
Maison >développement back-end >tutoriel php >Compréhension approfondie de l'optimisation des opcodes en php (images et texte)
Compréhension approfondie de l'optimisation des opcodes en php (images et texte)

- 黄舟original
- 2017-07-18 15:33:162372parcourir
1. Présentation
PHP (la version PHP des cas mentionnés dans cet article est tous 7.1.3) est un langage de script dynamique. Son processus d'exécution dans la machine virtuelle zend est le suivant : lire le programme de script. chaîne, et l'analyseur lexical le convertit en symboles de mots, puis l'analyseur de syntaxe découvre la structure grammaticale et génère un arbre de syntaxe abstrait, puis le compilateur statique génère un opcode, et enfin l'interpréteur simule des instructions machine pour exécuter chaque opcode.
Dans l'ensemble du processus ci-dessus, l'opcode généré peut appliquer des techniques d'optimisation de compilation telles que la suppression de code mort, la propagation constante conditionnelle, l'inlining de fonctions et d'autres optimisations pour rationaliser l'opcode afin d'améliorer les performances d'exécution du code.
L'extension PHP opcache prend en charge l'optimisation de la mise en cache pour l'opcode généré en fonction de la mémoire partagée. Sur cette base, l'optimisation de la compilation statique de l'opcode est ajoutée. L'optimisation décrite ici est généralement gérée par un optimiseur (Optimizer). Dans le principe de compilation, chaque optimisation est généralement décrite par une passe d'optimisation (Opt pass).
De manière générale, il existe deux types de passes d'optimisation :
L'une est la passe d'analyse, qui fournit des informations d'analyse du flux de données et du flux de contrôle pour fournir des informations auxiliaires pour le passe de conversion ;
L'une est la passe de conversion, qui modifiera le code généré, y compris l'ajout et la suppression d'instructions, la modification des instructions de remplacement, l'ajustement de l'ordre des instructions, etc. le code généré peut être vidé avant et après chaque passe.
Cet article est basé sur le principe de compilation, combiné à l'optimiseur fourni par l'extension opcache, et prend l'unité de base de la compilation PHP op_array et la plus petite unité de l'opcode d'exécution PHP comme point de départ. Cet article présente l'application de la technologie d'optimisation de compilation dans la machine virtuelle Zend et explique comment chaque passe d'optimisation optimise l'opcode étape par étape pour améliorer les performances d'exécution du code. Enfin, quelques perspectives sont données basées sur l'exécution de la machine virtuelle du langage PHP.
2. Plusieurs explications de concepts
1) Compilation statique/exécution d'interprétation/compilation juste à temps
Compilation statique, également appelée compilation anticipée), appelé AOT. Autrement dit, le code source est compilé en code cible et, une fois exécuté, il s'exécute sur une plate-forme prenant en charge le code cible.
La compilation dynamique, par rapport à la compilation statique, fait référence à la « compilation au moment de l'exécution ». Habituellement, un interpréteur est utilisé pour la compilation et l’exécution, ce qui fait référence à l’interprétation et à l’exécution de la langue source une par une.
Compilation JIT (compilation juste à temps), c'est-à-dire compilation juste à temps, au sens étroit signifie qu'un certain morceau de code est compilé lorsqu'il est sur le point d'être exécuté pour la première fois temps, puis exécuté directement sans compilation. C'est un type de compilation dynamique.
Les trois types ci-dessus de différents processus d'exécution de compilation peuvent être grossièrement décrits comme suit : 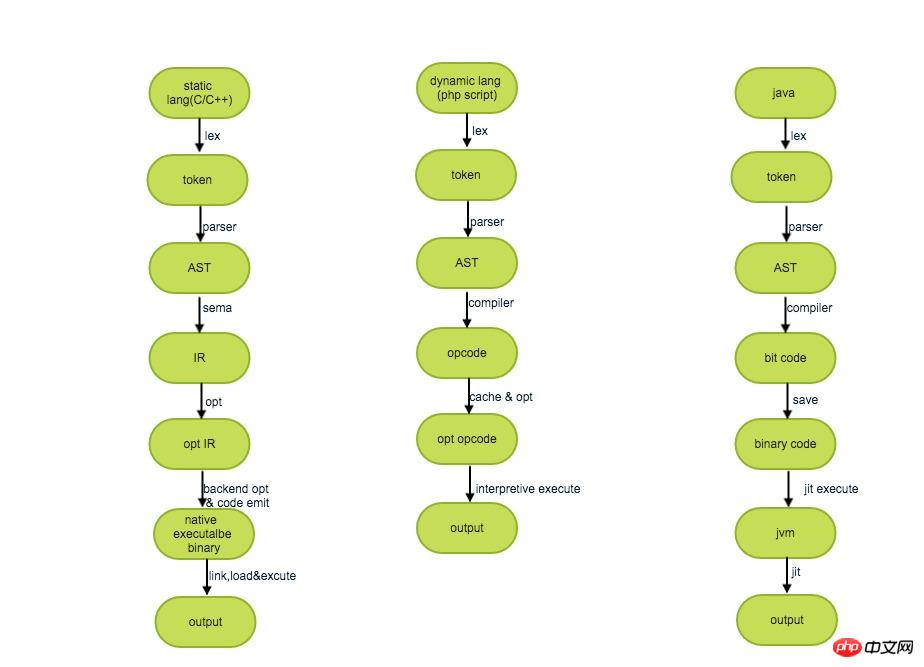
2) Flux de données/flux de contrôle
Une optimisation de la compilation doit être obtenue du programme Assez d'informations, c'est la base de toute optimisation de compilation.
Le résultat généré par le front-end du compilateur peut être un arbre syntaxique ou une sorte de code intermédiaire de bas niveau. Mais quelle que soit la forme que prend le résultat, il ne vous dit toujours pas grand-chose sur ce que fait le programme ni sur la manière dont il le fait. Le compilateur laisse à l'analyse des flux de contrôle la tâche de découvrir la hiérarchie des flux de contrôle au sein de chaque procédure et à l'analyse des flux de données la tâche de déterminer les informations globales pertinentes pour le traitement des données.
Le flux de contrôle est une méthode d'analyse formelle permettant d'obtenir des informations sur la structure de contrôle du programme. Il constitue la base de l'analyse du flux de données et de l'analyse des dépendances. Un modèle de contrôle de base est le Control Flow Graph (CFG). Il existe deux manières d'analyser le flux de contrôle d'un processus unique : en utilisant les nœuds nécessaires pour trouver les boucles et l'analyse par intervalles.
Le flux de données collecte les informations sémantiques du programme à partir du code du programme et détermine la définition et l'utilisation des variables au moment de la compilation grâce à des méthodes algébriques. Un modèle de base de données est le Data Flow Graph (DFG). L'analyse de flux de données courante est une analyse de flux de données basée sur un arbre de contrôle, et les algorithmes sont divisés en analyse par intervalles et analyse structurelle.
3) op_array
est similaire au concept de stack frame en langage C, qui est l'unité de base (une frame) d'un programme en cours d'exécution, généralement une -fonction time L'unité de base à appeler. Ici, une fonction ou une méthode, l'intégralité du fichier de script PHP et la chaîne passée à eval pour représenter le code PHP seront compilés dans un op_array.
Dans l'implémentation, op_array est une structure qui contient toutes les informations de l'unité de base du fonctionnement du programme. Bien sûr, le tableau opcode est le champ le plus important de la structure, mais en plus il contient également des types de variables, informations d'annotation et informations de capture d'exception, informations de saut, etc.
4) opcode
Le processus d'exécution de l'interpréteur (ZendVM) consiste à exécuter l'opcode optimisé minimum dans une unité de base op_array, à parcourir l'exécution dans l'ordre, à exécuter l'opcode actuel et à pré-récupérer l'opcode suivant, jusqu'au dernier RETRUN, cet opcode spécial revient pour quitter.
L'opcode ici est également similaire à la représentation intermédiaire dans le compilateur statique (similaire à LLVM IR). Il prend généralement la forme d'un code à trois adresses, qui comprend un opérateur, deux opérandes et un résultat d'opération. . Les deux opérandes contiennent des informations de type. Il existe cinq types d'informations de type ici, à savoir :
Variable compilée (CV en abrégé). Les variables de compilation sont les variables définies dans le script php.
Les variables internes réutilisables (VAR), variables temporaires utilisées par ZendVM, peuvent être partagées avec d'autres opcodes.
Les variables internes non réutilisables (TMP_VAR), variables temporaires utilisées par ZendVM, ne peuvent pas être partagées avec d'autres opcodes.
Constante (CONST), constante en lecture seule, la valeur ne peut pas être modifiée.
Variable inutile (INUTILISÉE). Puisque l'opcode utilise trois codes d'adresse, tous les opcodes n'ont pas de champ d'opérande. Par défaut, cette variable est utilisée pour compléter le champ.
Les informations de type ainsi que l'opérateur permettent à l'exécuteur de faire correspondre et de sélectionner un modèle de bibliothèque de fonctions C compilé spécifique, ainsi que de simuler et de générer des instructions machine pour l'exécution.
L'opcode est représenté par la structure zend_op dans ZendVM. Sa structure principale est la suivante : 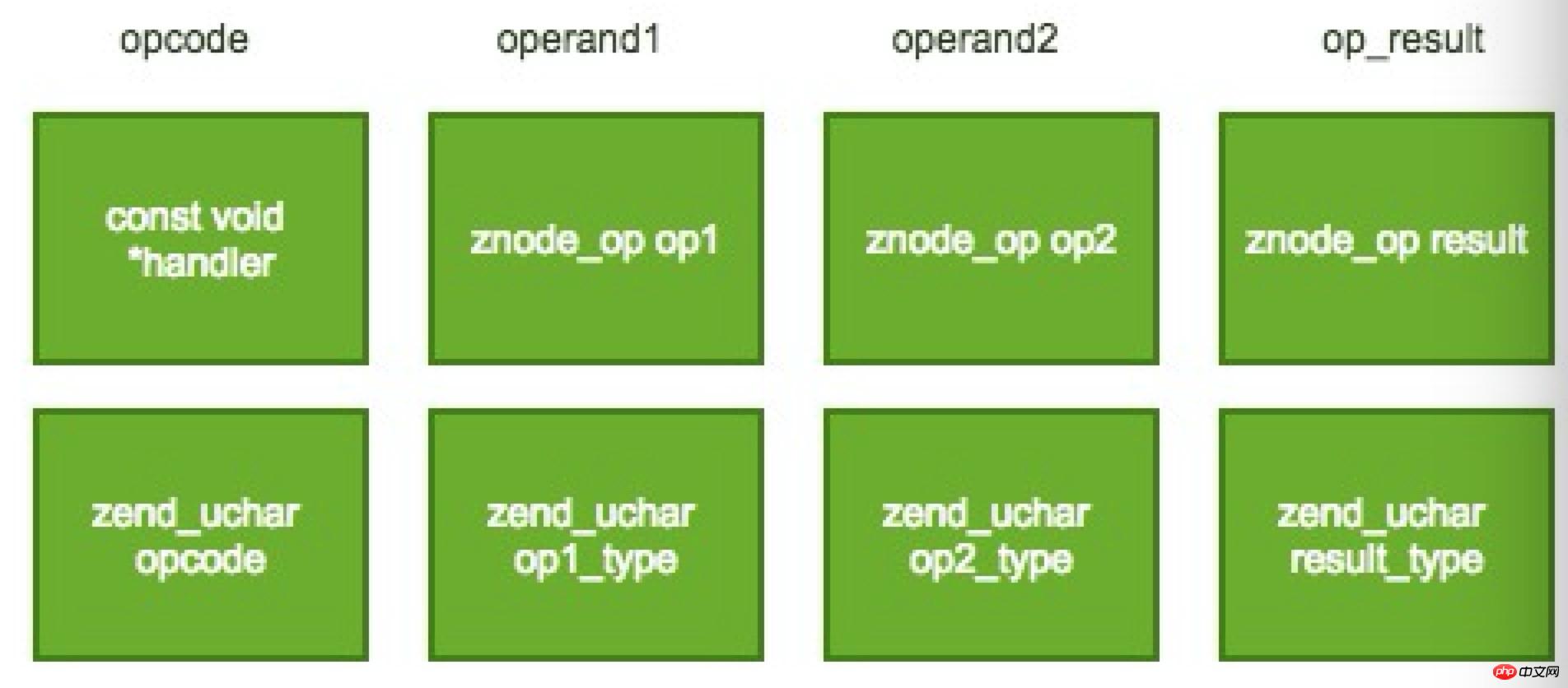
3.opcache optimiseur
Le script PHP passe par. lexical Après analyse et analyse syntaxique pour générer la structure arborescente de syntaxe abstraite, l'opcode est généré via une compilation statique. En tant que plateforme commune d'exécution d'instructions sur différentes machines virtuelles, elle s'appuie sur l'implémentation spécifique de différentes machines virtuelles (mais pour PHP, la plupart d'entre elles font référence à ZendVM).
Avant que la machine virtuelle n'exécute l'opcode, si vous optimisez l'opcode, vous pouvez obtenir du code avec une efficacité d'exécution plus élevée. La fonction de pass est d'optimiser l'opcode, de traiter l'opcode, d'analyser l'opcode, de rechercher. opportunités d'optimisation et modification de l'opcode pour produire du code avec une efficacité d'exécution plus élevée.
1) Introduction à l'optimiseur ZendVM
Dans la machine virtuelle Zend (ZendVM), l'optimiseur de code statique d'opcache est l'optimisation d'opcode zend.
Afin d'observer l'effet d'optimisation et de faciliter le débogage, il fournit également des options d'optimisation et de débogage :
optimisationniveau (opcache.optimizationlevel =0xFFFFFFFF ), la plupart des passes d'optimisation sont activées par défaut et les utilisateurs peuvent également contrôler leur désactivation en transmettant les paramètres de ligne de commande
optdebuglevel (opcache.opt debuglevel=-1) Niveau de débogage, non activé par défaut, mais fournit le processus de transformation de l'opcode avant et après chaque optimisation
Le Les informations de contexte de script requises pour effectuer une optimisation statique sont encapsulées dans la structure zend_script, elles se présentent comme suit :
typedef struct _zend_script {
zend_string *filename; //文件名
zend_op_array main_op_array; //栈帧
HashTable function_table; //函数单位符号表信息
HashTable class_table; //类单位符号表信息
} zend_script;Les trois informations de contenu ci-dessus sont transmises comme paramètres d'entrée à l'optimiseur pour analyse et optimisation. Bien sûr, similaire à l'extension PHP habituelle, elle constitue avec le module de cache opcode (zend_accel) l'extension opcache. Il embarque trois API internes dans l'accélérateur de cache :
zendoptimizerstartup startup optimiseur
zendoptimize l'optimiseur de script implémente la logique principale de l'optimisation
zendoptimiseurarrête le nettoyage des ressources généré par l'optimiseur
Concernant la mise en cache des opcodes, c'est aussi une optimisation très importante de l'opcode. Son principe d'application de base est à peu près le suivant :
Bien que PHP soit un langage de script dynamique, il n'appelle pas directement un ensemble complet de chaînes d'outils de compilateur telles que GCC/LLVM, ni un simple front-end. compilateur tel que Javac. Mais chaque fois qu'un script PHP doit être exécuté, il passe par le cycle de vie complet du lexique, de la syntaxe, de la compilation en opcode et de l'exécution de la VM.
Les trois premières étapes, à l'exception de l'exécution, sont essentiellement le processus complet d'un compilateur frontal. Cependant, ce processus de compilation n'est pas rapide. Si le même script est exécuté à plusieurs reprises, le temps de compilation des trois premières étapes limitera sérieusement l'efficacité du fonctionnement, mais l'opcode généré par chaque compilation ne changera pas. Par conséquent, l'opcode peut être mis en cache à un certain endroit lors de la première compilation. L'extension opcache le met en cache dans la mémoire partagée (Java l'enregistre dans un fichier la prochaine fois). Le script est exécuté. Cela permet de gagner du temps de compilation.
Le processus de mise en cache des opcodes de l'extension opcache est à peu près le suivant : 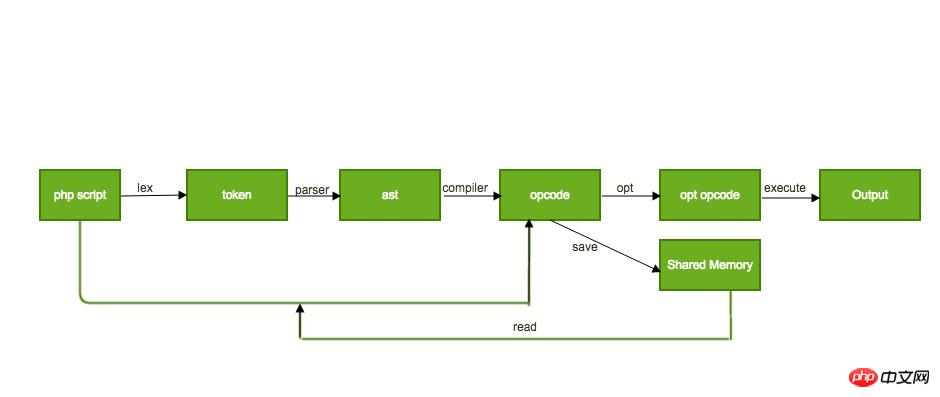 Étant donné que cet article se concentre principalement sur les passes d'optimisation statique, l'implémentation spécifique de l'optimisation du cache ne sera pas abordée ici.
Étant donné que cet article se concentre principalement sur les passes d'optimisation statique, l'implémentation spécifique de l'optimisation du cache ne sera pas abordée ici.
2) Principe de l'optimiseur ZendVM
Selon le "Whale Book" ("Advanced Compiler Design and Implementation"), une séquence de passes d'optimisation plus raisonnable pour un compilateur d'optimisation est la suivante : 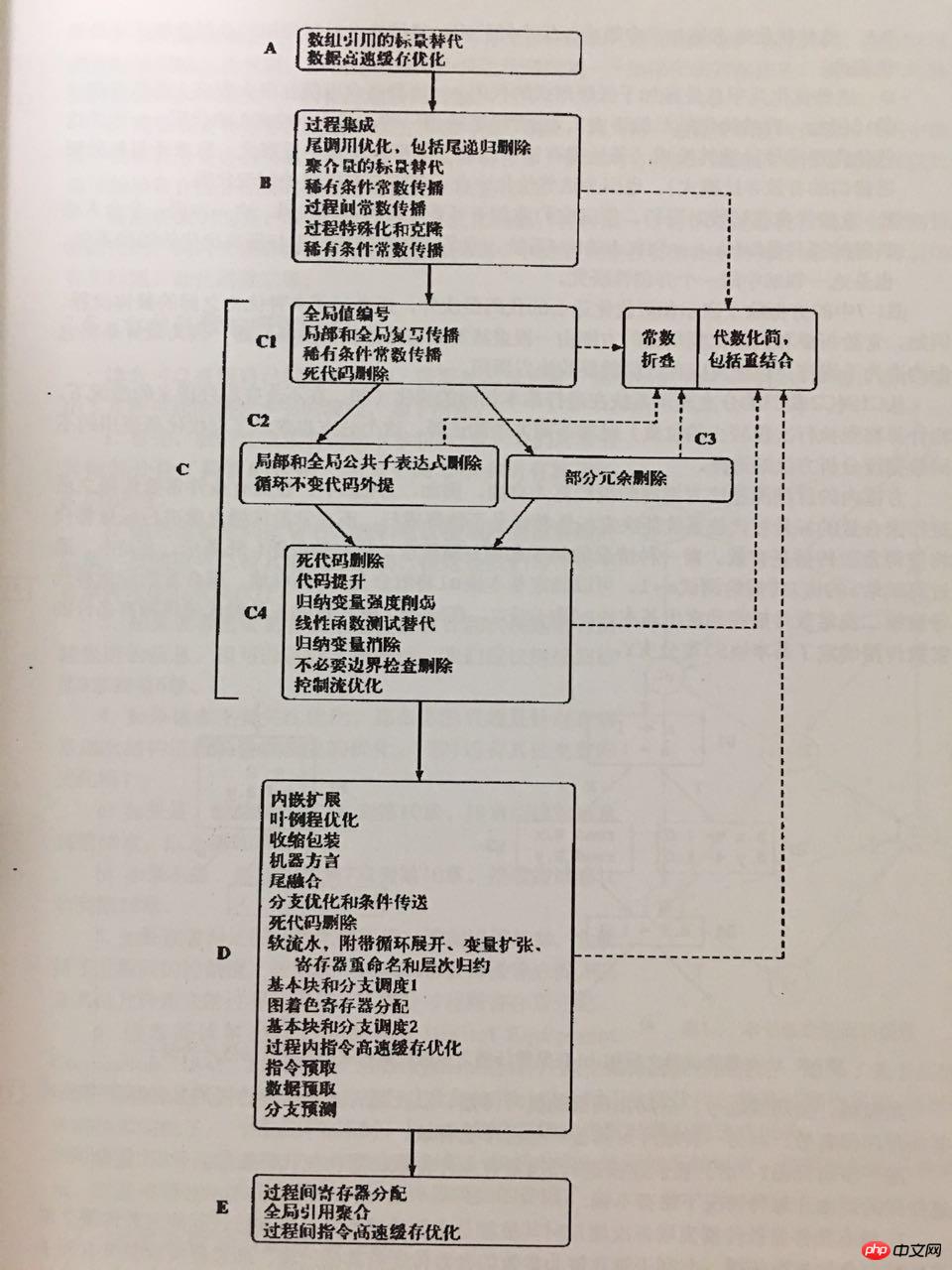
Les optimisations impliquées dans la figure ci-dessus vont des constantes simples et du code mort aux boucles et sauts de branche, des appels de fonction à l'optimisation inter-procédures, de la prélecture et de la mise en cache au pipeline logiciel et à l'allocation de registres, et bien sûr incluent également des données. flux, analyse du flux de contrôle.
Bien sûr, l'optimiseur d'opcode actuel n'implémente pas toutes les passes d'optimisation ci-dessus, et il n'est pas nécessaire d'implémenter des optimisations de représentation intermédiaire de bas niveau liées à la machine telles que l'allocation de registres.
Après avoir reçu les informations sur les paramètres de script ci-dessus, l'optimiseur opcache trouve l'unité de compilation minimale. Sur cette base, selon la macro de passe d'optimisation et sa macro de niveau d'optimisation correspondante, la commande d'enregistrement d'une certaine passe peut être réalisée.
Parmi les optimisations enregistrées, chaque optimisation est organisée en série dans un certain ordre, y compris l'optimisation constante, la suppression de nop redondante, la passe de conversion d'optimisation d'appel de fonction et les passes d'analyse telles que l'analyse du flux de données, l'analyse du flux de contrôle et analyse de la relation d'appel. Le script
zendoptimize et le processus d'enregistrement de l'optimisation réel zend_optimize sont les suivants :
zend_optimize_script(zend_script *script,
zend_long optimization_level, zend_long debug_level)
|zend_optimize_op_array(&script->main_op_array, &ctx);
遍历二元操作符的常量操作数,由运行时转化为编译时(反向pass2)
实际优化pass,zend_optimize
遍历二元操作符的常量操作数,由编译时转化为运行时(pass2)
|遍历op_array内函数zend_optimize_op_array(op_array, &ctx);
|遍历类内非用户函数zend_optimize_op_array(op_array, &ctx);
(用户函数设static_variables)
|若使用DFA pass & 调用图pass & 构建调用图成功
遍历二元操作符的常量操作数,由运行时转化为编译时(反向pass2)
设置函数返回值信息,供SSA数据流分析使用
遍历调用图的op_array,做DFA分析zend_dfa_analyze_op_array
遍历调用图的op_array,做DFA优化zend_dfa_optimize_op_array
若开调试,遍历dump调用图的每一个op_array(优化变换后)
若开栈矫正优化,矫正栈大小adjust_fcall_stack_size_graph
再次遍历调用图内的的所有op_array,
针对DFA pass变换后新产生的常量场景,常量优化pass2再跑一遍
调用图op_array资源清理
|若开栈矫正优化
矫正栈大小main_op_array
遍历矫正栈大小op_array
|清理资源该部分主要调用了SSA/DFA/CFG这几类用于opcode分析pass,涉及的pass有BB块、CFG、DFA(CFG、DOMINATORS、LIVENESS、PHI-NODE、SSA)。
用于opcode转换的pass则集中在函数zend_optimize内,如下:
zend_optimize |op_array类型为ZEND_EVAL_CODE,不做优化 |开debug, 可dump优化前内容 |优化pass1, 常量替换、编译时常量操作变换、简单操作转换 |优化pass2 常量操作转换、条件跳转指令优化 |优化pass3 跳转指令优化、自增转换 |优化pass4 函数调用优化(主要为函数调用优化) |优化pass5 控制流图(CFG)优化 |构建流图 |计算数据依赖 |划分BB块(basic block,简称BB,数据流分析基本单位) |BB块内基于数据流分析优化 |BB块间跳转优化 |不可到达BB块删除 |BB块合并 |BB块外变量检查 |重新构建优化后的op_array(基于CFG) |析构CFG |优化pass6/7 数据流分析优化 |数据流分析(基于静态单赋值SSA) |构建SSA |构建CFG 需要找到对应BB块序号、管理BB块数组、计算BB块后继BB、标记可到达BB块、计算BB块前驱BB |计算Dominator树 |标识循环是否可简化(主要依赖于循环回边) |基于phi节点构建完SSA def集、phi节点位置、SSA构造重命名 |计算use-def链 |寻找不当依赖、后继、类型及值范围值推断 |数据流优化 基于SSA信息,一系列BB块内opcode优化 |析构SSA |优化pass9 临时变量优化 |优化pass10 冗余nop指令删除 |优化pass11 压缩常量表优化
还有其他一些优化遍如下:
优化pass12 矫正栈大小 优化pass15 收集常量信息 优化pass16 函数调用优化,主要是函数内联优化
除此之外,pass 8/13/14可能为预留pass id。由此可看出当前提供给用户选项控制的opcode转换pass有13个。但是这并不计入其依赖的数据流/控制流的分析pass。
3)函数内联pass的实现
通常在函数调用过程中,由于需要进行不同栈帧间切换,因此会有开辟栈空间、保存返回地址、跳转、返回到调用函数、返回值、回收栈空间等一系列函数调用开销。因此对于函数体适当大小情况下,把整个函数体嵌入到调用者(Caller)内部,从而不实际调用被调用者(Callee)是一个提升性能的利器。
由于函数调用与目标机的应用二进制接口(ABI)强相关,静态编译器如GCC/LLVM的函数内联优化基本是在指令生成之前完成。
ZendVM的内联则发生在opcode生成后的FCALL指令的替换优化,pass id为16,其原理大致如下:
| 遍历op_array中的opcode,找到DO_XCALL四个opcode之一
| opcode ZEND_INIT_FCALL
| opcode ZEND_INIT_FCALL_BY_NAMEZ
| 新建opcode,操作码置为ZEND_INIT_FCALL,计算栈大小,
更新缓存槽位,析构常量池字面量,替换当前opline的opcode
| opcode ZEND_INIT_NS_FCALL_BY_NAME
| 新建opcode,操作码置为ZEND_INIT_FCALL,计算栈大小,
更新缓存槽位,析构常量池字面量,替换当前opline的opcode
| 尝试函数内联
| 优化条件过滤 (每个优化pass通常有较多限制条件,某些场景下
由于缺乏足够信息不能优化或出于代价考虑而排除)
| 方法调用ZEND_INIT_METHOD_CALL,直接返回不内联
| 引用传参,直接返回不内联
| 缺省参数为命名常量,直接返回不内联
| 被调用函数有返回值,添加一条ZEND_QM_ASSIGN赋值opcode
| 被调用函数无返回值,插入一条ZEND_NOP空opcode
| 删除调用被内联函数的call opcode(即当前online的前一条opcode)如下示例代码,当调用fname()时,使用字符串变量名fname来动态调用函数foo,而没有使用直接调用的方式。此时可通过VLD扩展查看其生成的opcode,或打开opcache调试选项(opcache.optdebuglevel=0xFFFFFFFF)亦可查看。
function foo() { }
$fname = 'foo';开启debug后dump可看出,发生函数调用优化前opcode序列(仅截取片段)为:
ASSIGN CV0($fname) string("foo")
INIT_FCALL_BY_NAME 0 CV0($fname)
DO_FCALL_BY_NAMEINIT_FCALL_BY_NAME这条opcode执行逻辑较为复杂,当开启激进内联优化后,可将上述指令序列直接合并成一条DO_FCALL string("foo")指令,省去间接调用的开销。这样也恰好与直接调用生成的opcode一致。
4)如何为opcache opt添加一个优化pass
根据以上描述,可见向当前优化器加入一个pass并不会太难,大体步骤如下:
先向zend_optimize优化器注册一个pass宏(例如添加pass17),并决定其优化级别。
在优化管理器某个优化pass前后调用加入的pass(例如添加一个尾递归优化pass),建议在DFA/SSA分析pass之后添加,因为此时获得的优化信息更多。
实现新加入的pass,进行定制代码转换(例如zendoptimizefunc_calls实现一个尾递归优化)。针对当前已有pass,主要添加转换pass,这里一般也可利用SSA/DFA的信息。不同于静态编译优化一般是在贴近于机器相关的低层中间表示优化,这里主要是在opcode层的opcode/operand相应的一些转换。
实现pass前,与函数内联类似,通常首先收集优化所需信息,然后排除掉不适用该优化的一些场景(如非真正的尾不递归调用、参数问题无法做优化等)。实现优化后,可dump优化前后生成opcode结构的变化是否优化正确、是否符合预期(如尾递归优化最终的效果是变换函数调用为forloop的形式)。
4.一点思考
以下是对基于动态的PHP脚本程序执行的一些看法,仅供参考。
由于LLVM从前端到后端,从静态编译到jit整个工具链框架的支持,使得许多语言虚拟机都尝试整合。当前PHP7时代的ZendVM官方还没采用,原因之一虚拟机opcode承载着相当复杂的分析工作。相比于静态编译器的机器码每一条指令通常只干一件事情(通常是CPU指令时钟周期),opcode的操作数(operand)由于类型不固定,需要在运行期间做大量的类型检查、转换才能进行运算,这极度影响了执行效率。即使运行时采用jit,以byte code为单位编译,编译出的字节码也会与现有解释器一条一条opcode处理类似,类型需要处理、也不能把zval值直接存在寄存器。
以函数调用为例,比较现有的opcode执行与静态编译成机器码执行的区别,如下图:
类型推断
在不改变现有opcode设计的前提下,加强类型推断能力,进而为opcode的执行提供更多的类型信息,是提高执行性能的可选方法之一。
多层opcode
既然opcode承担如此复杂的分析工作,能否将其分解成多层的opcode归一化中间表示( intermediate representation, IR)。各优化可选择应用哪一层中间表示,传统编译器的中间表示依据所携带信息量、从抽象的高级语言到贴近机器码,分成高级中间表示(HIR) 、中级中间表示(MIR)、低级中间表示(LIR)。
Gestion des pass
Concernant la gestion optimisée des pass de l'opcode, comme mentionné dans l'article précédent, il devrait y avoir des marges d'amélioration. Bien que l'analyse actuelle repose sur l'analyse des flux de données/flux de contrôle, il existe encore un manque d'analyse et d'optimisation entre les processus, tels que l'ordre de passage, le nombre d'exécutions, la gestion des enregistrements, le vidage des informations sur l'analyse des passes complexes, etc. encore manquant par rapport aux frameworks matures comme llvm. Large gap.
JIT
ZendVM implémente un grand nombre de valeurs zval, de conversion de type et d'autres opérations, qui peuvent être compilées en code machine pour l'exécution à l'aide de LLVM, mais au prix d'un processus extrêmement rapide. extension du temps de compilation. Bien entendu, libjit peut également être utilisé.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Tous les symboles d'expression dans les expressions régulières (résumé)