
Maison >Opération et maintenance >exploitation et maintenance Linux >Une introduction détaillée à la gestion de la mémoire sous Linux
Une introduction détaillée à la gestion de la mémoire sous Linux
- 巴扎黑original
- 2017-08-23 15:50:171375parcourir
J'ai lu "Compréhension approfondie du noyau Linux" il y a quelque temps et j'ai passé beaucoup de temps sur la partie gestion de la mémoire, mais il y a encore de nombreuses questions qui ne sont pas très claires que j'ai récemment passé du temps à réviser. et je me suis enregistré ici pour comprendre, ainsi que quelques points de vue et connaissances sur la gestion de la mémoire sous Linux.
Je préfère comprendre le processus de développement d'une technologie elle-même. Bref, c'est comment cette technologie s'est développée, quelles technologies existaient avant cette technologie, quelles sont les caractéristiques de ces technologies, et pourquoi sont-elles utilisées actuellement ? Elle a été remplacée par une nouvelle technologie et la technologie actuelle a résolu les problèmes de la technologie précédente. Une fois que nous les comprenons, nous pouvons avoir une compréhension plus claire d’une certaine technologie. Certains documents introduisent directement le sens et les principes d’un certain concept sans mentionner le processus de développement et les principes qui le sous-tendent, comme si la technologie tombait du ciel. À ce stade, parlons du sujet d’aujourd’hui basé sur l’histoire du développement de la gestion de la mémoire.
Tout d'abord, je dois expliquer que le sujet de cet article est la technologie de segmentation et de pagination dans la gestion de la mémoire Linux.
Revenons sur l’histoire. Dans les premiers ordinateurs, les programmes s’exécutaient directement sur la mémoire physique. En d’autres termes, tous les programmes auxquels on accède pendant l’exécution sont des adresses physiques. Si ce système n'exécute qu'un seul programme, alors tant que la mémoire requise par ce programme ne dépasse pas la mémoire physique de la machine, il n'y aura pas de problème, et nous n'avons pas besoin de considérer la gestion fastidieuse de la mémoire. juste votre programme, c'est tout. Économisez de l'argent, c'est à vous de décider si vous mangez suffisamment ou pas. Cependant, les systèmes actuels prennent tous en charge le multitâche et le multitraitement, de sorte que l'utilisation du processeur et des autres matériels sera plus élevée. À ce stade, nous devons réfléchir à la manière d'allouer la mémoire physique limitée du système à plusieurs programmes en temps opportun. et efficace, cette question elle-même est appelée gestion de la mémoire.
Donnons un exemple de gestion de l’allocation de mémoire dans un premier système informatique pour faciliter la compréhension de chacun.
Nous avons trois programmes, les programmes 1, 2 et 3. Le programme 1 nécessite 10 Mo de mémoire lors de son exécution, le programme 2 nécessite 100 Mo de mémoire lors de son exécution et le programme 3 nécessite 20 Mo de mémoire lors de son exécution. Si le système doit exécuter les programmes A et B en même temps, le premier processus de gestion de la mémoire est probablement le suivant, allouant les 10 premiers Mo de mémoire physique à A et les 10 à 110 Mo suivants à B. Cette méthode de gestion de la mémoire est relativement simple. D'accord, supposons que nous voulons que le programme C s'exécute à ce moment-là, et supposons que la mémoire de notre système n'est que de 128 Mo. Évidemment, selon cette méthode, le programme C ne peut pas s'exécuter en raison d'une insuffisance. mémoire. Tout le monde sait que vous pouvez utiliser la technologie de mémoire virtuelle. Lorsque l'espace mémoire n'est pas suffisant, vous pouvez échanger les données qui ne sont pas utilisées par le programme vers l'espace disque, ce qui a permis d'étendre l'espace mémoire. Jetons un coup d'œil à certains des problèmes les plus évidents liés à cette méthode de gestion de la mémoire. Comme mentionné au début de l’article, pour avoir une compréhension approfondie d’une technologie, il est préférable de comprendre son historique de développement.
1. L'espace d'adressage du processus ne peut pas être isolé
Étant donné que le programme accède directement à la mémoire physique, l'espace mémoire utilisé par le programme n'est pas isolé pour le moment. Par exemple, comme mentionné ci-dessus, l'espace d'adressage de A est compris entre 0 et 10 M, mais s'il y a un morceau de code dans A qui exploite les données dans l'espace d'adressage de 10 M à 128 M, alors le programme B et le programme C sont il est probable qu'il plante (chaque programme peut occuper tout l'espace d'adressage du système). De cette manière, de nombreux programmes malveillants ou chevaux de Troie peuvent facilement détruire d'autres programmes, et la sécurité du système ne peut pas être garantie, ce qui est intolérable pour les utilisateurs.
2. L'utilisation de la mémoire est inefficace
Comme mentionné ci-dessus, si nous voulons laisser les programmes A, B et C s'exécuter en même temps, alors le seul moyen est d'utiliser la technologie de mémoire virtuelle pour combiner certaines données qui ne sont pas temporairement utilisées par le programme sont écrites sur le disque et sont relues du disque vers la mémoire en cas de besoin. Pour exécuter le programme C ici, l'échange de A sur le disque n'est évidemment pas possible, car le programme nécessite un espace d'adressage continu. Le programme C nécessite 20 Mo de mémoire et A ne dispose que de 10 Mo d'espace, le programme B doit donc être échangé sur le disque. . et B fait entièrement 100 M. Nous pouvons voir que pour exécuter le programme C, nous devons écrire 100 M de données de la mémoire sur le disque, puis les lire du disque vers la mémoire lorsque le programme B doit s'exécuter. les opérations prennent du temps. L’efficacité de ce processus sera donc très faible.
3. L'adresse où le programme s'exécute ne peut pas être déterminée
Chaque fois que le programme doit s'exécuter, il doit allouer une zone libre suffisamment grande dans la mémoire. Le problème est que cette zone est libre. l'emplacement ne peut pas Bien sûr, cela entraînera des problèmes de relocalisation. Le problème de relocalisation doit concerner les adresses des variables et des fonctions référencées dans le programme. Si vous ne comprenez pas, vous pouvez vérifier les informations de compilation.
La gestion de la mémoire n'est rien d'autre que trouver des moyens de résoudre les trois problèmes ci-dessus, comment isoler l'espace d'adressage du processus, comment améliorer l'efficacité de l'utilisation de la mémoire et comment résoudre le problème de relocalisation lorsque le programme est en marche ?
Voici une citation d'un dicton célèbre de l'industrie informatique qui ne peut être vérifié : "Tout problème dans un système informatique peut être résolu en introduisant une couche intermédiaire
."La méthode actuelle de gestion de la mémoire introduit la notion de mémoire virtuelle entre le programme et la mémoire physique. La mémoire virtuelle est située entre le programme et la mémoire interne. Le programme ne peut voir que la mémoire virtuelle et ne peut plus accéder directement à la mémoire physique. Chaque programme possède son propre espace d'adressage de processus indépendant, réalisant ainsi l'isolation des processus. L'espace d'adressage du processus fait ici référence à l'adresse virtuelle. Comme son nom l'indique, puisqu'il s'agit d'une adresse virtuelle, il s'agit d'un espace d'adressage virtuel et non réel.
Puisque nous avons ajouté une adresse virtuelle entre le programme et l'espace d'adressage physique, nous devons comprendre comment mapper l'adresse virtuelle à l'adresse physique, car le programme doit finalement s'exécuter dans la mémoire physique, principalement segmenté et pagination de deux technologies.
Segmentation : Cette méthode est l'une des premières méthodes utilisées. L'idée de base est de mapper l'espace virtuel de l'espace d'adressage mémoire requis par le programme à un certain espace d'adressage physique.
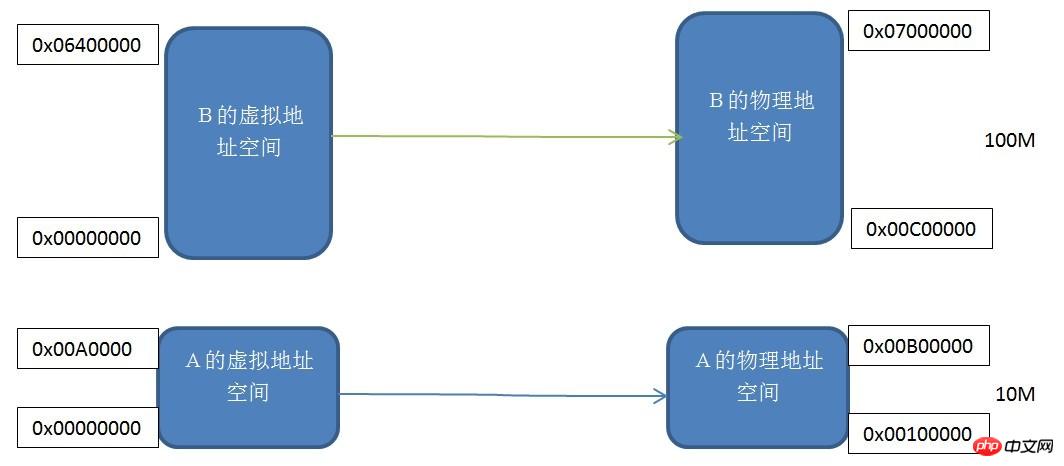
Mécanisme de mappage de segments
Chaque programme possède son propre espace d'adressage de processus virtuel indépendant. Vous pouvez voir les adresses virtuelles des programmes A et B. Les espaces sont tous. commencer à partir de 0x00000000. Nous mappons un par un deux espaces d'adressage virtuel de même taille à l'espace d'adressage physique réel, c'est-à-dire que chaque octet de l'espace d'adressage virtuel correspond à chaque octet de l'espace d'adressage réel. Ce processus de mappage est défini par un mécanisme logiciel. la conversion réelle est effectuée par le matériel.
Ce mécanisme segmenté résout les trois problèmes mentionnés au début de l'article : l'isolation de l'espace d'adressage des processus et la relocalisation des adresses des programmes. Le programme A et le programme B ont leurs propres espaces d'adressage virtuels indépendants, et les espaces d'adressage virtuels sont mappés à des espaces d'adressage physiques qui ne se chevauchent pas. Si l'adresse à laquelle le programme A accède à l'espace d'adressage virtuel n'est pas comprise entre 0x00000000 et 0x00A00000, alors. le noyau refusera cette demande, ce qui résoudra le problème de l'isolation de l'espace d'adressage. Notre application A n'a besoin de se soucier que de son espace d'adressage virtuel 0x00000000-0x00A00000, et nous n'avons pas besoin de nous soucier de l'adresse physique à laquelle elle est mappée, donc le programme placera toujours les variables et le code en fonction de cet espace d'adressage virtuel sans déplacement.
Dans tous les cas, le mécanisme de segmentation résout les deux problèmes ci-dessus, ce qui constitue un grand progrès, mais il est toujours impuissant à résoudre le problème de l'efficacité de la mémoire. Étant donné que ce mécanisme de mappage de mémoire est toujours basé sur le programme, lorsque la mémoire est insuffisante, l'intégralité du programme doit toujours être transférée sur le disque, de sorte que l'efficacité de l'utilisation de la mémoire est encore très faible. Alors, qu’est-ce qui est considéré comme une utilisation efficace de la mémoire ? En effet, selon le principe de fonctionnement local du programme, seule une petite partie des données sera fréquemment utilisée pendant une certaine période de temps lors de l'exécution d'un programme. Nous avons donc besoin d'une méthode de partitionnement et de mappage de mémoire plus fine. À ce stade, penserez-vous à l'algorithme Buddy et au mécanisme d'allocation de mémoire par tranche sous Linux, haha. Une autre façon de convertir des adresses virtuelles en adresses physiques est le mécanisme de pagination.
Mécanisme de pagination :
Le mécanisme de pagination consiste à diviser l'espace d'adressage de la mémoire en plusieurs petites pages de taille fixe. La taille de chaque page est déterminée par la mémoire, tout comme le système de fichiers ext. Linux La division du disque en plusieurs blocs a pour but d'améliorer respectivement la mémoire et l'utilisation du disque. Imaginez ce qui suit, si l'espace disque est divisé en N parties égales, la taille de chaque partie (un bloc) est de 1 Mo, et si le fichier que je souhaite stocker sur le disque fait 1 Ko, alors les 999 octets restants sont gaspillés. Par conséquent, une méthode de partitionnement de disque plus fine est nécessaire. Nous pouvons définir le bloc pour qu'il soit plus petit. Ceci est bien sûr basé sur la taille des fichiers stockés. Cela semble un peu hors sujet. le mécanisme en mémoire est différent de celui en ext. Le mécanisme de partitionnement de disque dans les systèmes de fichiers est très similaire.
La taille générale des pages sous Linux est de 4 Ko. Nous divisons l'espace d'adressage du processus par pages, chargeons les données et les pages de codes couramment utilisées en mémoire et enregistrons le code et les données inhabituels sur le disque. un exemple, comme indiqué ci-dessous :
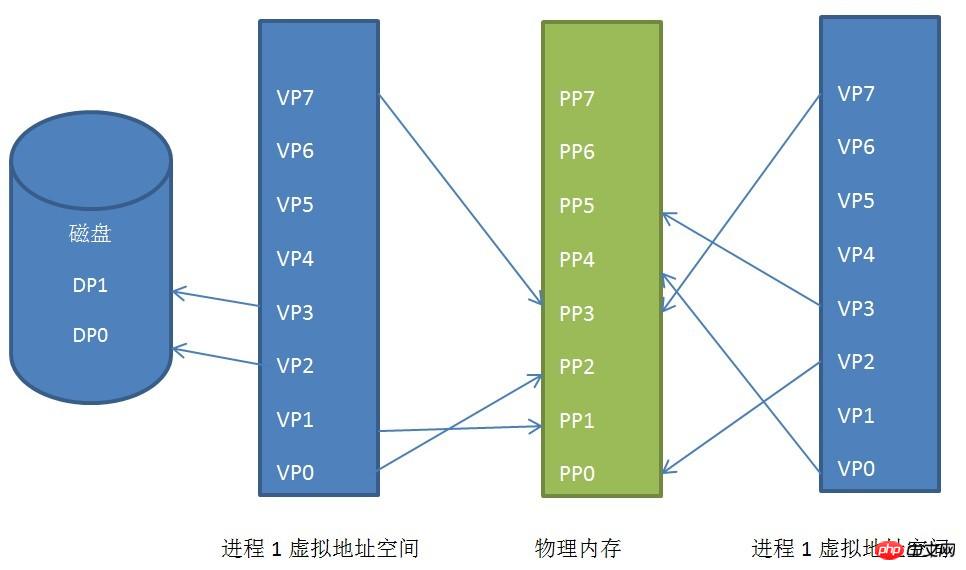
Relation de mappage de pages entre l'espace d'adressage virtuel du processus, l'espace d'adressage physique et le disque
Nous pouvons voir les espaces d'adressage virtuels de les processus 1 et 2 sont mappés dans des espaces d'adressage physiques discontinus (cela est d'une grande importance, si un jour nous n'avons pas suffisamment d'espace d'adressage physique continu, mais qu'il existe de nombreux espaces d'adressage discontinus, s'il n'y a pas une telle technologie, notre programme ne peut pas run), même s’ils partagent une partie de l’espace d’adressage physique, qui est la mémoire partagée.
Les pages virtuelles VP2 et VP3 du processus 1 sont échangées sur le disque. Lorsque le programme a besoin de ces deux pages, le noyau Linux générera une exception de faute de page, puis le programme de gestion des exceptions la lira dans le fichier. mémoire.
C'est le principe du mécanisme de pagination. Bien entendu, la mise en œuvre du mécanisme de pagination sous Linux est encore relativement compliquée. Elle est implémentée via le répertoire global, le répertoire supérieur, le répertoire intermédiaire de page, la table de page et autres. niveaux de mécanisme de pagination Oui, mais le principe de fonctionnement de base ne changera pas.
La mise en œuvre du mécanisme de pagination nécessite une implémentation matérielle. Le nom de ce matériel est MMU (Memory Management Unit). Il est spécifiquement responsable de la conversion des adresses virtuelles en adresses physiques, c'est-à-dire de la recherche de pages physiques à partir de pages virtuelles.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Apprenez à installer le serveur Nginx sous Linux
- Introduction détaillée à la commande wget de Linux
- Explication détaillée d'exemples d'utilisation de yum pour installer Nginx sous Linux
- Explication détaillée des problèmes de connexions des travailleurs dans Nginx
- Explication détaillée du processus d'installation de python3 sous Linux