
Maison >Java >javaDidacticiel >Exemple d'analyse de la façon dont Java utilise dom4j pour générer et analyser des documents XML (image) ?
Exemple d'analyse de la façon dont Java utilise dom4j pour générer et analyser des documents XML (image) ?

- 黄舟original
- 2018-05-29 17:45:252115parcourir
Cet article présente principalement la méthode Java utilisant dom4j pour générer et analyser des documents XML. Il analyse les compétences opérationnelles associées de Java basées sur dom4j pour faire fonctionner des nœuds XML afin de générer et analyser des documents XML sous forme d'exemples. ceux qui en ont besoin peuvent s'y référer
L'exemple de cet article décrit comment utiliser dom4j pour générer et analyser des documents XML en Java. Partagez-le avec tout le monde pour votre référence, les détails sont les suivants :
xml est un nouveau format de données, principalement utilisé pour l'échange de données. Les frameworks que nous utilisons impliquent tous du XML. Par conséquent, analyser ou générer du XML constitue également une difficulté technique pour les programmeurs. Ici, nous utilisons dom4j pour générer un document. Il est à noter que chaque document XML n'a qu'un seul nœud racine.
package org.lxh;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.UnsupportedEncodingException;
import org.dom4j.Document;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.OutputFormat;
import org.dom4j.io.XMLWriter;
public class CreateXml {
public static void main(String[] args) {
File f=new File("d:"+File.separator+"my.xml");
Document docu=DocumentHelper.createDocument(); //创建xml文档
Element linkman=docu.addElement("linkman"); //创建根节点
Element name=linkman.addElement("name"); //创建子元素
Element age=linkman.addElement("age");
name.setText("陈瑞银"); //设置name节点的内容
age.setText("22"); //设置age节点的内容
OutputFormat format=OutputFormat.createPrettyPrint(); //指定输出格式
format.setEncoding("UTF-8"); //指定输出编码
try {
XMLWriter w=new XMLWriter(new FileOutputStream(f),format); //输出文件
w.write(docu); //输出内容
w.close();
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}Voyez maintenant si le document est généré, comme indiqué sur l'image
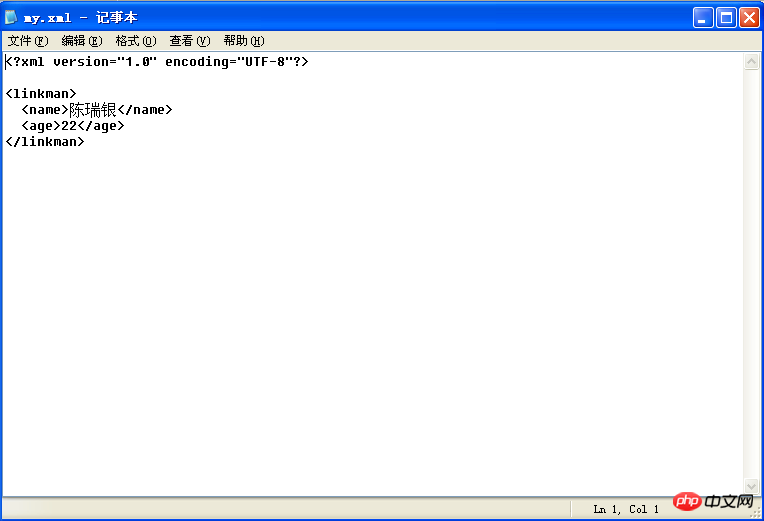
Le document est généré est relativement simple. Il en va de même pour la génération de documents complexes. Analysons ce XML.
Le code est le suivant
package org.lxh;
import java.io.File;
import java.util.Iterator;
import org.dom4j.*;
import org.dom4j.io.SAXReader;
public class ReadXml {
public static void main(String[] args) {
File f=new File("d:"+File.separator+"my.xml");
SAXReader read=new SAXReader(); //建立SAX解析读取
Document document=null;
try {
document=read.read(f); //读取文档
Element root=document.getRootElement(); //取得根元素
//下面给注释的部分用于解析复杂的xml(3层或以上)
/*Iterator it=root.elementIterator(); //取得全部子节点
while(it.hasNext())
{
/*Element e=(Element)it.next();
System.out.println(e.elementText("name")); //取得文本元素
System.out.println(e.elementText("age"));
}*/
System.out.println(root.elementText("age"));
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
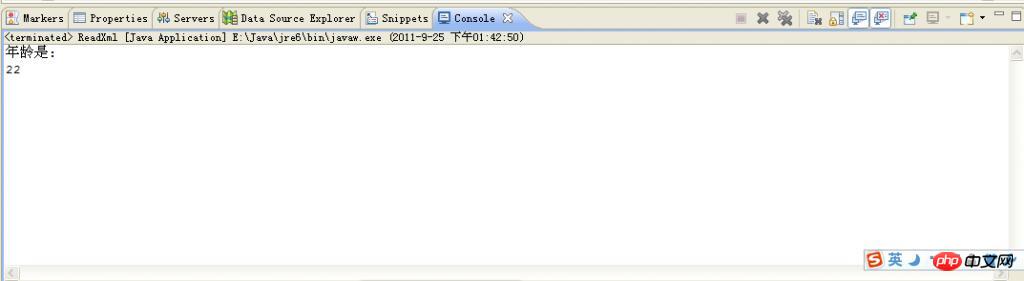
}Ce qui suit est une capture d'écran de l'effet en cours
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!