
Maison >base de données >tutoriel mysql >Une étude préliminaire sur le moteur de stockage MySQL
Une étude préliminaire sur le moteur de stockage MySQL
- 一个新手original
- 2017-09-08 11:10:481382parcourir
Une étude préliminaire sur le moteur de stockage MySQL
Répertoire :
1. Introduction aux moteurs de stockage
2. Comparaison des performances d'InnoDB et MyISAM
3, Comparaison des verrous entre MyISAM et InnoDB
4. Comparaison des index de deux moteurs de stockage
1 Présentation du moteur de stockage
Description : Base de données MySQL basée sur 5.7.19 .
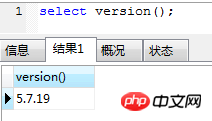
Figure 1.1 Version de la base de données
Testé dans Navicat pour MySQL :
Entrée SQL : afficher les moteurs ;
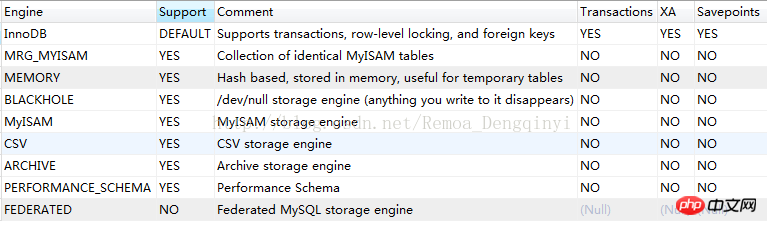
Figure 1.2 Catégorie de moteur de stockage
Description du paramètre :
Moteur : Nom du moteur de stockage
Support : Indique si MySQL le prend en charge. moteur
Commentaire : Description du moteur
Transaction : Indique si le traitement des transactions est pris en charge
XA : Qu'il s'agisse du traitement des transactions distribuées >
lInnoDB
Convient à
environnement de traitement des transactions et hautes performances, prend en charge la clé externe, le moteur de stockage par défaut, "prêt à l'emploi".
lMyISAMprincipalement des données en lecture seuleconvient aux
dans les applications d'entrepôt, de commerce électronique et d'entreprise. MyISAM utilise des mécanismes avancés de mise en cache et d'indexation pour améliorer la vitesse de récupération et d'indexation des données, mais ne prend pas en charge les transactions ou les clés étrangères.
lBlackholeL'application de test écrit en effet des scénarios de données où vous ne souhaitez stocker aucune donnée sur le disqueS'applique à
. Le moteur de stockage Blackhole répond à une exigence spécifique. Si la journalisation binaire est activée, les instructions SQL seront écrites dans le journal, en utilisant le moteur de stockage Blackhole comme relais ou proxy dans une topologie de réplication. Dans ce cas, l'agent relais traite les données du maître et envoie les données à ses esclaves, mais il ne stocke lui-même aucune donnée.
lCSVl'écriture de fichiers journaux CSV et la conversion la structure Importez rapidement des données commerciales dans des feuilles de calculconvient à
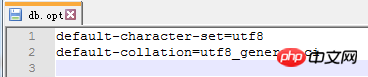
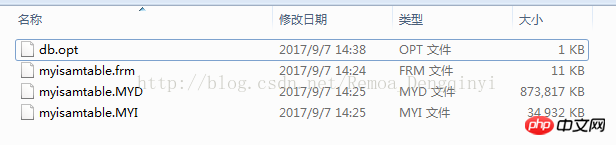
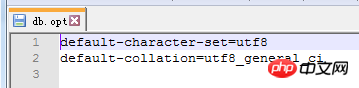
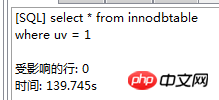
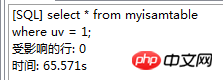
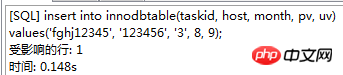
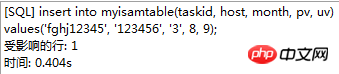
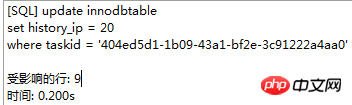
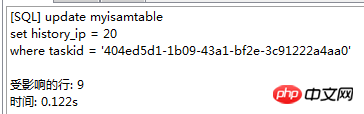
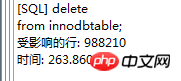
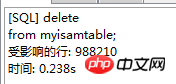
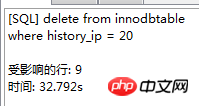
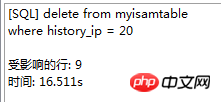
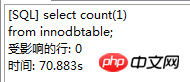
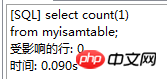
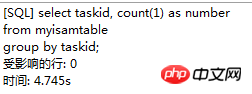
. Le moteur de stockage CSV crée, lit et écrit des fichiers CSV (valeurs séparées par des virgules) au format tabulaire. Il ne fournit aucun mécanisme d'indexation, présente certains problèmes lors du stockage et de la conversion des valeurs datetime et n'est pas efficace pour stocker les données, il doit donc être utilisé avec prudence. l Mémoire Applicable aux données statiques fréquemment consultées et rarement modifiées, telles que la liste des codes postaux, la liste des provinces et des villes, la liste de classification, etc., ainsi que des bases de données adaptées à utilisant la technologie d'instantané pour accéder aux données de distribution ou aux données historiques . La mémoire (parfois appelée HEAP) est un stockage en mémoire qui utilise un mécanisme de hachage pour récupérer les données fréquemment utilisées, permettant une récupération plus rapide. Étant donné que les données sont stockées en mémoire et ne sont valides que dans la session MySQL, les données sont actualisées et supprimées lors de l'arrêt. l Fédéré Convient aux environnements distribués ou d'ensembles de données . Le moteur de stockage fédéré permet de joindre des tables de plusieurs serveurs de bases de données. Il ne déplace pas les données et ne nécessite pas que la table distante utilise le même moteur de stockage. Le moteur de stockage fédéré est actuellement désactivé dans la plupart des distributions de MySQL. l Archive convient au stocker et récupérer de grandes quantités de très peu accèdent aux données archivées ou historiques. Le moteur de stockage d'archives stocke de grandes quantités de données dans un format compressé, ne prend pas en charge les index et n'est accessible que via des analyses de tables. l MRG_MYISAM Convient aux applications de très grandes bases de données , tel qu'un entrepôt de données, dans lequel les données sont stockées dans plusieurs tables d'une ou plusieurs bases de données. La meilleure caractéristique du moteur de stockage MRG_MYISAM est sa rapidité. Il divise une grande table en plusieurs petites tables différentes, les stocke sur différents disques, fusionne ces petites tables, puis y accède en même temps. La recherche et le tri sont effectués plus rapidement. Parce que chaque petite table doit gérer moins de données. Inconvénients : l La même table MyISAM doit être utilisée pour former une table composite l L'opération de remplacement n'est pas disponible l L'index est moins efficace que l'index d'une seule table ; Remarque : La table de test contient 36 champs, et contient 988218 enregistrements . La base de données de test du moteur de stockage InnoDB s'appelle Innodbtest, qui contient cette table, et le nom de la table est Innodbtable ; la base de données de test du moteur de stockage MyISAM s'appelle Myisamtest, qui contient cette table ; , et le nom de la table est Myisamtable. Utilisez les moteurs de stockage InnoDB et MyISAM dans MySQL pour tester la table. Tout d'abord, effectuez le travail préliminaire : (1) Testez le stockage. Le moteur de la table du moteur de stockage MyISAM passe de InnoDB par défaut à MyISAM : Figure 2.1 Modifier le moteur de stockage (2) Modifier le codage de caractères de la base de données et le définir sur utf-8 Figure 2.2 Modifier le caractère de la bibliothèque de test du moteur de stockage InnoDB encodage Figure 2.3 Modifier le codage des caractères de la bibliothèque de test du moteur de stockage MyISAM Certains des deux moteurs de stockage Caractéristiques pour les tests : l Structure de stockage (1) InnoDB : Les données de la table sont stockées dans un fichier de données d'une taille de 1,21 Go - Innodbtable.ibd Les informations de métadonnées liées à la table sont stockées dans le fichier innodbtable.frm, y compris la définition de la structure de la table. . information. Certaines informations de définition de la base de données sont définies dans db.opt. Figure 2.4 Répertoire de stockage sur disque InnoDB Figure 2.5 Contenu du fichier db.opt (2) MyISAM : Fichier .frm : Stocke les informations de métadonnées liées à la table, y compris les informations de définition de la structure de la table, etc. ; Fichier .MYD : d'une taille de 853,34 Mo, stocke les données de la table MyISAM. Fichier .MYI : d'une taille de 34,11 Mo, qui stocke les informations relatives à l'index de la table MyISAM. db.opt : Définit certaines informations de définition de la base de données. Figure 2.6 Répertoire de stockage sur disque MyISAM Figure 2.7 Contenu du fichier db.opt l sélectionnez (1) InnoDB : Figure 2.8 Test de sélection InnoDB (2) MyISAM : Figure 2.9 Test de sélection MyISAM l insérer (1) InnoDB : Figure 2.10 Test d'insertion InnoDB (2) MyISAM : Figure 2.11 Test d'insertion MyISAM l mise à jour (1) InnoDB : Figure 2.12 Test de mise à jour d'InnoDB (2) MyISAM : Figure 2.13 Test de mise à jour MyISAM l supprimer (1) InnoDB : Figure 2.14 Test de suppression d'InnoDB (2) MyISAM : Figure 2.15 Test de suppression MyISAM l supprimer où (1) InnoDB : Figure 2.16 Suppression d'InnoDB où tester (2) MyISAM : Figure 2.17 MyISAM supprimer où test je compte sans où (1) InnoDB : Figure 2.18 Décompte InnoDB sans où tester (2) MyISAM : Figure 2.19 Compte MyISAM sans test Where l group by (1)InnoDB: 图2.20 InnoDB的group by测试 (2)MyISAM: 图2.21 MyISAM的group by测试 l 外键 创建一个新表,将测试表的主键作为新表的外键进行测试: (1)InnoDB: 图2.22 InnoDB的外键测试 (2)MyISAM: 图2.23 MyISAM的外键测试 总结如下表: InnoDB MyISAM 存储结构 .ibd:存放表数据; .frm文件:存储与表相关的元数据信息,包括表结构的定义信息等; 基于磁盘的资源是InnoDB表空间数据文件和它的日志文件,InnoDB表的大小只受限于操作系统文件的大小,一般为2GB。 每个表在磁盘上存储成三个文件: .MYD文件:存放表的数据。 .MYI文件:存放表的索引相关信息。 .frm文件:存储与表相关的元数据信息,包括表结构的定义信息等; 存储空间 Les tables InnoDB nécessitent plus de mémoire et de stockage sur disque, et elles établiront son propre pool de tampons dédié dans la mémoire principale pour la mise en cache des données et des index. MyISAM peut être compressé et dispose d'un espace de stockage plus petit. Portabilité Gratuit les solutions peuvent consister à copier des fichiers de données, à sauvegarder le binlog ou à utiliser mysqldump, ce qui est relativement difficile lorsque le volume de données atteint des dizaines de gigaoctets En raison de MyISAM Les données est stocké sous forme de fichiers, il est donc très pratique pour le transfert de données multiplateforme. Les opérations peuvent être effectuées sur une table individuellement lors de la sauvegarde et de la récupération Sécurité des transactions Prise en charge des transactions, avec transaction (commit), rollback (rollback) et capacités de réparation en cas de crash Ne prend pas en charge les transactions, chaque requête est atomique augmentation Mieux (0,15 seconde) (0,40 seconde) Supprimer (avec où) (32,79 secondes) Mieux (16,51 secondes) Supprimer tout (263,86 secondes) est meilleur (0,24 seconde) ) Modifier (0,20 seconde) Mieux (0,12 secondes) Vérifiez (139,75 secondes) Plus Excellent (65,57 secondes) Verrouillage Supports Les verrous de table et les verrous de ligne améliorent considérablement les capacités des opérations simultanées multi-utilisateurs. Cependant, le verrouillage de ligne d'InnoDB n'est valable que sur la clé primaire de WHERE. Toute clé non primaire WHERE verrouillera la table entière. Prend en charge uniquement les verrous de table, sauf Clés Supportées Non prises en charge compter sans où Pas de table de sauvegarde spécifique le nombre de lignes doit être analysé ligne par ligne pour les statistiques (70,88 secondes) est préférable car MyISAM enregistre le numéro de ligne spécifique de la table et n'a besoin que de être lu simplement. (0,09 seconde) regrouper par (35,14 secondes) Mieux (4,75 secondes) Remarque : [1]Espace table : Un outil utilisé par InnoDB pour organiser des fichiers indépendants de la machine, y compris des données, des index et des retours mécanisme de roulement. Par défaut, toutes les tables partagent un espace table (appelé espace table partagé). Les espaces de table partagés ne se développent pas automatiquement en plusieurs fichiers. Par défaut, un tablespace n'occupe qu'un seul fichier, qui grandit à mesure que les données augmentent. Utilisez l'option d'extension automatique pour permettre au tablespace de créer de nouveaux fichiers. [2]Capacité de réparation de crash : Le moteur de stockage InnoDB utilise deux mécanismes basés sur disque pour stocker les données, à savoir les fichiers journaux et les espaces table. InnoDB utilisera ces journaux pour reconstruire la récupération des données avant de s'arrêter ou de planter. Au démarrage du programme, InnoDB lit le journal et écrit automatiquement les pages sales sur le disque, restaurant ainsi les mises à jour mises en mémoire tampon avant une panne du système. (1) Verrouillage au niveau de la table : faible surcharge, verrouillage rapide ; pas de blocage ; grande granularité de verrouillage, probabilité de conflit de verrouillage la plus élevée et concurrence la plus faible. (2) Verrous au niveau des lignes : une surcharge élevée et des blocages lents peuvent se produire ; la granularité du verrouillage est la plus petite, la probabilité de conflits de verrouillage est la plus faible et la concurrence est la plus faible ; le plus haut. (3) Les opérations de lecture sur la table MyISAM ne bloqueront pas les demandes de lecture des autres utilisateurs pour la même table, mais bloqueront les opérations d'écriture sur la même table MyISAM ; , bloquera les demandes de lecture et d'écriture des autres utilisateurs pour la même table ; les opérations de lecture et d'écriture de la table MyISAM, et les opérations d'écriture et d'écriture sont en série (lorsqu'un thread obtient un verrou en écriture sur une table, seul le thread détenant le lock peut mettre à jour la table. Les opérations de lecture et d'écriture des autres threads attendront que le verrou soit libéré) (4) Verrou(s) partagé(s) : permet à une transaction de lire une ligne. , empêchant d'autres transactions d'obtenir un verrou exclusif sur le même ensemble de données. (5) Verrouillage exclusif (X) : autorise les transactions qui acquièrent des verrous exclusifs à mettre à jour les données et empêche d'autres transactions d'acquérir le même verrou de lecture partagé et le même verrou d'écriture exclusif de l'ensemble de données. (6) Pour les instructions UPDATE, DELETE et INSERT, InnoDB ajoutera automatiquement des verrous exclusifs (X) aux ensembles de données impliqués pour les instructions SELECT ordinaires, InnoDB n'ajoutera aucun verrou. l InnoDB : l Dans InnoDB, le fichier de données de la table lui-même est une structure d'index organisée par B+Tree Cet arbre Le nœud feuille. Le champ de données stocke des enregistrements de données complets. La clé de cet index est la clé primaire de la table de données, donc le fichier de données de la table InnoDB lui-même est l'index primaire. l L'index utilisé par la table InnoDB est un index clusterisé. Un index clusterisé est une structure de données qui stocke non seulement l'index, mais également les données elles-mêmes. Par conséquent, une fois qu'une valeur dans l'index est localisée, les données peuvent être récupérées directement sans recherche supplémentaire sur le disque. l L'index de clé primaire ou le premier index de la table est créé à l'aide d'un index clusterisé. l Tous les index auxiliaires d'InnoDB font référence à la clé primaire comme champ de données. Si un index auxiliaire est créé, les mots-clés de l'index clusterisé (clé primaire, clé unique ou ID de ligne) seront également stockés dans l'index auxiliaire, afin que vous puissiez effectuer une recherche rapide en fonction des mots-clés et obtenir rapidement les données originales dans le index clusterisé. Autrement dit, si vous utilisez la colonne de clé primaire pour analyser l'index auxiliaire, la requête n'a besoin que de l'index auxiliaire pour obtenir des données. l MyISAM : l Les fichiers d'index et les fichiers de données sont séparés, l'index Le fichier enregistre uniquement l'adresse de l'enregistrement de données. En utilisant B+tree comme structure d'index, le champ de données du nœud feuille stocke l'adresse de l'enregistrement de données. l Dans MyISAM, il n'y a pas de différence structurelle entre l'index primaire et l'index secondaire (clé secondaire), sauf que l'index primaire nécessite que la clé soit unique, tandis que la clé de l'index secondaire peut être répétée . l Principales différences : l La différence entre les index primaires : les fichiers de données d'InnoDB eux-mêmes sont des fichiers d'index. L'index et les données de MyISAM sont séparés. l La différence entre les index auxiliaires : le champ de données d'index auxiliaire d'InnoDB stocke la valeur de la clé primaire de l'enregistrement correspondant au lieu de l'adresse. Il n'y a pas beaucoup de différence entre l'index secondaire de MyISAM et l'index primaire. Remarque : Arbre B+ : Pour un arbre B+ d'ordre m, il a les éléments suivants caractéristiques : l Un nœud avec n sous-arbres contient n mots-clés. l Tous les nœuds feuilles contiennent des informations sur tous les mots-clés et des pointeurs vers des enregistrements contenant ces mots-clés. Et les nœuds feuilles eux-mêmes sont liés du plus petit au plus grand en fonction de la taille des mots-clés. l Tous les nœuds non terminaux peuvent être considérés comme des parties d'index, et le nœud ne contient que le plus grand (ou le plus petit) mot-clé dans son sous-arbre (nœud racine). l Dans l'arborescence B+, que la recherche aboutisse ou non, chaque recherche emprunte un chemin allant de la racine au nœud feuille. l Chaque nœud de l'arborescence contient au plus m sous-arbres.
2 Comparaison des performances d'InnoDB et MyISAM
alter table myisamtable engine=myisam;

alter database myisamtest character set utf8;
alter database innodbtest character set utf8;

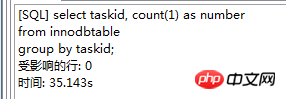
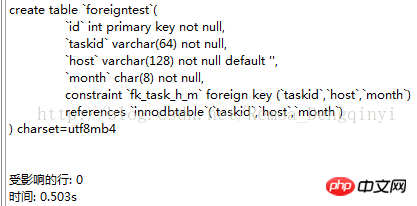
create table `foreigntest`(
`id` int primary key not null,
`taskid` varchar(64) not null,
`host` varchar(128) not null default '',
`month` char(8) not null,
constraint `fk_task_h_m` foreign key (`taskid`,`host`,`month`)
references `innodbtable`(`taskid`,`host`,`month`)
) charset=utf8mb4
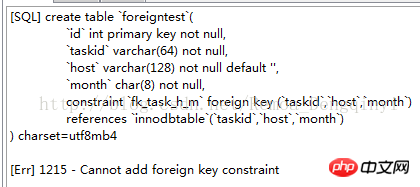
3 Comparaison des verrous entre MyISAM et InnoDB
4 Comparaison de deux index de moteur de stockage
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!