
Maison >développement back-end >tutoriel php >Cadre de déploiement de conteneurs de modèles de conception PHP basé sur un moteur de modèles
Cadre de déploiement de conteneurs de modèles de conception PHP basé sur un moteur de modèles
- 巴扎黑original
- 2017-08-16 09:33:061607parcourir
Résumé : La création de conteneurs ou la configuration du déploiement d'applications est compliquée et variable Afin de garantir la flexibilité et la réutilisabilité du système, cet article se concentre sur la façon d'utiliser le moteur de modèles. en tant que noyau, créez un cadre de déploiement de conteneurs unifié.
Dans le processus d'utilisation des conteneurs, chacun aura une expérience. Il existe une quarantaine ou une cinquantaine d'éléments de configuration de conteneurs, et cela nécessite une certaine formation technique pour être compris. Au cours du processus de déploiement, les utilisateurs rencontrent souvent divers problèmes lors du démarrage des conteneurs, du déploiement d'applications ou de la mise à niveau en raison d'un manque de compréhension des paramètres de configuration. Comment les utilisateurs peuvent accélérer leur compréhension des différents paramètres et se développer en conséquence en fonction de différents types d'applications et scénarios. Cet article se concentrera sur l'exploration et la résolution de ces problèmes.
La création de conteneurs ou la configuration du déploiement d'applications est complexe et variable. Afin de garantir la flexibilité et la réutilisabilité du système, il a été décidé de créer un cadre de déploiement de conteneurs unifié avec le moteur de modèles comme noyau. Cet article se concentre sur la façon de créer un moteur de modèles et sur le principe de fonctionnement de la création d'un cadre de déploiement de conteneurs avec le moteur de modèles comme noyau. Dans le moteur de modèles, les fichiers conformes à certaines spécifications de format constituent la base. Pour les emplacements qui peuvent changer ou doivent être modifiés en fonction du processus de déploiement, des paramètres sont utilisés pour identifier le site. La définition de l'identifiant de paramètre est ajoutée à la fin du fichier modèle pour effectuer une transformation sémantique de l'identifiant de paramètre. Le contenu spécifique du modèle ou l'identification des paramètres peut être lu ou reçu des paramètres de demande du client via un fichier de configuration spécifique.
Moteur de modèles
Le moteur de modèles se compose de quatre modules : la définition du modèle, l'analyse du modèle, la conversion du modèle et l'exécution du modèle. La définition du modèle dépend de la structure de gestion du cluster de conteneurs et constitue un fichier non exécutable. L'analyseur de modèle est chargé de diviser le modèle en deux parties : une partie forme le modèle de déploiement non exécutable ; l'autre partie constitue la description de définition des paramètres dans le modèle de déploiement. La description de la définition des paramètres est unifiée avec l'identifiant du site dans le modèle. modèle de déploiement via un identifiant de site unique. Le convertisseur de modèle accepte les valeurs des paramètres et les combine avec le modèle de déploiement généré dans l'analyseur. L'identifiant de la valeur du paramètre est associé à l'identifiant de l'espace réservé dans le modèle. La valeur du paramètre est remplacée par l'identifiant de l'espace réservé pour générer un fichier exécutable. L'exécuteur de modèle est responsable de la création d'objets basés sur le modèle et est généralement responsable du cadre de planification ou du moteur de conteneur.
Le principe d'exécution du moteur de template est présenté dans la figure 1 : 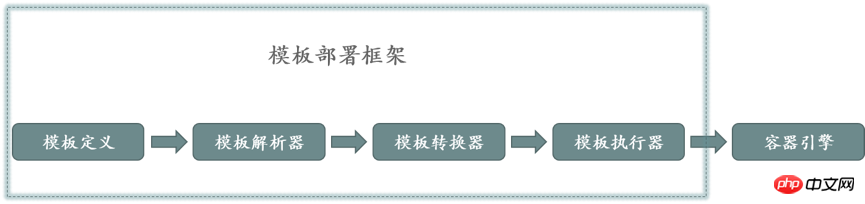
Définition du modèle
La définition du modèle comprend deux types d'informations : l'identification des paramètres de déploiement ;
Prenons l'exemple du modèle de déploiement de Kubernetes. Le modèle de déploiement implique 4 types différents de définitions, à savoir : les ressources, les versions, les descriptions d'informations et les configurations de données.
Ressource : représente le type d'objet défini dans Kubernetes.
Version : indique la version de l'objet
Description des informations : y compris le nom de l'objet, l'étiquette, le commentaire, etc., fournissant un index pour l'objet recherche ou planification.
Configuration des données : responsable de la définition des normes que le conteneur suit lors de son exécution, y compris les ports, les variables d'environnement, les ressources, la planification, les contrôles de santé, etc.
L'identifiant du paramètre est composé de 6 attributs, à savoir les paramètres, le nom, la description, le nom d'affichage, la valeur, le type.
paramètres : indicateur de démarrage de la définition du paramètre
description : informations d'invite du paramètre
nom d'affichage : spécifique information sémantique
nom : Correspond au nom du paramètre de référence, indiquant que les informations de description sont le paramètre de référence correspondant
valeur : Valeur par défaut du paramètre
-
type : représente différents styles Le client présente des styles spécifiques selon le type
.
En prenant l'objet espace de noms dans Kubernetes comme exemple, la définition complète du modèle est comme indiqué dans le code suivant :
apiVersion: v1kind: Namespacemetadata:
name: ${name }
---
{"parameters":
[
{ "description": "命名空间", "displayName": "命名空间", "name": "name", "value": "", "type": "String"
}
]}Le code ci-dessus contient deux parties : déploiement le modèle et les paramètres illustrent.
Le modèle de déploiement est tel qu'illustré dans le bloc de code suivant :
apiVersion: v1kind: Namespacemetadata:
name: ${name }Le modèle de déploiement définit tout le contenu créé par l'objet. La signification des champs dans le modèle est décrite comme. suit :
apiVersion : options communes, définir les informations de version
Kind : définir les types d'objets, distinguer les différents objets
Métadonnées : définir ce qui est spécifié lors du déploiement Paire clé-valeur de paramètre
-
${} : représente la valeur de référence du paramètre, qui peut remplacer le paramètre
identifiant du paramètre, qui définit la dynamique du client Le formulaire d'affichage après obtention des paramètres, l'exemple de code suivant définition d'identification du paramètre :
{"parameters": [
{
"description": "命名空间",
"displayName": "命名空间",
"name": "name",
"value": "",
"type": "String"
}
]}L'identification du paramètre définit un format unifié. Grâce à la transformation sémantique, les configurations complexes sont transformées de manière facile à comprendre pour les utilisateurs. Le client lit l'identifiant des paramètres, résume les paramètres d'entrée via l'analyseur de modèle, affiche le formulaire de formulaire requis et fournit la fonction de saisie utilisateur.
Les définitions des modèles sont rédigées par des professionnels familiers avec Kubernetes ou Docker. Des ajustements en temps réel et dynamiques peuvent être effectués en fonction de scénarios commerciaux spécifiques pour garantir la flexibilité et l'évolutivité du déploiement. Parallèlement, le système fournit des modèles de base basés sur différents objets. Les utilisateurs peuvent également créer et gérer des modèles basés sur un certain bagage de connaissances.
L'analyseur de modèle
obtient les identifiants de paramètres dans le modèle via les flux d'entrée et de sortie, effectue une conversion sémantique et obtient des paramètres de configuration faciles à comprendre. Le principe de fonctionnement de l'analyseur de modèle est illustré dans la figure 2 ci-dessous :
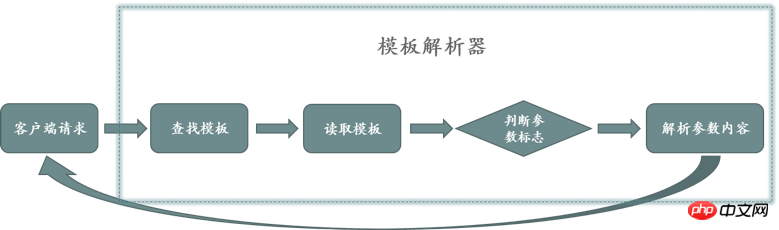
Le client initie une requête de création d'objet. Après réception de la requête, le serveur associera automatiquement le modèle de base en fonction du type d'objet demandé. Le modèle de base est lu via le flux de fichiers. Pendant le processus de lecture, l'indicateur Paramètres est utilisé comme point de départ pour obtenir les informations de description des paramètres. Une fois l'analyse terminée, les paramètres sont renvoyés au client sous la forme d'une chaîne Json. Le client génère dynamiquement un formulaire qui doit être rempli par l'utilisateur en fonction de la chaîne Json. sur le contenu du formulaire.
L'analyseur de modèles se concentre sur l'analyse des identifiants de paramètres dans les définitions de modèles. Grâce à la transformation sémantique et aux invites d'informations, des éléments d'entrée facilement identifiables sont formés. Pour les utilisateurs, les indicateurs techniques complexes peuvent être masqués une fois l'analyse terminée, et l'attention de l'utilisateur passe de la technologie à la configuration commerciale. Réduisez les coûts d’utilisation et augmentez la facilité d’utilisation.
Convertisseur de modèles
Le convertisseur de modèles est au cœur du moteur de modèles, se concentrant sur la résolution de trois problèmes : l'obtention de modèles de déploiement, la conversion des paramètres et des valeurs et la création de fichiers exécutables. Le client attribue des valeurs réelles aux paramètres dans l'analyseur de modèle et les transmet au serveur. Le serveur lit le contenu du modèle et se termine lorsqu'il rencontre le bit d'indicateur du paramètre. Il écrit le contenu lu dans un nouveau fichier via le. flux de fichiers, génère un fichier de déploiement, puis remplacez les paramètres du fichier de déploiement par des valeurs de paramètres pour générer le fichier exécutable final. Le principe de fonctionnement du convertisseur de modèles est illustré à la figure 3 :
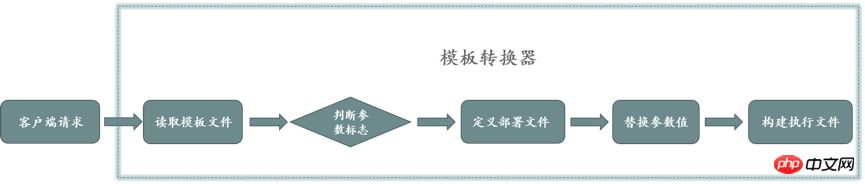
Obtenir le modèle de déploiement : comme le montre la définition du modèle, le modèle contient deux parties : le modèle de déploiement et l'identification des paramètres. Le convertisseur de modèle doit d'abord déployer le modèle et lire le modèle de déploiement dans la définition du modèle via le flux de fichiers. Pendant le processus de lecture, il est divisé par identifiant de paramètres pour obtenir le modèle de déploiement.
参数值转化:核心是解决参数与占位符关联和赋值问题。模板转换器通过模板参数定义的name属性key关联,模板转化器拿到参数值以后,获取参数值对应的key(key在部署模板唯一),并且根据key,替换部署模板中占位标识,完成参数替换。
构建可执行文件:通过文件流的方式,把前两部转化的字符流输出到文件,构建出可执行文件。
模板转换器执行以后,生成的可执行文件如下所示:
apiVersion: v1kind: Namespacemetadata: name: ruffy
模板执行器
模板执行器接收可执行的部署文件,对于文件中定义的部署类型进行解析,拆分成若干个可执行任务。容器引擎根据收到的任务执行操作,最终协同完成部署工作。模板执行器往往依赖于容器调度和执行引擎。以Kubernetes容器编排框架为例,模板转化器生成的可执行文件,以字符流的方式传输到Kubernetes的Server端,Kubernetes根据传入文件,自动解析文件内容,并且做出相关操作。对于模板引擎而言,无论是Kubernetes还是Swarmkit都能够得到友好的支持。模板执行器的工作原理如图4所示:

Le résultat après l'exécution de l'exécuteur de modèle est présenté dans la figure 5 : 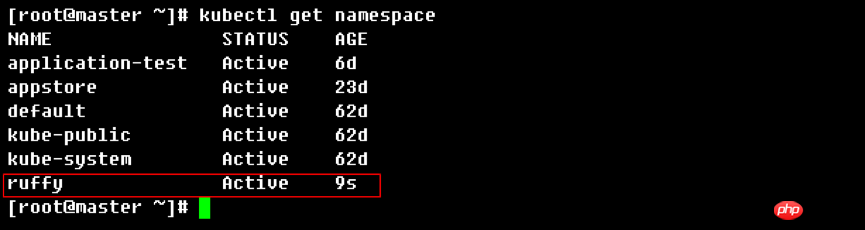
Grâce au moteur de modèle, la configuration du conteneur peut être utilisée de manière flexible, qu'il s'agisse d'un déploiement de conteneur ou d'une autre création d'objet de thème de ressource, il existe un support de modèle correspondant. Le moteur de traitement des modèles n'a pas besoin de modifier constamment le code en fonction des modifications du modèle. Dans le même temps, les utilisateurs peuvent se concentrer sur les informations de configuration à partir de la sémantique qu'ils comprennent, sans prêter attention aux détails techniques spécifiques et aux méthodes de mise en œuvre, simplifiant ainsi les comportements opérationnels et réduisant les coûts d'utilisation.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Tous les symboles d'expression dans les expressions régulières (résumé)