
Maison >Java >javaDidacticiel >Recherche sur le mécanisme de recyclage dans la machine virtuelle Java
Recherche sur le mécanisme de recyclage dans la machine virtuelle Java
- 一个新手original
- 2017-09-07 15:38:411875parcourir
1 : Présentation
En parlant de garbage collection (Garbage Collection, GC), beaucoup de gens l'associeront naturellement à Java. En Java, les programmeurs n'ont pas à se soucier de l'allocation dynamique de la mémoire et du garbage collection. Comme son nom l'indique, le garbage collection consiste à libérer l'espace occupé par les garbage tout cela est laissé à la JVM. Cet article répond principalement à trois questions :
1. Quelle mémoire faut-il recycler ? (Quels objets peuvent être considérés comme des « déchets »)
2.Comment recycler ? (Algorithmes de collecte des déchets couramment utilisés)
3. Quels outils sont utilisés pour le recyclage ? (Garbage collector)
2. Algorithme de détermination des déchets JVM
Les algorithmes de détermination des déchets couramment utilisés comprennent : l'algorithme de comptage de références et l'algorithme d'analyse d'accessibilité.
1. Algorithme de comptage de références
Java est associé aux objets via des références, ce qui signifie que si vous souhaitez faire fonctionner un objet, vous devez le faire via des références. Ajoutez un compteur de référence à l'objet. Chaque fois qu'il y a une référence à celui-ci, la valeur du compteur est incrémentée de 1 à l'expiration de la référence, la valeur du compteur est décrémentée de 1, un objet avec un compteur de 0 ne peut à aucun moment être utilisé ; plus, c'est-à-dire Indique que l'objet peut être considéré comme un « déchet » pour le recyclage.
L'algorithme du compteur de références est simple à mettre en œuvre et très efficace cependant, il ne peut pas résoudre le problème des références circulaires (l'objet A fait référence à l'objet B, l'objet B fait référence à l'objet A, mais les objets A et B ne sont pas plus référencé par d'autres objets), dans le même temps, chaque augmentation et diminution du compteur entraîne beaucoup de surcharge supplémentaire, donc après JDK1.1, cet algorithme n'est plus utilisé. Code :
public class Main {
public static void main(String[] args) {
MyTest test1 = new MyTest();
MyTest test2 = new MyTest();
test1.obj = test2;
test2.obj = test1;//test1与test2存在相互引用
test1 = null;
test2 = null;
System.gc();//回收
}
}
class MyTest{
public Object obj = null;
}Bien que test1 et test2 se voient finalement attribuer null, ce qui signifie que les objets pointés par test1 et test2 ne sont plus accessibles, mais comme ils se réfèrent l'un à l'autre, leurs décomptes de références sont tous Si ce n’est pas 0, le garbage collector ne les récupérera jamais. Après avoir exécuté le programme, nous pouvons voir à partir de l'analyse de la mémoire que la mémoire de ces deux objets est en fait recyclée. Cela montre également que la JVM actuelle n'utilise pas l'algorithme du compteur de référence comme algorithme de détermination des déchets.
2. Algorithme d'analyse d'accessibilité (algorithme de recherche racine)
L'algorithme de recherche racine utilise certains objets "GC Roots" comme point de départ, recherche vers le bas à partir de ces nœuds et recherche le chemin transmis. Devient une chaîne de référence
(Reference Chain). Lorsqu'un objet n'est pas connecté par la chaîne de référence de GC Roots, cela signifie que l'objet est indisponible.
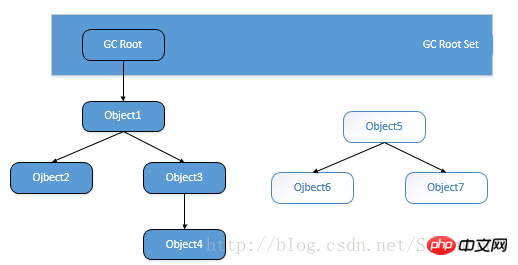
Les objets GC Roots incluent :
a) Les objets référencés dans la pile de la machine virtuelle (table de variables locales dans le cadre de la pile).
b) L'objet référencé par la propriété statique de classe dans la zone de méthode.
c) L'objet référencé par la constante dans la zone méthode.
d) L'objet référencé par JNI (de manière générale méthode native) dans la pile de méthodes natives.
Dans l'algorithme d'analyse d'accessibilité, les objets inaccessibles ne sont pas « nécessaires pour mourir ». À ce stade, ils sont temporairement au stade « suspendu » Pour véritablement déclarer un objet mort, il faut au moins deux marquages secondaires. processus : s'il s'avère que l'objet n'a aucune chaîne de référence connectée aux racines GC après l'analyse d'accessibilité, il sera marqué pour la première fois et filtré une fois. La condition de filtrage est de savoir si l'objet doit exécuter la méthode finalize(). Lorsque l'objet ne couvre pas la méthode finalize(), ou que la méthode finalize() a été appelée par la machine virtuelle, la machine virtuelle traite les deux situations comme « pas besoin d'exécution ». Notez que la méthode finalize() de n’importe quel objet ne sera automatiquement exécutée qu’une seule fois par le système.
S'il est déterminé que cet objet doit exécuter la méthode finalize(), alors cet objet sera placé dans une file d'attente appelée F-Queue, et sera ensuite automatiquement créé par une machine virtuelle le thread prioritaire Finalizer. l'exécute. Ce qu'on appelle "l'exécution" signifie ici que la machine virtuelle déclenche cette méthode, mais ne promet pas d'attendre la fin de son exécution. La raison en est que si un objet s'exécute lentement dans la méthode finalize(), ou infiniment. Si une boucle se produit, cela sera très difficile. Cela peut entraîner une attente permanente d'autres objets de la file d'attente F, voire provoquer le crash de l'ensemble du système de recyclage de la mémoire. Par conséquent, appeler la méthode finalize() ne signifie pas que le code de la méthode peut être complètement exécuté.
La méthode finalize() est la dernière chance pour l'objet d'échapper au sort de la mort. Plus tard, le GC marquera l'objet dans la file d'attente F pour une seconde petite échelle si l'objet doit être. sauvé avec succès dans finalize() Self - Ré-associez-vous simplement à n'importe quel objet de la chaîne de référence, par exemple, assignez-vous (ce mot-clé) à une variable de classe ou à une variable membre de l'objet, et il sera supprimé une fois marqué pour le deuxième fois. Sorti de la collection « sur le point d'être recyclé » ; si l'objet ne s'est pas échappé à ce moment-là, alors il est en fait réellement recyclé. À partir du code suivant, nous pouvons voir que finalize() d'un objet est exécuté, mais qu'il peut toujours survivre.
/**
* 此代码演示了两点:
* 1.对象可以在被GC时自我拯救。
* 2.这种自救的机会只有一次,因为一个对象的finalize()方法最多只会被系统自动调用一次
*/ public class FinalizeEscapeGC {
public static FinalizeEscapeGC SAVE_HOOK = null;
public void isAlive() {
System.out.println("yes, i am still alive :)");
}
@Override
protected void finalize() throws Throwable {
super.finalize();
System.out.println("finalize mehtod executed!");
FinalizeEscapeGC.SAVE_HOOK = this;
}
public static void main(String[] args) throws Throwable {
SAVE_HOOK = new FinalizeEscapeGC();
//对象第一次成功拯救自己
SAVE_HOOK = null;
System.gc();
//因为finalize方法优先级很低,所以暂停0.5秒以等待它
Thread.sleep(500);
if (SAVE_HOOK != null) {
SAVE_HOOK.isAlive();
} else {
System.out.println("no, i am dead :(");
}
//下面这段代码与上面的完全相同,但是这次自救却失败了
SAVE_HOOK = null;
System.gc();
//因为finalize方法优先级很低,所以暂停0.5秒以等待它
Thread.sleep(500);
if (SAVE_HOOK != null) {
SAVE_HOOK.isAlive();
} else {
System.out.println("no, i am dead :(");
}
}
}Résultat de l'exécution :
finalize mehtod executed! yes, i am still alive :) no, i am dead :(
从运行结果可以看出,SAVE_HOOK对象的finalize()方法确实被GC收集器调用过,且在被收集前成功逃脱了。
另外一个值得注意的地方是,代码中有两段完全一样的代码片段,执行结果却是一次逃脱成功,一次失败,这是因为任何一个对象的finalize()方法都只会被系统自动调用一次,如果对象面临下一次回收,它的finalize()方法不会被再次执行,因此第二段代码的自救行动失败了。
三、JVM垃圾回收算法
常用的垃圾回收算法包括:标记-清除算法,复制算法,标记-整理算法,分代收集算法
1、标记—清除算法(Mark-Sweep)(DVM 使用的算法)
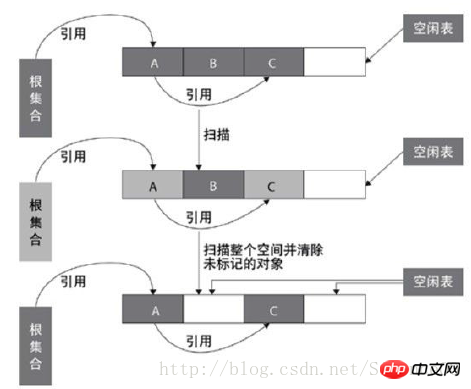
标记—清除算法包括两个阶段:“标记”和“清除”。在标记阶段,确定所有要回收的对象,并做标记。清除阶段紧随标记阶段,将标记阶段确定不可用的对象清除。标记—清除算法是基础的收集算法,标记和清除阶段的效率不高,而且清除后回产生大量的不连续空间,这样当程序需要分配大内存对象时,可能无法找到足够的连续空间。
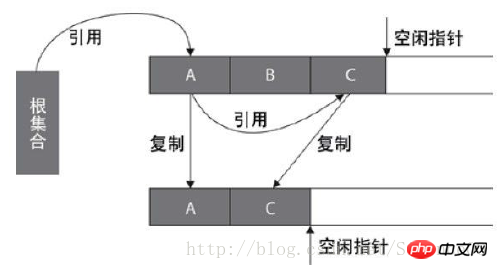
2、复制算法(Copying)
复制算法是把内存分成大小相等的两块,每次使用其中一块,当垃圾回收的时候,把存活的对象复制到另一块上,然后把这块内存整个清理掉。复制算法实现简单,运行效率高,但是由于每次只能使用其中的一半,造成内存的利用率不高。现在的JVM 用复制方法收集新生代,由于新生代中大部分对象(98%)都是朝生夕死的,所以两块内存的比例不是1:1(大概是8:1)。
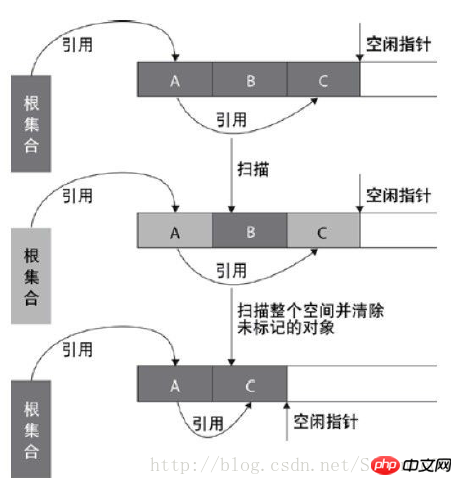
3、标记—整理算法(Mark-Compact)
标记—整理算法和标记—清除算法一样,但是标记—整理算法不是把存活对象复制到另一块内存,而是把存活对象往内存的一端移动,然后直接回收边界以外的内存。标记—整理算法提高了内存的利用率,并且它适合在收集对象存活时间较长的老年代。
4、分代收集(Generational Collection)
分代收集是根据对象存活周期的不同将内存划分为几块。一般是把Java堆分为新生代和老年代,这样就可以根据各个年代的特点采用最适当的收集算法。在新生代中,每次垃圾收集时都发现有大批对象死去,只有少量存活,那就选用复制算法,只需要付出少量存活对象的复制成本就可以完成收集。而老年代中因为对象存活率高、没有额外空间对它进行分配担保,就必须使用“标记—清理”或者“标记—整理”算法来进行回收。
四、垃圾收集器
如果说垃圾收集算法是内存回收的方法论,那么垃圾收集器就是内存回收的具体实现。上面说过,各个平台虚拟机对内存的操作各不相同,因此本章所讲的收集器是基于JDK1.7Update14之后的HotSpot虚拟机。这个虚拟机包含的所有收集器如图:
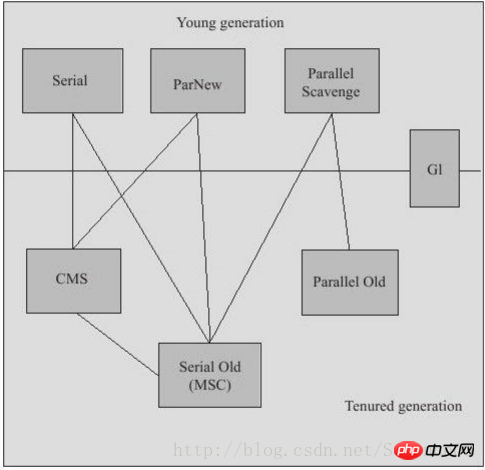
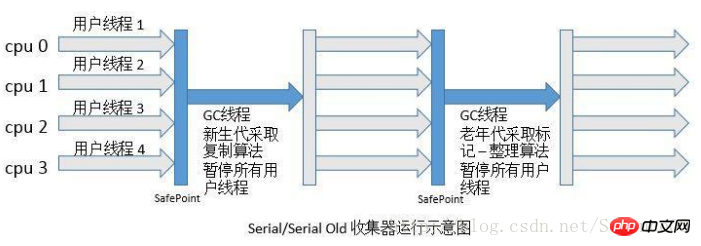
1、Serial收集器
Serial收集器是最基本、发展历史最悠久的收集器,曾经(在JDK 1.3.1之前)是虚拟机
新生代收集的唯一选择。大家看名字就会知道,这个收集器是一个单线程的收集器,但它
的“单线程”的意义并不仅仅说明它只会使用一个CPU或一条收集线程去完成垃圾收集工作,
更重要的是在它进行垃圾收集时,必须暂停其他所有的工作线程,直到它收集结束。
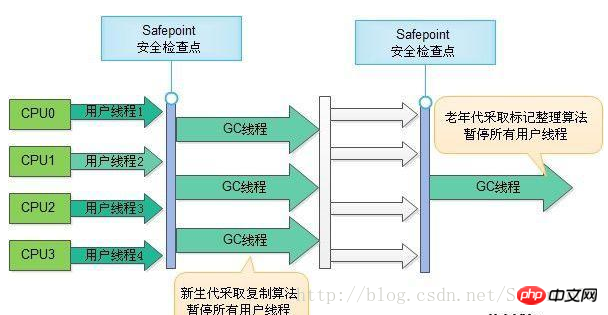
2、ParNew收集器
ParNew收集器其实就是Serial收集器的多线程版本,除了使用多条线程进行垃圾收集之
外,其余行为包括Serial收集器可用的所有控制参数(例如:-XX:SurvivorRatio、-XX:
PretenureSizeThreshold、-XX:HandlePromotionFailure等)、收集算法、Stop The World、对
象分配规则、回收策略等都与Serial收集器完全一样,在实现上,这两种收集器也共用了相
当多的代码。
3. Collecteur Parallel Scavenge
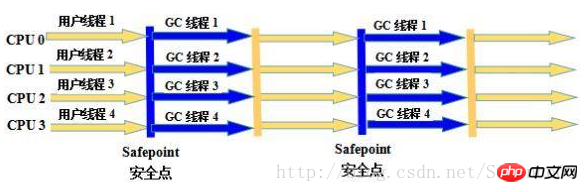
La caractéristique du collecteur Parallel Scavenge est que son objectif est différent des autres collecteurs. L'objectif du collecteur Parallel Scavenge est d'atteindre un contrôle. débit. Le soi-disant débit est le rapport entre le temps passé par le processeur à exécuter le code utilisateur et le temps total consommé par le processeur, c'est-à-dire débit = temps d'exécution du code utilisateur/(temps d'exécution du code utilisateur + temps de garbage collection). En raison de sa relation étroite avec le débit, le collecteur Parallel Scavenge est souvent appelé un collecteur « axé sur le débit d'abord ».
4. Serial Old collector
Serial Old est la version d'ancienne génération du Serial Collector. Il s'agit également d'un collecteur monothread et utilise l'algorithme "mark-sort". L'intérêt principal de ce collecteur est également d'être utilisé par les machines virtuelles en mode Client. S'il est en mode Serveur, il a deux utilisations principales : l'une doit être utilisée avec le collecteur Parallel Scavenge dans JDK 1.5 et les versions précédentes [1], et l'autre doit être utilisée comme plan de sauvegarde pour le collecteur CMS. utilisé lorsque ConcurrentMode Failure se produit dans une collection simultanée.
5. Parallel Old collector
Parallel Old est la version ancienne génération du collecteur Parallel Scavenge, utilisant le multi-threading et l'algorithme de "mark-collation".
Ce collecteur n'était fourni que dans le JDK 1.6.
6. Le collecteur CMS
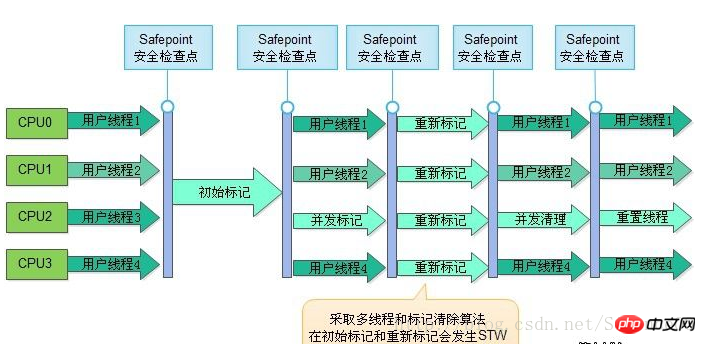
Le collecteur CMS (Concurrent Mark Sweep) est un collecteur qui vise à obtenir le temps de pause de recyclage le plus court. À l'heure actuelle, une grande partie des applications Java sont concentrées sur les serveurs de sites Internet ou de systèmes B/S. Ces applications accordent une attention particulière à la vitesse de réponse du service et espèrent que le temps de pause du système sera le plus court possible pour offrir aux utilisateurs. une meilleure expérience.
Le processus opérationnel est divisé en 4 étapes, dont :
a) Marque initiale (marque initiale CMS)
b) Marque simultanée (marque concurrente CMS)
c) Remarque (remarque CMS)
d) Concurrent scanning (CMS concurrent scanning)
Le collecteur CMS présente trois inconvénients :
1 Il est sensible aux ressources CPU. Généralement, les programmes exécutés simultanément sont sensibles au nombre de processeurs
2 qui ne peuvent pas gérer les déchets flottants. Pendant la phase de nettoyage simultanée, le thread utilisateur est toujours en cours d'exécution et les déchets générés à ce moment ne peuvent pas être nettoyés.
3 Une grande quantité de fragmentation de l'espace est générée en raison de l'algorithme de balayage de marque.
7. Collecteur G1
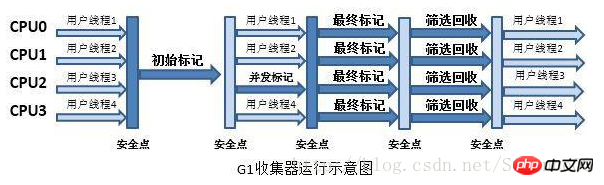
G1 est un garbage collector pour les applications côté serveur.
Le fonctionnement du collecteur G1 peut être grossièrement divisé en les étapes suivantes :
a) Marquage initial (Marquage initial)
b) Marquage simultané (Marquage simultané)
c) Marquage final (Marquage final)
d) Criblage et recyclage (Comptage des données en direct et évacuation)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!