
Maison >développement back-end >Tutoriel Python >Résumé de huit algorithmes de tri en Python (Partie 2)
Résumé de huit algorithmes de tri en Python (Partie 2)
- 巴扎黑original
- 2017-09-16 10:14:441607parcourir
Cet article présente principalement en détail la deuxième partie des huit algorithmes de tri implémentés en Python. Il a une certaine valeur de référence. Les amis intéressés peuvent s'y référer
Cet article est la suite du blog python précédent, partie 1 de. les huit algorithmes de tri implémentés continueront à utiliser python pour implémenter les quatre autres algorithmes de tri : tri rapide, tri par tas, tri par fusion, tri par base
5, tri rapide
Le tri rapide est généralement considéré comme ayant la meilleure performance moyenne parmi les méthodes de tri du même ordre de grandeur (O(nlog2n)).
Idée algorithmique :
Nous connaissons un ensemble de données non ordonnées a[1], a[2],...a[n], qui doivent être classées par ordre croissant. Premièrement, toutes les données a[x] sont prises comme référence. Comparez a[x] avec d'autres données et triez-les de manière à ce que a[x] soit classé à la kème position des données, et placez chaque donnée dans a[1]~a[k-1] a[x], puis utilisez la stratégie diviser pour régner pour a[1]~a[k-1] et a[k+1]~a respectivement [n]Triez rapidement deux ensembles de données.
Avantages : extrêmement rapide, moins de mouvements de données
Inconvénients : instable ;
Implémentation du code Python :
def quick_sort(list):
little = []
pivotList = []
large = []
# 递归出口
if len(list) <= 1:
return list
else:
# 将第一个值做为基准
pivot = list[0]
for i in list:
# 将比基准小的值放到less数列
if i < pivot:
little.append(i)
# 将比基准大的值放到more数列
elif i > pivot:
large.append(i)
# 将和基准相同的值保存在基准数列
else:
pivotList.append(i)
# 对less数列和more数列继续进行快速排序
little = quick_sort(little)
large = quick_sort(large)
return little + pivotList + largeLe code suivant provient des trois lignes du "Python Cookbook Second Edition" pour implémenter le tri rapide Python.
#!/usr/bin/env python
#coding:utf-8
'''
file:python-8sort.py
date:9/1/17 9:03 AM
author:lockey
email:lockey@123.com
desc:python实现八大排序算法
'''
lst = [65,568,9,23,4,34,65,8,6,9]
def quick_sort(list):
if len(list) <= 1:
return list
else:
pivot = list[0]
return quick_sort([x for x in list[1:] if x < pivot]) + \
[pivot] + \
quick_sort([x for x in list[1:] if x >= pivot])Capture d'écran des résultats du test en cours d'exécution :
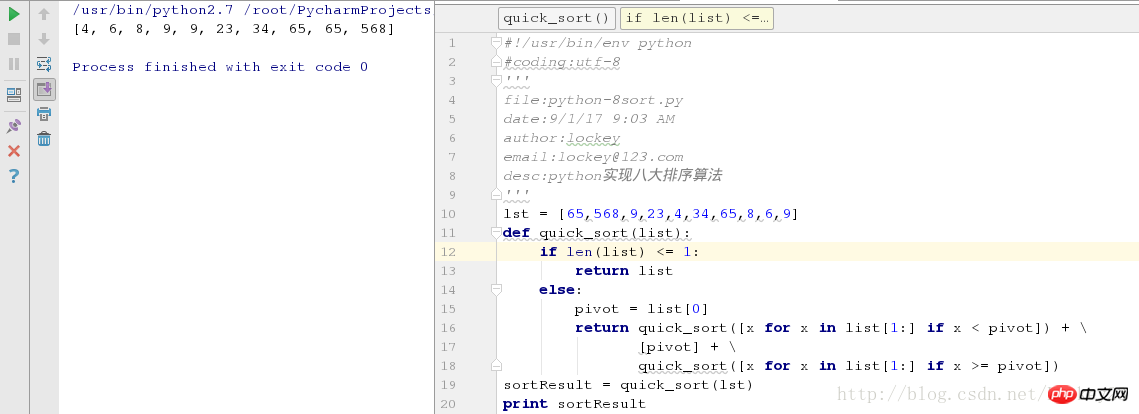
D'accord, il y a un sucre syntaxique plus rationalisé, une ligne Terminé :
quick_sort = lambda xs : ( (len(xs) = xs[0]] ) ] )[0]
Si la séquence initiale est ordonnée par clé ou fondamentalement ordonnée, le tri rapide dégénérera en tri à bulles. Afin de l'améliorer, la « méthode trois en un » est généralement utilisée pour sélectionner l'enregistrement de référence, c'est-à-dire que les trois clés d'enregistrement centrées sur les deux extrémités et le point médian de l'intervalle de tri sont ajustées en tant qu'enregistrement de point d'appui. Le tri rapide est une méthode de tri instable.
Dans l'algorithme amélioré, nous appellerons de manière récursive le tri rapide uniquement sur les sous-séquences d'une longueur supérieure à k pour rendre la séquence d'origine fondamentalement ordonnée, puis utiliserons l'algorithme de tri par insertion pour trier toute la séquence ordonnée de base. La pratique a prouvé que la complexité temporelle de l'algorithme amélioré a été réduite, et lorsque la valeur de k est d'environ 8, l'algorithme amélioré présente les meilleures performances.
6. Tri par tas
Le tri par tas est un tri par sélection arborescente, qui constitue une amélioration efficace du tri par sélection directe.
Avantages : Haute efficacité
Inconvénients : instabilité
Sous la définition du tas : une séquence de n éléments (h1, h2,...,hn), quand Et il est appelé uniquement lorsqu'il satisfait (hi>=h2i,hi>=2i+1) ou (hi
Idée algorithmique :
Initialement, la séquence de nombres à trier est considérée comme un arbre binaire stocké séquentiellement, et leur ordre de stockage est ajusté pour en faire un tas. Le nombre de nœuds racine dans le tas est le plus grand. Échangez ensuite le nœud racine avec le dernier nœud du tas. Réajustez ensuite les nombres précédents (n-1) pour former un tas. Et ainsi de suite, jusqu'à ce qu'il y ait un tas avec seulement deux nœuds, et qu'ils soient échangés, et finalement une séquence ordonnée de n nœuds est obtenue. D'après la description de l'algorithme, le tri du tas nécessite deux processus, l'un consiste à établir le tas et l'autre à échanger les positions entre le haut du tas et le dernier élément du tas. Le tri par tas se compose donc de deux fonctions. L'une est la fonction de pénétration pour construire le tas, et l'autre est la fonction permettant d'appeler à plusieurs reprises la fonction de pénétration pour implémenter le tri.
Implémentation du code python :
# -*- coding: UTF-8 -*-
'''
Created on 2017年9月2日
Running environment:win7.x86_64 eclipse python3
@author: Lockey
'''
lst = [65,568,9,23,4,34,65,8,6,9]
def adjust_heap(lists, i, size):# 调整堆
lchild = 2 * i + 1;rchild = 2 * i + 2
max = i
if i < size / 2:
if lchild < size and lists[lchild] > lists[max]:
max = lchild
if rchild < size and lists[rchild] > lists[max]:
max = rchild
if max != i:
lists[max], lists[i] = lists[i], lists[max]
adjust_heap(lists, max, size)
def build_heap(lists, size):# 创建堆
halfsize = int(size/2)
for i in range(0, halfsize)[::-1]:
adjust_heap(lists, i, size)
def heap_sort(lists):# 堆排序
size = len(lists)
build_heap(lists, size)
for i in range(0, size)[::-1]:
lists[0], lists[i] = lists[i], lists[0]
adjust_heap(lists, 0, i)
print(lists)Exemple de résultat :

7. Tri par fusion
Idée d'algorithme :
Le tri par fusion est un algorithme de tri efficace basé sur l'opération de fusion. L'algorithme utilise la méthode diviser pour régner. Une application très typique. Fusionnez les sous-séquences déjà ordonnées pour obtenir une séquence complètement ordonnée ; c'est-à-dire que vous devez d'abord rendre chaque sous-séquence ordonnée, puis ordonner les segments de la sous-séquence. Si deux listes ordonnées sont fusionnées en une seule liste ordonnée, on parle de fusion bidirectionnelle.
Le processus de fusion est le suivant : comparez les tailles de a[i] et a[j], si a[i]≤a[j], copiez l'élément a[i] dans la première liste ordonnée dans r [k], et ajoutez 1 à i et k respectivement ; sinon, copiez l'élément a[j] dans la deuxième liste ordonnée dans r[k], et ajoutez 1 à j et k respectivement. Ce cycle continue jusqu'à l'un des éléments ordonnés. lists est récupéré, puis les éléments restants de l’autre liste ordonnée sont copiés dans les cellules de r de l’indice k à l’indice t. Nous utilisons généralement la récursion pour implémenter l'algorithme de tri par fusion. Nous divisons d'abord l'intervalle à trier [s, t] en deux au milieu, puis trions la sous-plage de gauche, puis trions la sous-plage de droite et enfin utilisons a. opération de fusion entre l'intervalle gauche et l'intervalle droit Fusionner en intervalles ordonnés [s,t].
# -*- coding: UTF-8 -*-
'''
Created on 2017年9月2日
Running environment:win7.x86_64 eclipse python3
@author: Lockey
'''
lst = [65,568,9,23,4,34,65,8,6,9]
def merge(left, right):
i, j = 0, 0
result = []
while i < len(left) and j < len(right):
if left[i] <= right[j]:
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
result += left[i:]
result += right[j:]
print(result)
return result
def merge_sort(lists):# 归并排序
if len(lists) <= 1:
return lists
num = int(len(lists) / 2)
left = merge_sort(lists[:num])
right = merge_sort(lists[num:])
return merge(left, right)Exemple de résultats du programme :

8、桶排序/基数排序(Radix Sort)
优点:快,效率最好能达到O(1)
缺点:
1.首先是空间复杂度比较高,需要的额外开销大。排序有两个数组的空间开销,一个存放待排序数组,一个就是所谓的桶,比如待排序值是从0到m-1,那就需要m个桶,这个桶数组就要至少m个空间。
2.其次待排序的元素都要在一定的范围内等等。
算法思想:
是将阵列分到有限数量的桶子里。每个桶子再个别排序(有可能再使用别的排序算法或是以递回方式继续使用桶排序进行排序)。桶排序是鸽巢排序的一种归纳结果。当要被排序的阵列内的数值是均匀分配的时候,桶排序使用线性时间(Θ(n))。但桶排序并不是 比较排序,他不受到 O(n log n) 下限的影响。
简单来说,就是把数据分组,放在一个个的桶中,然后对每个桶里面的在进行排序。
例如要对大小为[1..1000]范围内的n个整数A[1..n]排序
首先,可以把桶大小设为10,这样就有100个桶了,具体而言,设集合B[1]存储[1..10]的整数,集合B[2]存储 (10..20]的整数,……集合B[i]存储( (i-1)*10, i*10]的整数,i = 1,2,..100。总共有 100个桶。
然后,对A[1..n]从头到尾扫描一遍,把每个A[i]放入对应的桶B[j]中。 再对这100个桶中每个桶里的数字排序,这时可用冒泡,选择,乃至快排,一般来说任 何排序法都可以。
最后,依次输出每个桶里面的数字,且每个桶中的数字从小到大输出,这 样就得到所有数字排好序的一个序列了。
假设有n个数字,有m个桶,如果数字是平均分布的,则每个桶里面平均有n/m个数字。如果
对每个桶中的数字采用快速排序,那么整个算法的复杂度是
O(n + m * n/m*log(n/m)) = O(n + nlogn - nlogm)
从上式看出,当m接近n的时候,桶排序复杂度接近O(n)
当然,以上复杂度的计算是基于输入的n个数字是平均分布这个假设的。这个假设是很强的 ,实际应用中效果并没有这么好。如果所有的数字都落在同一个桶中,那就退化成一般的排序了。
python代码实现:
# -*- coding: UTF-8 -*-
'''
Created on 2017年9月2日
Running environment:win7.x86_64 eclipse python3
@author: Lockey
'''
import math
lst = [65,56,9,23,84,34,8,6,9,54,11]
#因为列表数据范围在100以内,所以将使用十个桶来进行排序
def radix_sort(lists, radix=10):
k = int(math.ceil(math.log(max(lists), radix)))
bucket = [[] for i in range(radix)]
for i in range(1, k+1):
for j in lists:
gg = int(j/(radix**(i-1))) % (radix**i)
bucket[gg].append(j)
del lists[:]
for z in bucket:
lists += z
del z[:]
print(lists)
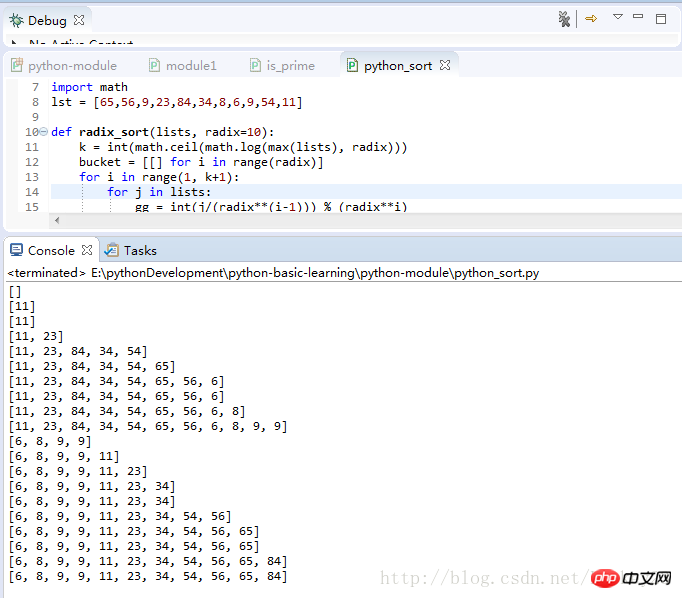
return lists程序运行测试结果:
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!