()
return (str_s,vs_cnt)Résultat de l'exécution du programme :
*********** **************************************
Le traitement du programme démarre.
Le répertoire d'entrée est : /tmcdata/mro2csv/input31/.
Le répertoire de sortie est : /tmcdata/mro2csv/output31/.
Le nombre de fichiers .gz dans le répertoire d'entrée est : 12, 12 d'entre eux seront traités cette fois.
********************************************* **** ******
Nombre de fichiers : 1/12.
Lire dans : /tmcdata/mro2csv/input31/TD-LTE_MRO_NSN_OMC_234598_20160224060000.xml.gz.
Analyse :
Nombre de fichiers : 2/12.
Lire dans :/tmcdata/mro2csv/input31/TD-LTE_MRO_NSN_OMC_233798_20160224060000.xml.gz.
Analyse :
Nombre de fichiers : 3/12.
Lire dans : /tmcdata/mro2csv/input31/TD-LTE_MRO_NSN_OMC_123798_20160224060000.xml.gz.
Analyse :
...........................................
文件计数:12/12.
已读入:/tmcdata/mro2csv/input31/TD-LTE_MRO_NSN_OMC_235598_20160224060000.xml.gz.
解析中:
VS行计数:177849,运行时间:4.308103,每秒处理行数:41282。
已写入:/tmcdata/mro2csv/output31/mro_0001.csv。
**************************************************
程序处理结束。
相较于SAX解析,ET解析时间更短,并且函数实现也比较简单,所以ET具有类似DOM的简单逻辑实现且匹敌SAX的解析效率,因此ET是目前XML解析的首选。
4、ET_iter解析
函数定义代码:
def ET_parser_iter(gz):
import os,gzip,cStringIO
import xml.etree.cElementTree as ET
vs_cnt = 0
str_s = ''
file_io = cStringIO.StringIO()
xm = gzip.open(gz,'rb')
print("已读入:%s.\n解析中:" % (os.path.abspath(gz)))
d_eNB = {}
d_obj = {}
i = 0
for event,elem in ET.iterparse(xm,events=('start','end')):
if i >= 2:
break
elif event == 'start':
if elem.tag == 'eNB':
d_eNB = elem.attrib
elif elem.tag == 'object':
d_obj = elem.attrib
elif event == 'end' and elem.tag == 'smr':
i += 1
elif event == 'end' and elem.tag == 'v':
file_io.write(d_eNB['id']+' '+d_obj['TimeStamp']+' '+d_obj['MmeCode']+' '+d_obj['id']+' '+\
d_obj['MmeUeS1apId']+' '+ d_obj['MmeGroupId']+' '+str(elem.text)+'\n')
vs_cnt += 1
elem.clear()
str_s = file_io.getvalue().replace(' \n','\r\n').replace(' ',',').replace('T',' ').replace('NIL','') #写入解析后内容
xm.close()
file_io.close()
return (str_s,vs_cnt)程序运行结果:
**************************************************
程序处理启动。
输入目录为:/tmcdata/mro2csv/input31/。
输出目录为:/tmcdata/mro2csv/output31/。
输入目录下.gz文件个数为:12,本次处理其中的12个。
**************************************************
文件计数:1/12.
已读入:/tmcdata/mro2csv/input31/TD-LTE_MRO_NSN_OMC_234598_20160224060000.xml.gz.
解析中:
文件计数:2/12.
已读入:/tmcdata/mro2csv/input31/TD-LTE_MRO_NSN_OMC_233798_20160224060000.xml.gz.
解析中:
文件计数:3/12.
已读入:/tmcdata/mro2csv/input31/TD-LTE_MRO_NSN_OMC_123798_20160224060000.xml.gz.
解析中:
...................................................
文件计数:12/12.
已读入:/tmcdata/mro2csv/input31/TD-LTE_MRO_NSN_OMC_235598_20160224060000.xml.gz.
解析中:
VS行计数:177849,运行时间:3.043805,每秒处理行数:58429。
已写入:/tmcdata/mro2csv/output31/mro_0001.csv。
**************************************************
程序处理结束。
在引入了ET_iter解析后,解析效率比ET提升了近50%,而相较于DOM解析更是提升了35倍,在解析效率提升的同时,由于其采用了iterparse这个循序解析的工具,其内存占用也是比较小的。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!