
Maison >développement back-end >Tutoriel Python >Le didacticiel de robot d'exploration Web le plus simple en python
Le didacticiel de robot d'exploration Web le plus simple en python

- 黄舟original
- 2017-08-13 10:41:392070parcourir
Lorsque nous naviguons sur Internet tous les jours, nous voyons souvent de belles images et nous souhaitons enregistrer et télécharger ces images, ou les utiliser comme fonds d'écran ou comme matériel de conception. L'article suivant vous présentera les informations pertinentes sur l'utilisation de Python pour implémenter le robot d'exploration Web le plus simple. Les amis qui en ont besoin peuvent s'y référer.
Avant-propos
Les robots d'exploration Web (également appelés araignées Web, robots Web, au sein de la communauté FOAF, plus communément appelés robots d'exploration Web) sont un programme ou un script qui capture automatiquement les informations du World Wide Web selon certaines règles. Récemment, je me suis beaucoup intéressé aux robots d'exploration Python. J'aimerais partager mon parcours d'apprentissage ici et accueillir vos suggestions. Nous communiquons les uns avec les autres et progressons ensemble. Sans plus tarder, jetons un œil à l'introduction détaillée :
1. Outils de développement
L'auteur utilise. Le meilleur outil est le sublime text3. Son contenu court et concis (peut-être que les hommes n'aiment pas ce mot) me fascine beaucoup. Son utilisation est recommandée à tout le monde. Bien entendu, si la configuration de votre ordinateur est bonne, pycharm peut vous convenir davantage.
Il est recommandé de consulter cet article pour créer un environnement de développement python avec sublime text3 :
[Configurer un environnement de développement python avec sublime]
Comme leur nom l'indique, les robots d'exploration sont comme des bugs qui rampent sur le grand Web d'Internet. De cette façon, nous pouvons obtenir ce que nous voulons.
Puisque nous voulons explorer Internet, nous devons comprendre l'URL, le nom légal est « Uniform Resource Locator » et le surnom est « lien ». Sa structure se compose principalement de trois parties :
(1) Protocole : tel que le protocole HTTP que nous voyons couramment dans les URL.
(2) Nom de domaine ou adresse IP : Nom de domaine, tel que : www.baidu.com, adresse IP, c'est-à-dire l'IP correspondante après résolution du nom de domaine.
(3) Chemin : répertoire ou fichier, etc.
3. urllib est le robot le plus simple à développer
(1) Introduction à urllib
| Module | Introduce |
|---|---|
| urllib.error | Exception classes raised by urllib.request. |
| urllib.parse | Parse URLs into or assemble them from components. |
| urllib.request | Extensible library for opening URLs. |
| urllib.response | Response classes used by urllib. |
| urllib.robotparser | Load a robots.txt file and answer questions about fetchability of other URLs. |
(2) Développer le robot d'exploration le plus simple
La page d'accueil de Baidu est simple et élégante, ce qui convient très bien à nos robots d'exploration.
Le code du robot est le suivant :
from urllib import request
def visit_baidu():
URL = "http://www.baidu.com"
# open the URL
req = request.urlopen(URL)
# read the URL
html = req.read()
# decode the URL to utf-8
html = html.decode("utf_8")
print(html)
if __name__ == '__main__':
visit_baidu()Le résultat est le suivant :
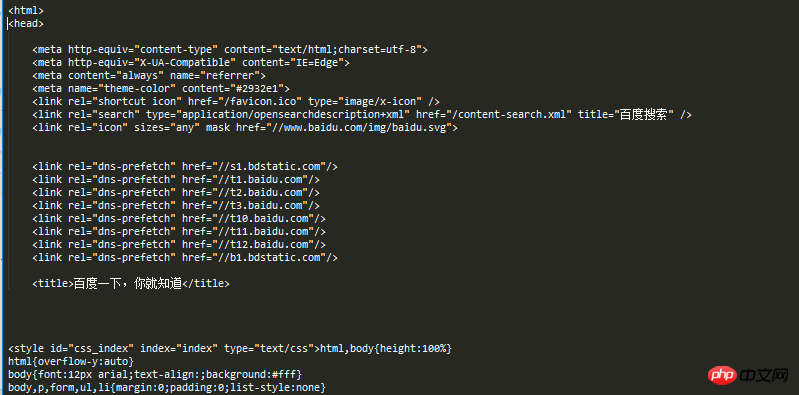
Nous pouvons comparer avec nos résultats en cours d'exécution en cliquant avec le bouton droit sur l'espace vide de la page d'accueil de Baidu pour afficher les éléments de l'évaluation.
Bien sûr, request peut également générer un objet request, qui peut être ouvert à l'aide de la méthode urlopen.
Le code est le suivant :
from urllib import request def vists_baidu(): # create a request obkect req = request.Request('http://www.baidu.com') # open the request object response = request.urlopen(req) # read the response html = response.read() html = html.decode('utf-8') print(html) if __name__ == '__main__': vists_baidu()
Le résultat de course est le même qu'avant.
(3) Gestion des erreurs
La gestion des erreurs est gérée via le module urllib Il existe principalement des erreurs URLError et HTTPError, dont l'erreur HTTPError. est une erreur URLError. Les sous-classes de HTTRPError peuvent également être détectées par URLError.
HTTPError peut être détecté via son attribut code.
Le code pour gérer HTTPError est le suivant :
from urllib import request
from urllib import error
def Err():
url = "https://segmentfault.com/zzz"
req = request.Request(url)
try:
response = request.urlopen(req)
html = response.read().decode("utf-8")
print(html)
except error.HTTPError as e:
print(e.code)
if __name__ == '__main__':
Err()Le résultat de l'exécution est tel qu'indiqué dans la figure :

404 est le code d'erreur imprimé. Vous pouvez Baidu pour obtenir des informations détaillées à ce sujet.
URLError peut être détecté via son attribut Reason.
Le code de chuliHTTPError est le suivant :
from urllib import request
from urllib import error
def Err():
url = "https://segmentf.com/"
req = request.Request(url)
try:
response = request.urlopen(req)
html = response.read().decode("utf-8")
print(html)
except error.URLError as e:
print(e.reason)
if __name__ == '__main__':
Err()Le résultat de l'exécution est tel qu'indiqué dans la figure :

Étant donné que pour gérer les erreurs, il est préférable d'écrire les deux erreurs dans le code. Après tout, plus le code est détaillé, plus il sera clair. Il convient de noter que HTTPError est une sous-classe de URLError, donc HTTPError doit être placé devant URLError, sinon URLError sera affiché, par exemple 404 étant affiché comme Introuvable.
Le code est le suivant :
from urllib import request
from urllib import error
# 第一种方法,URLErroe和HTTPError
def Err():
url = "https://segmentfault.com/zzz"
req = request.Request(url)
try:
response = request.urlopen(req)
html = response.read().decode("utf-8")
print(html)
except error.HTTPError as e:
print(e.code)
except error.URLError as e:
print(e.reason)Vous pouvez modifier l'URL pour afficher le formulaire de sortie de diverses erreurs.
Résumé
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!