
Maison >développement back-end >Tutoriel Python >Algorithmes de base et couramment utilisés en Python
Algorithmes de base et couramment utilisés en Python
- 巴扎黑original
- 2017-08-02 10:27:413516parcourir
Cet article se concentre principalement sur l'apprentissage des algorithmes courants en Python, des algorithmes de tri couramment utilisés en Python, qui ont une certaine valeur de référence. Les amis intéressés peuvent se référer à
Le contenu de cette section<.>
Définition de l'algorithmeComplexité temporelle
Complexité spatiale
Exemples d'algorithmes courants
Définition de l'algorithmeL'algorithme fait référence à une description précise et complète d'une solution de résolution de problèmes. Il s'agit d'une série d'instructions claires pour résoudre des problèmes. L'algorithme représente une méthode systématique pour décrire le mécanisme stratégique de résolution de problèmes. En d’autres termes, il est possible d’obtenir le résultat requis dans un temps limité pour certains intrants standardisés. Si un algorithme est défectueux ou inapproprié pour un problème, son exécution ne résoudra pas le problème. Différents algorithmes peuvent utiliser différents temps, espace ou efficacité pour accomplir la même tâche. La qualité d’un algorithme peut être mesurée par sa complexité spatiale et sa complexité temporelle.
Un algorithme doit avoir les sept caractéristiques importantes suivantes :
①Finitité : La finitude d'un algorithme signifie que l'algorithme doit pouvoir se terminer après l'exécution d'un nombre limité d'étapes ; 🎜>②Définition : chaque étape de l'algorithme doit avoir une définition exacte ;
③Entrée : un algorithme a 0 ou plusieurs entrées pour décrire l'opérande. La situation initiale, ce qu'on appelle 0 entrées fait référence aux conditions initiales définies. par l'algorithme lui-même ;
④Sortie : Un algorithme a une ou plusieurs sorties pour refléter les résultats du traitement des données d'entrée . Un algorithme sans sortie n'a aucun sens ;
⑤Efficacité : toute étape de calcul effectuée dans l'algorithme peut être décomposée en étapes d'opération exécutables de base, c'est-à-dire que chaque étape de calcul peut toutes être complétée dans un temps limité (également appelé efficacité) ;
⑥Haute efficacité : exécution rapide et faible utilisation des ressources
⑦Robustness (Robustness) : Réponse correcte aux données ;
2. Complexité temporelle
En informatique, la complexité temporelle d'un algorithme est une fonction qui décrit quantitativement le fonctionnement de l'algorithme. Temps, complexité temporelle couramment utilisée. La notation Big O (notation Big O) est une notation mathématique utilisée pour décrire le comportement asymptotique d'une fonction. Plus précisément, il s'agit d'une fonction qui est décrite en termes d'une autre fonction (généralement plus simple) la supérieure asymptotique. limite de l'ordre de grandeur. En mathématiques, il est généralement utilisé pour caractériser les termes restants de séries infinies tronquées, notamment en informatique, il est très utile pour analyser la complexité des algorithmes, lors de l'utilisation de cette méthode. la complexité temporelle peut être considérée comme asymptotique, ce qui considère la situation dans laquelle la taille de la valeur d'entrée approche l'infini.
Big O, en bref, on peut le considérer comme signifiant « ordre de » (environ).Asymptotique infini
La notation Big O est très utile pour analyser l'efficacité d'un algorithme. Par exemple, le temps nécessaire pour résoudre un problème de taille n (ou le nombre d'étapes nécessaires) peut être trouvé : T(n) = 4n^2 - 2n + 2.
À mesure que n augmente, le terme n^2 ; commencera à dominer, et les autres termes peuvent être ignorés - par exemple : lorsque n = 500, le terme 4n^2 est 1000 fois plus grand que le terme 2n, donc , dans la plupart des cas, l'effet de l'omission de ce dernier sur la valeur de l'expression sera négligeable.
1. algorithme , il ne peut pas être calculé théoriquement et il ne peut être connu qu'en exécutant des tests sur l'ordinateur. Mais il est impossible et inutile pour nous de tester chaque algorithme sur l’ordinateur. Il nous suffit de savoir quel algorithme prend le plus de temps et quel algorithme prend le moins de temps. Et le temps que prend un algorithme est proportionnel au nombre d’exécutions d’instructions dans l’algorithme. Quel que soit l’algorithme qui a le plus d’instructions exécutées, cela prend plus de temps.
Le nombre d'exécutions d'instructions dans un algorithme est appelé fréquence d'instruction ou fréquence temporelle. Notons-le comme T(n).
2. Généralement, le nombre de fois où l'opération de base de l'algorithme est répétée est une fonction f(n) du module n. Par conséquent, la complexité temporelle de l'algorithme est enregistrée comme. : T (n)=O(f(n)). À mesure que le module n augmente, le taux de croissance du temps d'exécution de l'algorithme est proportionnel au taux de croissance de f(n). Par conséquent, plus f(n) est petit, plus la complexité temporelle de l'algorithme est faible et plus l'efficacité de l'algorithme est élevée. .
Lors du calcul de la complexité temporelle, découvrez d'abord les opérations de base de l'algorithme, puis déterminez ses temps d'exécution en fonction des instructions correspondantes, puis trouvez le même ordre de grandeur de T(n) (son même ordre de grandeur est comme suit : 1 , Log2n, n, nLog2n, n carré, n cube, 2 n puissance, n !), après avoir découvert, f (n) = cet ordre de grandeur, si T (n)/f (n) trouver la limite A constante c peut être obtenue, et la complexité temporelle T(n)=O(f(n)).
3. Les complexités temporelles courantes
Ordre constant O(1), ordre logarithmique O(. log2n), ordre linéaire O(n), ordre logarithmique linéaire O(nlog2n), ordre carré O(n^2), ordre cubique O(n^3),..., kème ordre de puissance O(n ^k), ordre exponentiel O(2^n).
Parmi eux,
1.O(n), O(n^2), ordre cubique O(n^3),..., kième ordre O(n^k) sont une complexité temporelle d'ordre polynomial, respectivement appelée temps du premier ordre complexité, complexité temporelle du second ordre. . . .
2.O(2^n), complexité temporelle exponentielle, ce genre d'impraticable
3. Ordre logarithmique O(log2n), ordre logarithmique linéaire O(nlog2n), sauf pour l'ordre constant, c'est le plus efficace
Exemple : Algorithme :
for(i=1;i<=n;++i)
{
for(j=1;j<=n;++j)
{
c[ i ][ j ]=0; //该步骤属于基本操作 执行次数:n^2
for(k=1;k<=n;++k)
c[ i ][ j ]+=a[ i ][ k ]*b[ k ][ j ]; //该步骤属于基本操作 执行次数:n^3
}
} Alors il y a T(n) = n^2+n^ 3. D'après au même ordre de grandeur dans les parenthèses ci-dessus, nous pouvons déterminer que n^3 est du même ordre de grandeur que T(n)
Ensuite nous avons f(n) = n^3, puis le trouvons selon T(n)/f(n) La limite peut être obtenue par constante c
Puis la complexité temporelle de l'algorithme : T(n)=O(n^3)
4. Définition : Si un problème L'échelle est n, et le temps nécessaire à un certain algorithme pour résoudre ce problème est T(n), qui est une certaine fonction de n T(n) est appelé le ". complexité temporelle" de cet algorithme.
Lorsque la quantité d'entrée n augmente progressivement, le cas limite de complexité temporelle est appelé la « complexité temporelle asymptotique » de l'algorithme.
Nous utilisons souvent la notation grand O pour exprimer la complexité temporelle. Notez qu'il s'agit de la complexité temporelle d'un certain algorithme. Big O signifie qu'il existe une limite supérieure. Par définition, si f(n)=O(n), alors f(n)=O(n^2) est évidemment valable. Cela vous donne une limite supérieure, mais ce n'est pas le cas. un supremum , mais les gens sont généralement habitués à exprimer le premier lorsqu'ils s'expriment.
De plus, un problème lui-même a aussi sa complexité. Si la complexité d'un algorithme atteint la limite inférieure de la complexité du problème, alors un tel algorithme est appelé le meilleur algorithme.
"Notation Big O" : Le paramètre de base utilisé dans cette description est n, la taille de l'instance du problème, exprimant la complexité ou le temps d'exécution en fonction de n. Le "O" représente ici l'ordre. Par exemple, "La recherche binaire est O(logn)", ce qui signifie qu'elle doit "récupérer un tableau de taille n via les étapes de connexion". que lorsque n augmente, le temps d'exécution augmentera tout au plus à un rythme proportionnel à f(n).
Cette estimation asymptotique est très utile pour l'analyse théorique et la comparaison approximative des algorithmes, mais les détails peuvent également entraîner des différences dans la pratique. Par exemple, un algorithme O(n2) avec une faible surcharge peut s'exécuter plus rapidement pour un petit n qu'un algorithme O(nlogn) avec une surcharge élevée. Bien entendu, à mesure que n devient suffisamment grand, les algorithmes dont les fonctions montent plus lentement doivent fonctionner plus rapidement.
O(1)
Temp=i;i=j;j=temp; le segment de programme est une constante indépendante de la taille du problème n. La complexité temporelle de l'algorithme est d'ordre constant, enregistrée sous la forme T(n)=O(1). Si le temps d'exécution de l'algorithme n'augmente pas avec l'augmentation de la taille du problème n, même s'il y a des milliers d'instructions dans l'algorithme, son temps d'exécution ne sera qu'une grande constante. La complexité temporelle de ce type d’algorithme est O(1).
O(n^2)
2.1 Échangez le contenu de i et j
sum=0; (une fois) for(i=1;ica59015e11f1d8be44741b94e836f775sous-arbre gauche->sous-arbre droit
Parcours dans l'ordre : sous-arbre gauche->nœud racine->sous-arbre droit
Parcours post-commande : sous-arbre gauche->sous-arbre droit->nœud racine
Par exemple : trouver trois parcours de l'arbre suivant
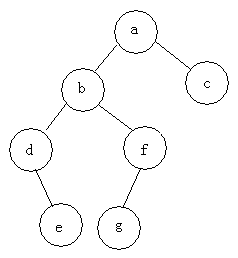
Parcours de pré-commande : abdefgc
Parcours dans l'ordre : debgfac
Parcours de post-commande : edgfbca
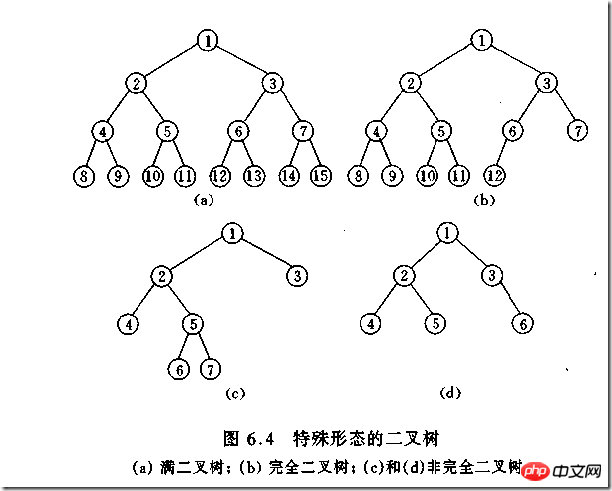
Type d'arbre binaire
(1)完全二叉树——若设二叉树的高度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第h层有叶子结点,并且叶子结点都是从左到右依次排布,这就是完全二叉树。
(2)满二叉树——除了叶结点外每一个结点都有左右子叶且叶子结点都处在最底层的二叉树。
(3)平衡二叉树——平衡二叉树又被称为AVL树(区别于AVL算法),它是一棵二叉排序树,且具有以下性质:它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树
如何判断一棵树是完全二叉树?按照定义
教材上的说法:一个深度为k,节点个数为 2^k - 1 的二叉树为满二叉树。这个概念很好理解,就是一棵树,深度为k,并且没有空位。
首先对满二叉树按照广度优先遍历(从左到右)的顺序进行编号。
一颗深度为k二叉树,有n个节点,然后,也对这棵树进行编号,如果所有的编号都和满二叉树对应,那么这棵树是完全二叉树。
如何判断平衡二叉树?
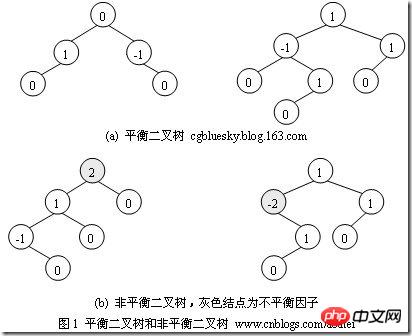
(b)左边的图 左子数的高度为3,右子树的高度为1,相差超过1
(b)右边的图 -2的左子树高度为0 右子树的高度为2,相差超过1
二叉树遍历实现
class TreeNode(object):
def __init__(self,data=0,left=0,right=0):
self.data = data
self.left = left
self.right = right
class BTree(object):
def __init__(self,root=0):
self.root = root
def preOrder(self,treenode):
if treenode is 0:
return
print(treenode.data)
self.preOrder(treenode.left)
self.preOrder(treenode.right)
def inOrder(self,treenode):
if treenode is 0:
return
self.inOrder(treenode.left)
print(treenode.data)
self.inOrder(treenode.right)
def postOrder(self,treenode):
if treenode is 0:
return
self.postOrder(treenode.left)
self.postOrder(treenode.right)
print(treenode.data)
if __name__ == '__main__':
n1 = TreeNode(data=1)
n2 = TreeNode(2,n1,0)
n3 = TreeNode(3)
n4 = TreeNode(4)
n5 = TreeNode(5,n3,n4)
n6 = TreeNode(6,n2,n5)
n7 = TreeNode(7,n6,0)
n8 = TreeNode(8)
root = TreeNode('root',n7,n8)
bt = BTree(root)
print("preOrder".center(50,'-'))
print(bt.preOrder(bt.root))
print("inOrder".center(50,'-'))
print (bt.inOrder(bt.root))
print("postOrder".center(50,'-'))
print (bt.postOrder(bt.root))堆排序
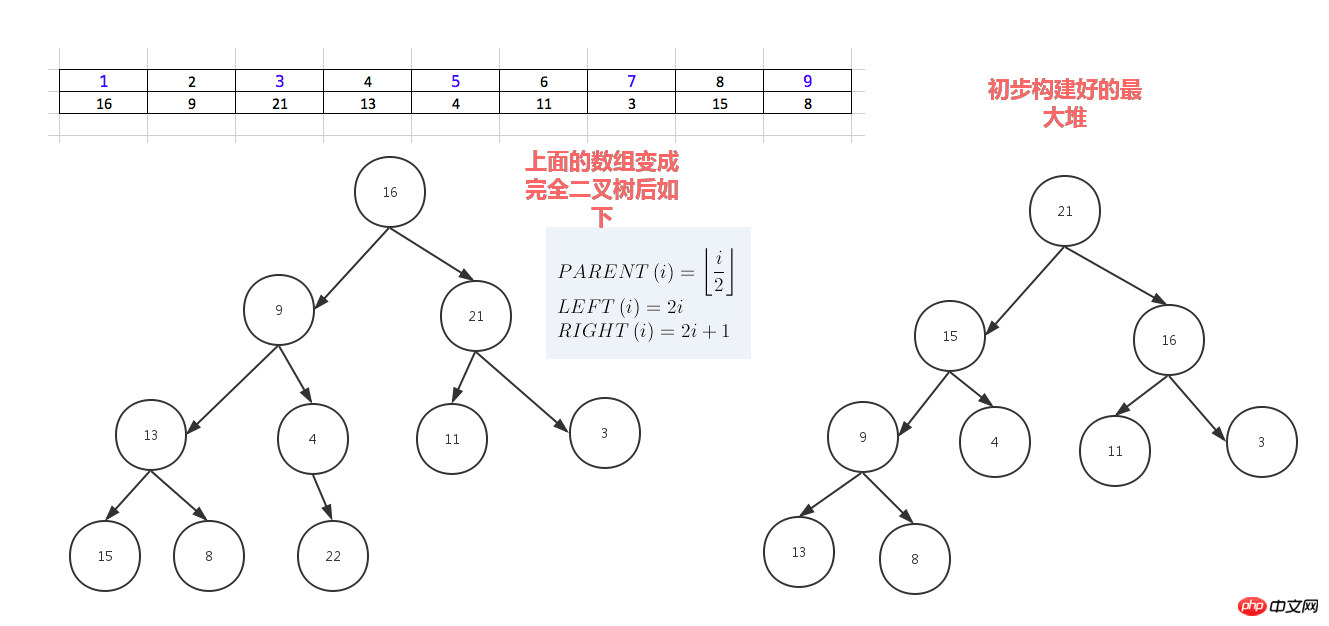
堆排序,顾名思义,就是基于堆。因此先来介绍一下堆的概念。
堆分为最大堆和最小堆,其实就是完全二叉树。最大堆要求节点的元素都要大于其孩子,最小堆要求节点元素都小于其左右孩子,两者对左右孩子的大小关系不做任何要求,其实很好理解。有了上面的定义,我们可以得知,处于最大堆的根节点的元素一定是这个堆中的最大值。其实我们的堆排序算法就是抓住了堆的这一特点,每次都取堆顶的元素,将其放在序列最后面,然后将剩余的元素重新调整为最大堆,依次类推,最终得到排序的序列。
堆排序就是把堆顶的最大数取出,
将剩余的堆继续调整为最大堆,具体过程在第二块有介绍,以递归实现
剩余部分调整为最大堆后,再次将堆顶的最大数取出,再将剩余部分调整为最大堆,这个过程持续到剩余数只有一个时结束
#_*_coding:utf-8_*_
__author__ = 'Alex Li'
import time,random
def sift_down(arr, node, end):
root = node
#print(root,2*root+1,end)
while True:
# 从root开始对最大堆调整
child = 2 * root +1 #left child
if child > end:
#print('break',)
break
print("v:",root,arr[root],child,arr[child])
print(arr)
# 找出两个child中交大的一个
if child + 1 <= end and arr[child] < arr[child + 1]: #如果左边小于右边
child += 1 #设置右边为大
if arr[root] < arr[child]:
# 最大堆小于较大的child, 交换顺序
tmp = arr[root]
arr[root] = arr[child]
arr[child]= tmp
# 正在调整的节点设置为root
#print("less1:", arr[root],arr[child],root,child)
root = child #
#[3, 4, 7, 8, 9, 11, 13, 15, 16, 21, 22, 29]
#print("less2:", arr[root],arr[child],root,child)
else:
# 无需调整的时候, 退出
break
#print(arr)
print('-------------')
def heap_sort(arr):
# 从最后一个有子节点的孩子还是调整最大堆
first = len(arr) // 2 -1
for i in range(first, -1, -1):
sift_down(arr, i, len(arr) - 1)
#[29, 22, 16, 9, 15, 21, 3, 13, 8, 7, 4, 11]
print('--------end---',arr)
# 将最大的放到堆的最后一个, 堆-1, 继续调整排序
for end in range(len(arr) -1, 0, -1):
arr[0], arr[end] = arr[end], arr[0]
sift_down(arr, 0, end - 1)
#print(arr)
def main():
# [7, 95, 73, 65, 60, 77, 28, 62, 43]
# [3, 1, 4, 9, 6, 7, 5, 8, 2, 10]
#l = [3, 1, 4, 9, 6, 7, 5, 8, 2, 10]
#l = [16,9,21,13,4,11,3,22,8,7,15,27,0]
array = [16,9,21,13,4,11,3,22,8,7,15,29]
#array = []
#for i in range(2,5000):
# #print(i)
# array.append(random.randrange(1,i))
print(array)
start_t = time.time()
heap_sort(array)
end_t = time.time()
print("cost:",end_t -start_t)
print(array)
#print(l)
#heap_sort(l)
#print(l)
if __name__ == "__main__":
main()人类能理解的版本
dataset = [16,9,21,3,13,14,23,6,4,11,3,15,99,8,22]
for i in range(len(dataset)-1,0,-1):
print("-------",dataset[0:i+1],len(dataset),i)
#for index in range(int(len(dataset)/2),0,-1):
for index in range(int((i+1)/2),0,-1):
print(index)
p_index = index
l_child_index = p_index *2 - 1
r_child_index = p_index *2
print("l index",l_child_index,'r index',r_child_index)
p_node = dataset[p_index-1]
left_child = dataset[l_child_index]
if p_node < left_child: # switch p_node with left child
dataset[p_index - 1], dataset[l_child_index] = left_child, p_node
# redefine p_node after the switch ,need call this val below
p_node = dataset[p_index - 1]
if r_child_index < len(dataset[0:i+1]): #avoid right out of list index range
#if r_child_index < len(dataset[0:i]): #avoid right out of list index range
#print(left_child)
right_child = dataset[r_child_index]
print(p_index,p_node,left_child,right_child)
# if p_node < left_child: #switch p_node with left child
# dataset[p_index - 1] , dataset[l_child_index] = left_child,p_node
# # redefine p_node after the switch ,need call this val below
# p_node = dataset[p_index - 1]
#
if p_node < right_child: #swith p_node with right child
dataset[p_index - 1] , dataset[r_child_index] = right_child,p_node
# redefine p_node after the switch ,need call this val below
p_node = dataset[p_index - 1]
else:
print("p node [%s] has no right child" % p_node)
#最后这个列表的第一值就是最大堆的值,把这个最大值放到列表最后一个, 把神剩余的列表再调整为最大堆
print("switch i index", i, dataset[0], dataset[i] )
print("before switch",dataset[0:i+1])
dataset[0],dataset[i] = dataset[i],dataset[0]
print(dataset)希尔排序(shell sort)
希尔排序(Shell Sort)是插入排序的一种。也称缩小增量排序,是直接插入排序算法的一种更高效的改进版本,该方法的基本思想是:先将整个待排元素序列分割成若干个子序列(由相隔某个“增量”的元素组成的)分别进行直接插入排序,然后依次缩减增量再进行排序,待整个序列中的元素基本有序(增量足够小)时,再对全体元素进行一次直接插入排序。因为直接插入排序在元素基本有序的情况下(接近最好情况),效率是很高的,因此希尔排序在时间效率比直接插入排序有较大提高
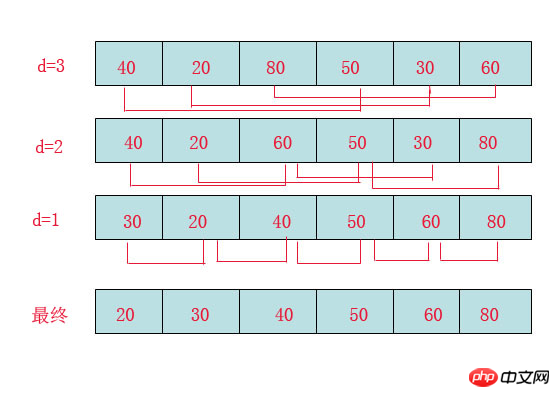
首先要明确一下增量的取法:
第一次增量的取法为: d=count/2;
第二次增量的取法为: d=(count/2)/2;
最后一直到: d=1;
看上图观测的现象为:
d=3时:将40跟50比,因50大,不交换。
将20跟30比,因30大,不交换。
将80跟60比,因60小,交换。
d=2时:将40跟60比,不交换,拿60跟30比交换,此时交换后的30又比前面的40小,又要将40和30交换,如上图。
将20跟50比,不交换,继续将50跟80比,不交换。
d=1时:这时就是前面讲的插入排序了,不过此时的序列已经差不多有序了,所以给插入排序带来了很大的性能提高。
希尔排序代码
import time,random
#source = [8, 6, 4, 9, 7, 3, 2, -4, 0, -100, 99]
#source = [92, 77, 8,67, 6, 84, 55, 85, 43, 67]
source = [ random.randrange(10000+i) for i in range(10000)]
#print(source)
step = int(len(source)/2) #分组步长
t_start = time.time()
while step >0:
print("---step ---", step)
#对分组数据进行插入排序
for index in range(0,len(source)):
if index + step < len(source):
current_val = source[index] #先记下来每次大循环走到的第几个元素的值
if current_val > source[index+step]: #switch
source[index], source[index+step] = source[index+step], source[index]
step = int(step/2)
else: #把基本排序好的数据再进行一次插入排序就好了
for index in range(1, len(source)):
current_val = source[index] # 先记下来每次大循环走到的第几个元素的值
position = index
while position > 0 and source[
position - 1] > current_val: # 当前元素的左边的紧靠的元素比它大,要把左边的元素一个一个的往右移一位,给当前这个值插入到左边挪一个位置出来
source[position] = source[position - 1] # 把左边的一个元素往右移一位
position -= 1 # 只一次左移只能把当前元素一个位置 ,还得继续左移只到此元素放到排序好的列表的适当位置 为止
source[position] = current_val # 已经找到了左边排序好的列表里不小于current_val的元素的位置,把current_val放在这里
print(source)
t_end = time.time() - t_start
print("cost:",t_end)Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!