
Maison >développement back-end >Tutoriel Python >Introduction à l'utilisation de Numpy et Pandas en python
Introduction à l'utilisation de Numpy et Pandas en python
- 巴扎黑original
- 2017-09-13 10:04:382881parcourir
Récemment, j'ai besoin de comparer une série de données d'une année sur l'autre et j'ai besoin d'utiliser numpy et pandas pour le calcul. L'article suivant vous présente principalement les informations pertinentes sur l'utilisation de Numpy et Pandas dans python. tutoriel d'apprentissage. L'article le présente à travers un exemple de code. Très détaillé, les amis dans le besoin peuvent s'y référer.
Avant-propos
Cet article présente principalement des informations pertinentes sur l'utilisation de Numpy et Pandas en python, et les partage pour votre référence et votre étude. Ci-dessous Pas grand chose à dire, jetons un œil à l'introduction détaillée.
Qu'est-ce que c'est ?
NumPy est une bibliothèque d'extensions pour le langage Python. Il prend en charge les opérations avancées de tableaux et de matrices dimensionnelles à grande échelle, et fournit également un grand nombre de bibliothèques de fonctions mathématiques pour les opérations sur les tableaux.
Pandas est un outil basé sur NumPy qui a été créé pour résoudre des tâches d'analyse de données. Pandas intègre un certain nombre de bibliothèques et certains modèles de données standard pour fournir les outils nécessaires pour manipuler efficacement de grands ensembles de données. Pandas fournit un grand nombre de fonctions et de méthodes qui nous permettent de traiter les données rapidement et facilement.
List, Numpy et Pandas
Numpy et List
Identité :
tous les éléments peuvent accéder à l'aide d'indices, tels que a[0]
-
sont tous accessibles par découpage, comme a[1:3]
peut être parcouru à l'aide d'une boucle for
La différence :
Chaque élément dans Numpy Les types doit être identique ; plusieurs éléments de type peuvent être mélangés dans List
Numpy est plus pratique à utiliser et encapsule de nombreuses fonctions, telles que moyenne, std, somme, min, max, etc.
Numpy peut être un tableau multidimensionnel
Numpy est implémenté en C et fonctionne plus rapidement
Pandas est identique à Numpy
:
est identique à l'accès aux éléments. Vous pouvez utiliser des indices ou des tranches pour accéder à
- Vous pouvez utiliser une boucle For pour parcourir
- Il existe de nombreuses fonctions pratiques, telles que moyenne, std, somme, min, max, etc.
- Les opérations vectorielles peuvent être effectuées
- implémentées en C, ce qui est plus rapide
Utiliser Numpy
Opérations de base
import numpy as np #创建Numpy p1 = np.array([1, 2, 3]) print p1 print p1.dtype
[1 2 3] int64
#求平均值 print p1.mean()
2.0
#求标准差 print p1.std()
0.816496580928
#求和、求最大值、求最小值 print p1.sum() print p1.max() print p1.min()
6 3 1
#求最大值所在位置 print p1.argmax()
2
2. Opérations vectorielles
p1 = np.array([1, 2, 3]) p2 = np.array([2, 5, 7])
#向量相加,各个元素相加 print p1 + p2
[ 3 7 10]
#向量乘以1个常数 print p1 * 2
[2 4 6]
#向量相减 print p1 - p2
[-1 -3 -4]
#向量相乘,各个元素之间做运算 print p1 * p2
[ 2 10 21]
#向量与一个常数比较 print p1 > 2
[False False True]
3. Tableau d'index
Tout d'abord, regardez l'image ci-dessous pour comprendre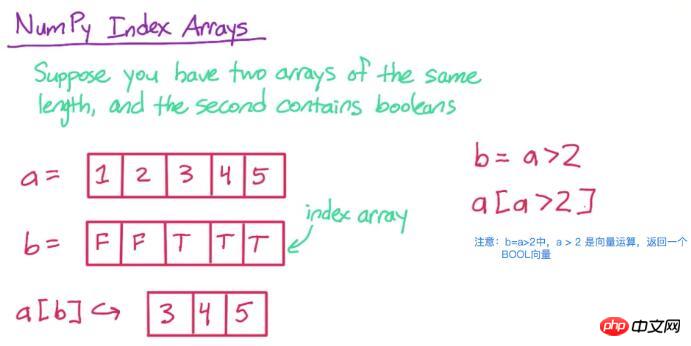
a = np.array([1, 2, 3, 4, 5]) print a
[1 2 3 4 5]
Dans un[b] , seuls ceux correspondants dans a seront retenus. Éléments dont la position b est vraie
b = a > 2 print b
4. Sur place et non sur place
[False False True True True]Regardons d'abord a ensemble d'opérations :
print a[b]
[3 4 5]
Comme vous pouvez le voir d'après les résultats ci-dessus, Out, += modifie le tableau d'origine, mais + ne le fait pas. En effet :
a = np.array([1, 2, 3, 4]) b = a a += np.array([1, 1, 1, 1]) print b
+= : il est calculé sur place et ne crée pas de nouveau tableau, modifiant les éléments du tableau d'origine
[2 3 4 5]
+ : C'est un calcul non-in-place, il créera un nouveau tableau et ne modifiera pas les éléments du tableau d'origine
a = np.array([1, 2, 3, 4]) b = a a = a + np.array([1, 1, 1, 1]) print b
[1 2 3 4]
Il ressort de ce qui précède que la modification des éléments de la tranche dans List n'affectera pas le tableau d'origine ; tandis que Numpy modifie les éléments de la tranche, et le tableau d'origine changera également. En effet, la programmation des tranches de Numpy ne crée pas de nouveau tableau et la modification de la tranche correspondante modifiera également les données du tableau d'origine. Ce mécanisme peut rendre Numpy plus rapide que les opérations de tableau natives, mais vous devez faire attention lors de la programmation.
l1 = [1, 2, 3, 5] l2 = l1[0:2] l2[0] = 5 print l2 print l1
6. Opérations sur les tableaux bidimensionnels
p1 = np.array([[1, 2, 3], [7, 8, 9], [2, 4, 5]]) #获取其中一维数组 print p1[0]
[1 2 3]
#获取其中一个元素,注意它可以是p1[0, 1],也可以p1[0][1] print p1[0, 1] print p1[0][1]
2 2
#求和是求所有元素的和 print p1.sum()
41 [10 14 17]
但,当设置axis参数时,当设置为0时,是计算每一列的结果,然后返回一个一维数组;若是设置为1时,则是计算每一行的结果,然后返回一维数组。对于二维数组,Numpy中很多函数都可以设置axis参数。
#获取每一列的结果 print p1.sum(axis=0)
[10 14 17]
#获取每一行的结果 print p1.sum(axis=1)
[ 6 24 11]
#mean函数也可以设置axis print p1.mean(axis=0)
[ 3.33333333 4.66666667 5.66666667]
Pandas使用
Pandas有两种结构,分别是Series和DataFrame。其中Series拥有Numpy的所有功能,可以认为是简单的一维数组;而DataFrame是将多个Series按列合并而成的二维数据结构,每一列单独取出来是一个Series。
咱们主要梳理下Numpy没有的功能:
1、简单基本使用
import pandas as pd pd1 = pd.Series([1, 2, 3]) print pd1
0 1 1 2 2 3 dtype: int64
#也可以求和和标准偏差 print pd1.sum() print pd1.std()
6 1.0
2、索引
(1)Series中的索引
p1 = pd.Series( [1, 2, 3], index = ['a', 'b', 'c'] ) print p1
a 1 b 2 c 3 dtype: int64
print p1['a']
(2)DataFrame数组
p1 = pd.DataFrame({
'name': ['Jack', 'Lucy', 'Coke'],
'age': [18, 19, 21]
})
print p1age name 0 18 Jack 1 19 Lucy 2 21 Coke
#获取name一列 print p1['name']
0 Jack 1 Lucy 2 Coke Name: name, dtype: object
#获取姓名的第一个 print p1['name'][0]
Jack
#使用p1[0]不能获取第一行,但是可以使用iloc print p1.iloc[0]
age 18 name Jack Name: 0, dtype: object
总结:
获取一列使用p1[‘name']这种索引
获取一行使用p1.iloc[0]
3、apply使用
apply可以操作Pandas里面的元素,当库里面没用对应的方法时,可以通过apply来进行封装
def func(value): return value * 3 pd1 = pd.Series([1, 2, 5])
print pd1.apply(func)
0 3 1 6 2 15 dtype: int64
同样可以在DataFrame上使用:
pd2 = pd.DataFrame({
'name': ['Jack', 'Lucy', 'Coke'],
'age': [18, 19, 21]
})
print pd2.apply(func)age name 0 54 JackJackJack 1 57 LucyLucyLucy 2 63 CokeCokeCoke
4、axis参数
Pandas设置axis时,与Numpy有点区别:
当设置axis为'columns'时,是计算每一行的值
当设置axis为'index'时,是计算每一列的值
pd2 = pd.DataFrame({
'weight': [120, 130, 150],
'age': [18, 19, 21]
})0 138 1 149 2 171 dtype: int64
#计算每一行的值 print pd2.sum(axis='columns')
0 138 1 149 2 171 dtype: int64
#计算每一列的值 print pd2.sum(axis='index')
age 58 weight 400 dtype: int64
5、分组
pd2 = pd.DataFrame({
'name': ['Jack', 'Lucy', 'Coke', 'Pol', 'Tude'],
'age': [18, 19, 21, 21, 19]
})
#以年龄分组
print pd2.groupby('age').groups{18: Int64Index([0], dtype='int64'), 19: Int64Index([1, 4], dtype='int64'), 21: Int64Index([2, 3], dtype='int64')}6、向量运算
需要注意的是,索引数组相加时,对应的索引相加
pd1 = pd.Series( [1, 2, 3], index = ['a', 'b', 'c'] ) pd2 = pd.Series( [1, 2, 3], index = ['a', 'c', 'd'] )
print pd1 + pd2
a 2.0 b NaN c 5.0 d NaN dtype: float64
出现了NAN值,如果我们期望NAN不出现,如何处理?使用add函数,并设置fill_value参数
print pd1.add(pd2, fill_value=0)
a 2.0 b 2.0 c 5.0 d 3.0 dtype: float64
同样,它可以应用在Pandas的dataFrame中,只是需要注意列与行都要对应起来。
总结
这一周学习了优达学城上分析基础的课程,使用的是Numpy与Pandas。对于Numpy,以前在Tensorflow中用过,但是很不明白,这次学习之后,才知道那么简单,算是有一定的收获。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!