
Maison >Java >javaDidacticiel >Explication détaillée de la façon d'utiliser l'algorithme LRU en Java
Explication détaillée de la façon d'utiliser l'algorithme LRU en Java

- 黄舟original
- 2017-09-15 10:35:221976parcourir
Cet article présente principalement l'algorithme java LRU, présente brièvement le concept de l'algorithme LRU et analyse l'utilisation spécifique de l'algorithme LRU sous forme d'exemples. Les amis dans le besoin peuvent s'y référer
Les exemples. dans cet article, décrivez l'introduction Java et l'utilisation de l'algorithme LRU. Partagez-le avec tout le monde pour votre référence, les détails sont les suivants :
1.Avant-propos
Lorsque les utilisateurs utilisent un logiciel connecté à Internet, ils accédera toujours à Internet depuis Internet Lorsque les mêmes données doivent être utilisées plusieurs fois au cours d'une période donnée, il est impossible pour l'utilisateur d'aller en ligne pour demander à chaque fois, ce qui est une perte de temps et de réseau
À ce stade, vous pouvez Les données demandées par l'utilisateur sont enregistrées, mais toutes les données ne sont pas enregistrées, ce qui entraînera un gaspillage de mémoire. L’idée de l’algorithme LRU peut être appliquée.
2. Introduction à LRU
LRU est l'algorithme le moins récemment utilisé, qui peut traiter des données qui n'ont pas été utilisées depuis longtemps. . supprimer.
LRU se reflète également bien dans les émotions de certaines personnes. Lorsque vous êtes en contact avec un groupe d'amis, la relation avec les personnes avec lesquelles vous communiquez souvent est très bonne. Si vous ne les contactez pas pendant une longue période et que vous ne les recontacterez probablement plus, vous aurez perdu cela. ami.
3. Le code suivant montre l'algorithme LRU :
Le moyen le plus simple est d'utiliser LinkHashMap, car il a lui-même une méthode. pour supprimer les anciennes données supplémentaires dans la plage de cache définie
public class LRUByHashMap<K, V> {
/*
* 通过LinkHashMap简单实现LRU算法
*/
/**
* 缓存大小
*/
private int cacheSize;
/**
* 当前缓存数目
*/
private int currentSize;
private LinkedHashMap<K, V> maps;
public LRUByHashMap(int cacheSize1) {
this.cacheSize = cacheSize1;
maps = new LinkedHashMap<K, V>() {
/**
*
*/
private static final long serialVersionUID = 1;
// 这里移除旧的缓存数据
@Override
protected boolean removeEldestEntry(java.util.Map.Entry<K, V> eldest) {
// 当超过缓存数量的时候就将旧的数据移除
return getCurrentSize() > LRUByHashMap.this.cacheSize;
}
};
}
public synchronized int getCurrentSize() {
return maps.size();
}
public synchronized void put(K k, V v) {
if (k == null) {
throw new Error("存入的键值不能为空");
}
maps.put(k, v);
}
public synchronized void remove(K k) {
if (k == null) {
throw new Error("移除的键值不能为空");
}
maps.remove(k);
}
public synchronized void clear() {
maps = null;
}
// 获取集合
public synchronized Collection<V> getCollection() {
if (maps != null) {
return maps.values();
} else {
return null;
}
}
public static void main(String[] args) {
// 测试
LRUByHashMap<Integer, String> maps = new LRUByHashMap<Integer, String>(
3);
maps.put(1, "1");
maps.put(2, "2");
maps.put(3, "3");
maps.put(4, "4");
maps.put(5, "5");
maps.put(6, "6");
Collection<String> col = maps.getCollection();
System.out.println("存入缓存中的数据是--->>" + col.toString());
}
}L'effet après l'exécution :
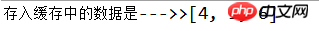
Le code évidemment mis 6 entrées mais seulement trois ont été affichées à la fin. Les trois entre les deux étaient anciennes et ont été cliquées
La deuxième méthode consiste à utiliser une liste doublement chaînée + HashTable
La fonction de la liste doublement chaînée sert à enregistrer l'emplacement, tandis que la HashTable est utilisée comme conteneur pour stocker les données
Pourquoi utiliser HashTable au lieu de HashMap ?
1. Les clés et valeurs de HashTable ne peuvent pas être nulles ;
2. Le LRU implémenté ci-dessus à l'aide de LinkHashMap est utile pour la synchronisation, permettant aux threads de traiter de manière synchrone, évitant ainsi le besoin de multi-threads. pour traiter des données unifiées. Provoque des problèmes
HashTable possède son propre mécanisme de synchronisation, afin que les multithreads puissent traiter correctement HashTable.
Tous les caches sont connectés à des listes chaînées doubles positionnelles. Lorsqu'une position est atteinte, la position sera ajustée à la position de la tête de la liste chaînée en ajustant le pointage de la liste chaînée. sera ajouté directement en tête de la liste chaînée. De cette façon, après plusieurs opérations de cache,
qui a été touché récemment sera déplacé vers la tête de la liste chaînée, tandis que ceux qui ne sont pas touchés seront déplacés vers la fin de la liste chaînée. de la liste chaînée représente le Cache le moins récemment utilisé. Lorsque le contenu doit être remplacé, la dernière position de la liste chaînée est la position la moins touchée. Il suffit d'éliminer
la dernière partie de la liste chaînée
public class LRUCache {
private int cacheSize;
private Hashtable<Object, Entry> nodes;//缓存容器
private int currentSize;
private Entry first;//链表头
private Entry last;//链表尾
public LRUCache(int i) {
currentSize = 0;
cacheSize = i;
nodes = new Hashtable<Object, Entry>(i);//缓存容器
}
/**
* 获取缓存中对象,并把它放在最前面
*/
public Entry get(Object key) {
Entry node = nodes.get(key);
if (node != null) {
moveToHead(node);
return node;
} else {
return null;
}
}
/**
* 添加 entry到hashtable, 并把entry
*/
public void put(Object key, Object value) {
//先查看hashtable是否存在该entry, 如果存在,则只更新其value
Entry node = nodes.get(key);
if (node == null) {
//缓存容器是否已经超过大小.
if (currentSize >= cacheSize) {
nodes.remove(last.key);
removeLast();
} else {
currentSize++;
}
node = new Entry();
}
node.value = value;
//将最新使用的节点放到链表头,表示最新使用的.
node.key = key
moveToHead(node);
nodes.put(key, node);
}
/**
* 将entry删除, 注意:删除操作只有在cache满了才会被执行
*/
public void remove(Object key) {
Entry node = nodes.get(key);
//在链表中删除
if (node != null) {
if (node.prev != null) {
node.prev.next = node.next;
}
if (node.next != null) {
node.next.prev = node.prev;
}
if (last == node)
last = node.prev;
if (first == node)
first = node.next;
}
//在hashtable中删除
nodes.remove(key);
}
/**
* 删除链表尾部节点,即使用最后 使用的entry
*/
private void removeLast() {
//链表尾不为空,则将链表尾指向null. 删除连表尾(删除最少使用的缓存对象)
if (last != null) {
if (last.prev != null)
last.prev.next = null;
else
first = null;
last = last.prev;
}
}
/**
* 移动到链表头,表示这个节点是最新使用过的
*/
private void moveToHead(Entry node) {
if (node == first)
return;
if (node.prev != null)
node.prev.next = node.next;
if (node.next != null)
node.next.prev = node.prev;
if (last == node)
last = node.prev;
if (first != null) {
node.next = first;
first.prev = node;
}
first = node;
node.prev = null;
if (last == null)
last = first;
}
/*
* 清空缓存
*/
public void clear() {
first = null;
last = null;
currentSize = 0;
}
}
class Entry {
Entry prev;//前一节点
Entry next;//后一节点
Object value;//值
Object key;//键
}Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!