
Maison >développement back-end >Tutoriel C#.Net >Décrire en détail la méthode de mise en œuvre de l'effet de pagination personnalisé d'Entity Framework
Décrire en détail la méthode de mise en œuvre de l'effet de pagination personnalisé d'Entity Framework
- 巴扎黑original
- 2017-08-06 10:53:071722parcourir
Cet article présente principalement en détail la mise en œuvre générale des effets de pagination personnalisés, des ajouts, des suppressions et des modifications basés sur Entity Framework. Il a une certaine valeur de référence. Les amis intéressés peuvent s'y référer
Introduction<.>
Code
Comment exécuter l'exemple
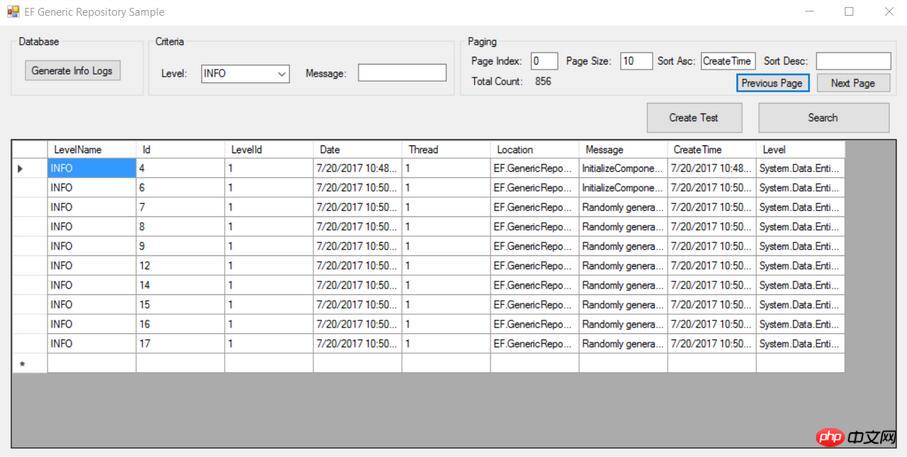
Classe de base du référentiel - requête
public virtual Tuple<IEnumerable<T>, int> Find(Expression<Func<T, bool>> criteria
, int pageIndex
, int pageSize
, string[] asc
, string[] desc
, params Expression<Func<T, object>>[] includeProperties)Cette méthode est l'une des méthodes de requête AbstractRepository et est utilisée pour personnaliser les requêtes de pagination, où le critère est un expression comme les Conditions de requête, les paramètres pageIndex, pageSize, asc, desc sont des paramètres liés à la pagination Concernant plusieurs tables (tables associées) : includeProperties est la table associée à Join lorsqu'il y en a plusieurs tableaux. Étant donné que la valeur par défaut d'EF est Lazy Loading, les tables associées ne sont pas chargées immédiatement par défaut. Ainsi, parfois, si vous ne faites pas attention lors de l'écriture du code, vous pouvez parcourir n tables de mots dans une boucle for. Utilisez le paramètre includeProperties pour rejoindre la table associée lors de la requête.
Classe de base du référentiel - ajout, suppression et modification
public virtuel T Update (entité T)
public virtuel T CreateOrUpdate (entité T)
public virtuel vide Supprimer (TId id)
var uow = new EFUnitOfWork();
var repo = uow.GetLogRepository();
repo.Create(new Log
{
LevelId = 1,
Thread = "",
Location = "Manual Creation",
Message = "This is manually created log.",
CreateTime = DateTimeOffset.Now,
Date = DateTime.Now
});
uow.Commit();Obtenez un ou plusieurs référentiels depuis UnitOfWork, partagez DBContext et ajoutez, supprimez , et modifier l'opération, et enfin uow unifie SaveChanges.
Classes dérivées de Repository
.
public class LogRepository : AbstractRepository<Log, int>
{
public LogRepository(EFContext context)
: base(context)
{
}
}À propos de la génération d'entités
Utilisez Logging pour suivre EF SQL
Modèle de spécification
public class LogSearchSpecification : ISpecification<Log>
{
public string LevelName { get; set; }
public string Message { get; set; }
public Expression<Func<Log, bool>> ToExpression()
{
return log => (log.Level.Name == LevelName || LevelName == "") &&
(log.Message.Contains(Message) || Message == "");
}
public bool IsSatisfiedBy(Log entity)
{
return (entity.Level.Name == LevelName || LevelName == "") &&
(entity.Message.Contains(Message) || Message == "");
}
} Ensuite, le code qui appelle cette méthode de requête peut clairement savoir que mes conditions de requête sont LevelName et Message. Quant à LevelName Is égal à et Message is Like sont implémentés dans LogSearchSpeficiation, obtenant une bonne encapsulation.
Enfin
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!